 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse engineering recurrent networks for sentiment classification reveals line attractor dynamics
Jun 25, 2019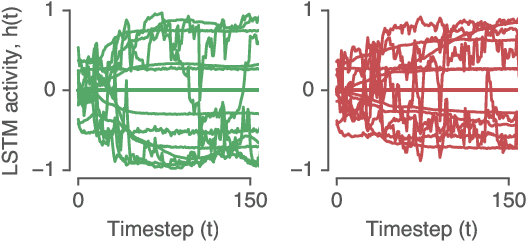
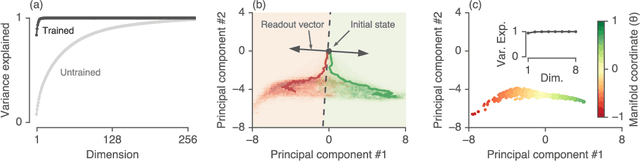
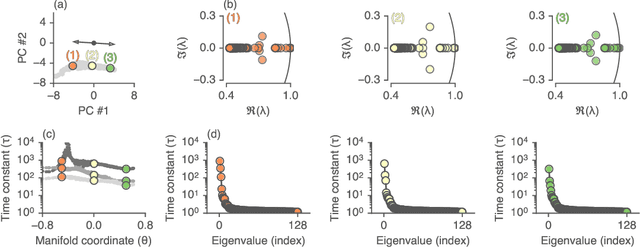
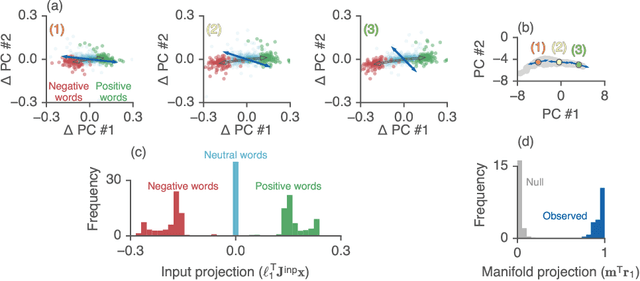
Recurrent neural networks (RNNs) are a widely used tool for modeling sequential data, yet they are often treated as inscrutable black boxes. Given a trained recurrent network, we would like to reverse engineer it--to obtain a quantitative, interpretable description of how it solves a particular task. Even for simple tasks, a detailed understanding of how recurrent networks work, or a prescription for how to develop such an understanding, remains elusive. In this work, we use tools from dynamical systems analysis to reverse engineer recurrent networks trained to perform sentiment classification, a foundational natural language processing task. Given a trained network, we find fixed points of the recurrent dynamics and linearize the nonlinear system around these fixed points. Despite their theoretical capacity to implement complex, high-dimensional computations, we find that trained networks converge to highly interpretable, low-dimensional representations. In particular, the topological structure of the fixed points and corresponding linearized dynamics reveal an approximate line attractor within the RNN, which we can use to quantitatively understand how the RNN solves the sentiment analysis task. Finally, we find this mechanism present across RNN architectures (including LSTMs, GRUs, and vanilla RNNs) trained on multiple datasets, suggesting that our findings are not unique to a particular architecture or dataset. Overall, these results demonstrate that surprisingly universal and human interpretable computations can arise across a range of recurrent networks.
A Unified Theory of Early Visual Representations from Retina to Cortex through Anatomically Constrained Deep CNNs
Jan 03, 2019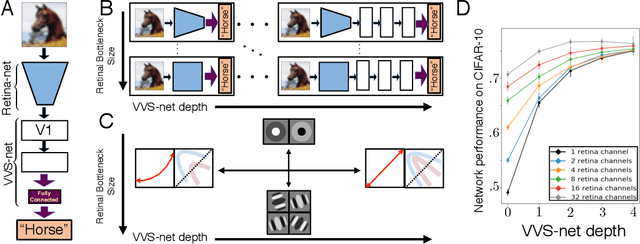
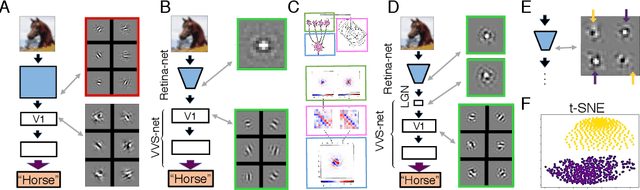
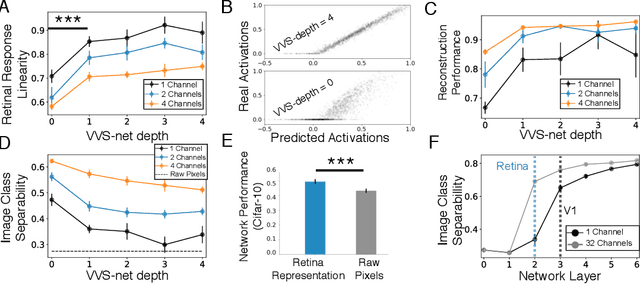
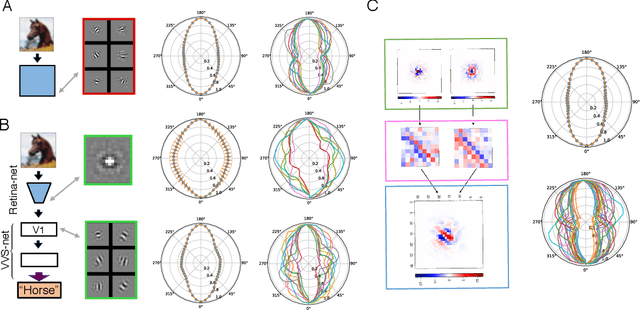
The visual system is hierarchically organized to process visual information in successive stages. Neural representations vary drastically across the first stages of visual processing: at the output of the retina, ganglion cell receptive fields (RFs) exhibit a clear antagonistic center-surround structure, whereas in the primary visual cortex, typical RFs are sharply tuned to a precise orientation. There is currently no unified theory explaining these differences in representations across layers. Here, using a deep convolutional neural network trained on image recognition as a model of the visual system, we show that such differences in representation can emerge as a direct consequence of different neural resource constraints on the retinal and cortical networks, and we find a single model from which both geometries spontaneously emerge at the appropriate stages of visual processing. The key constraint is a reduced number of neurons at the retinal output, consistent with the anatomy of the optic nerve as a stringent bottleneck. Second, we find that, for simple cortical networks, visual representations at the retinal output emerge as nonlinear and lossy feature detectors, whereas they emerge as linear and faithful encoders of the visual scene for more complex cortices. This result predicts that the retinas of small vertebrates should perform sophisticated nonlinear computations, extracting features directly relevant to behavior, whereas retinas of large animals such as primates should mostly encode the visual scene linearly and respond to a much broader range of stimuli. These predictions could reconcile the two seemingly incompatible views of the retina as either performing feature extraction or efficient coding of natural scenes, by suggesting that all vertebrates lie on a spectrum between these two objectives, depending on the degree of neural resources allocated to their visual system.
Task-Driven Convolutional Recurrent Models of the Visual System
Oct 27, 2018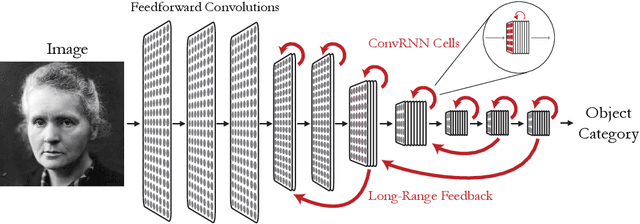
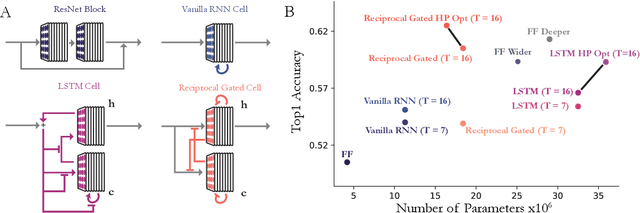
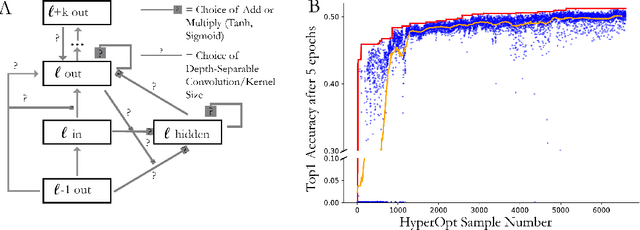
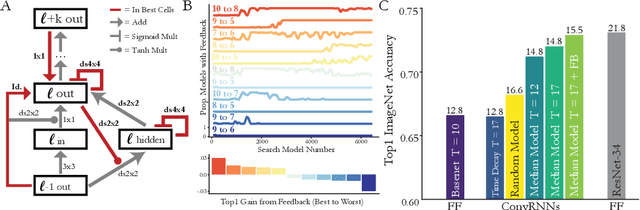
Feed-forward convolutional neural networks (CNNs) are currently state-of-the-art for object classification tasks such as ImageNet. Further, they are quantitatively accurate models of temporally-averaged responses of neurons in the primate brain's visual system. However, biological visual systems have two ubiquitous architectural features not shared with typical CNNs: local recurrence within cortical areas, and long-range feedback from downstream areas to upstream areas. Here we explored the role of recurrence in improving classification performance. We found that standard forms of recurrence (vanilla RNNs and LSTMs) do not perform well within deep CNNs on the ImageNet task. In contrast, novel cells that incorporated two structural features, bypassing and gating, were able to boost task accuracy substantially. We extended these design principles in an automated search over thousands of model architectures, which identified novel local recurrent cells and long-range feedback connections useful for object recognition. Moreover, these task-optimized ConvRNNs matched the dynamics of neural activity in the primate visual system better than feedforward networks, suggesting a role for the brain's recurrent connections in performing difficult visual behaviors.
A mathematical theory of semantic development in deep neural networks
Oct 23, 2018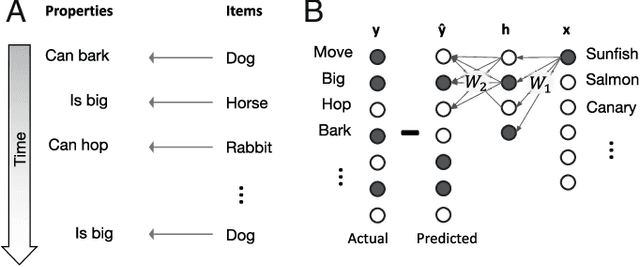
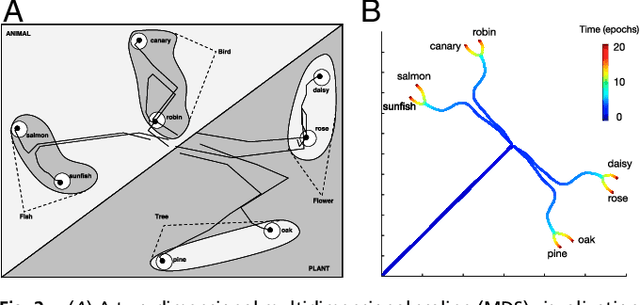
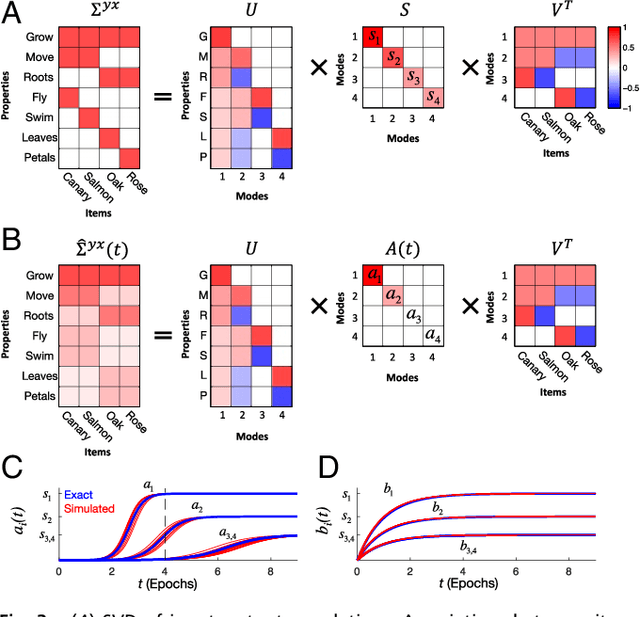
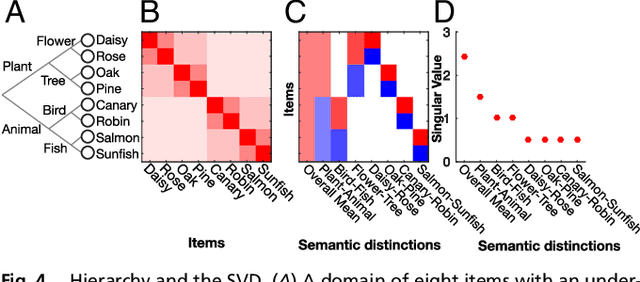
An extensive body of empirical research has revealed remarkable regularities in the acquisition, organization, deployment, and neural representation of human semantic knowledge, thereby raising a fundamental conceptual question: what are the theoretical principles governing the ability of neural networks to acquire, organize, and deploy abstract knowledge by integrating across many individual experiences? We address this question by mathematically analyzing the nonlinear dynamics of learning in deep linear networks. We find exact solutions to this learning dynamics that yield a conceptual explanation for the prevalence of many disparate phenomena in semantic cognition, including the hierarchical differentiation of concepts through rapid developmental transitions, the ubiquity of semantic illusions between such transitions, the emergence of item typicality and category coherence as factors controlling the speed of semantic processing, changing patterns of inductive projection over development, and the conservation of semantic similarity in neural representations across species. Thus, surprisingly, our simple neural model qualitatively recapitulates many diverse regularities underlying semantic development, while providing analytic insight into how the statistical structure of an environment can interact with nonlinear deep learning dynamics to give rise to these regularities.
Statistical mechanics of low-rank tensor decomposition
Oct 23, 2018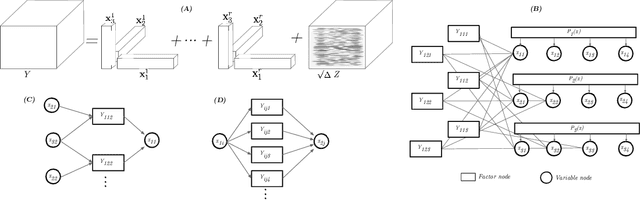
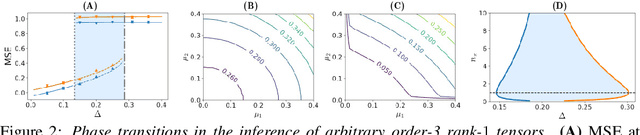
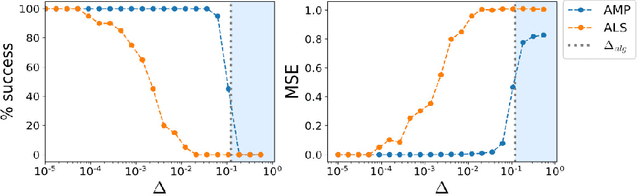
Often, large, high dimensional datasets collected across multiple modalities can be organized as a higher order tensor. Low-rank tensor decomposition then arises as a powerful and widely used tool to discover simple low dimensional structures underlying such data. However, we currently lack a theoretical understanding of the algorithmic behavior of low-rank tensor decompositions. We derive Bayesian approximate message passing (AMP) algorithms for recovering arbitrarily shaped low-rank tensors buried within noise, and we employ dynamic mean field theory to precisely characterize their performance. Our theory reveals the existence of phase transitions between easy, hard and impossible inference regimes, and displays an excellent match with simulations. Moreover, it reveals several qualitative surprises compared to the behavior of symmetric, cubic tensor decomposition. Finally, we compare our AMP algorithm to the most commonly used algorithm, alternating least squares (ALS), and demonstrate that AMP significantly outperforms ALS in the presence of noise.
An analytic theory of generalization dynamics and transfer learning in deep linear networks
Sep 27, 2018
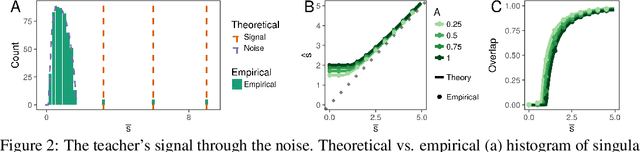
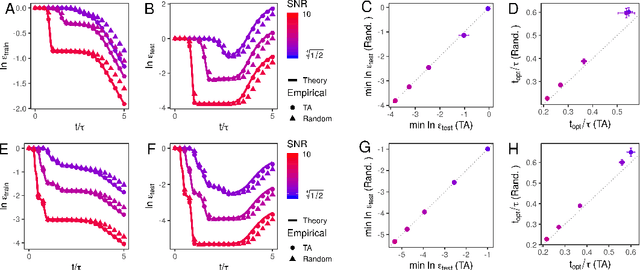
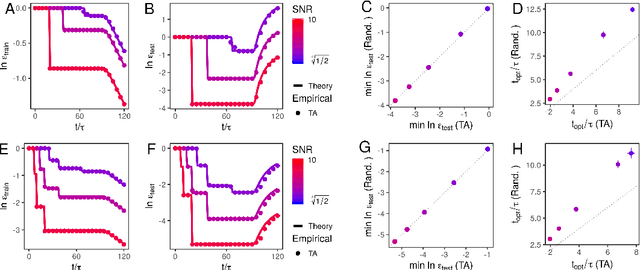
Much attention has been devoted recently to the generalization puzzle in deep learning: large, deep networks can generalize well, but existing theories bounding generalization error are exceedingly loose, and thus cannot explain this striking performance. Furthermore, a major hope is that knowledge may transfer across tasks, so that multi-task learning can improve generalization on individual tasks. However we lack analytic theories that can quantitatively predict how the degree of knowledge transfer depends on the relationship between the tasks. We develop an analytic theory of the nonlinear dynamics of generalization in deep linear networks, both within and across tasks. In particular, our theory provides analytic solutions to the training and testing error of deep networks as a function of training time, number of examples, network size and initialization, and the task structure and SNR. Our theory reveals that deep networks progressively learn the most important task structure first, so that generalization error at the early stopping time primarily depends on task structure and is independent of network size. This suggests any tight bound on generalization error must take into account task structure, and explains observations about real data being learned faster than random data. Intriguingly our theory also reveals the existence of a learning algorithm that proveably out-performs neural network training through gradient descent. Finally, for transfer learning, our theory reveals that knowledge transfer depends sensitively, but computably, on the SNRs and input feature alignments of pairs of tasks.
The Emergence of Spectral Universality in Deep Networks
Feb 27, 2018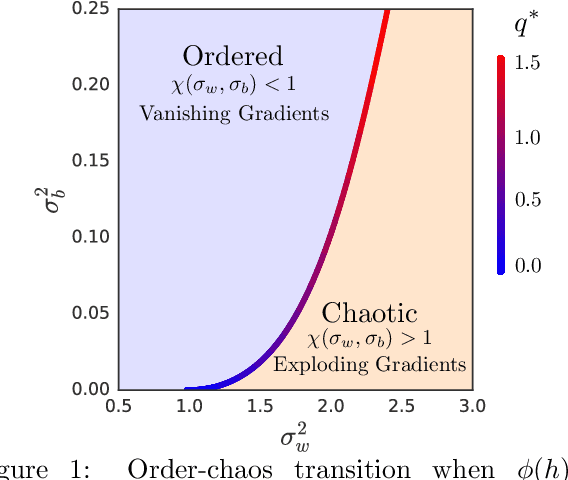

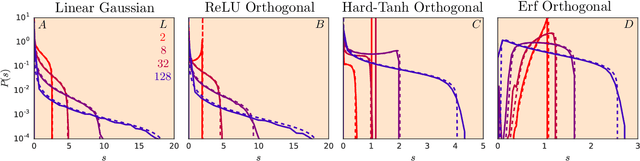
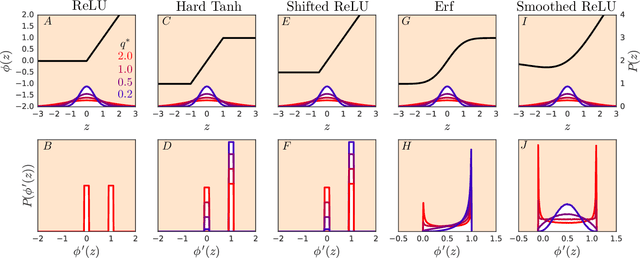
Recent work has shown that tight concentration of the entire spectrum of singular values of a deep network's input-output Jacobian around one at initialization can speed up learning by orders of magnitude. Therefore, to guide important design choices, it is important to build a full theoretical understanding of the spectra of Jacobians at initialization. To this end, we leverage powerful tools from free probability theory to provide a detailed analytic understanding of how a deep network's Jacobian spectrum depends on various hyperparameters including the nonlinearity, the weight and bias distributions, and the depth. For a variety of nonlinearities, our work reveals the emergence of new universal limiting spectral distributions that remain concentrated around one even as the depth goes to infinity.
Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice
Nov 13, 2017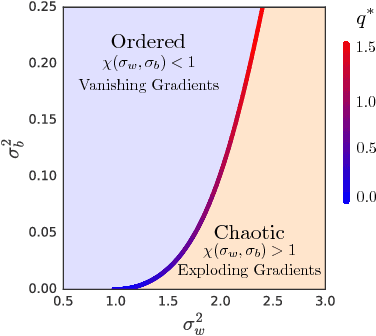
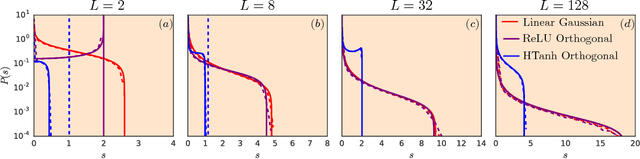
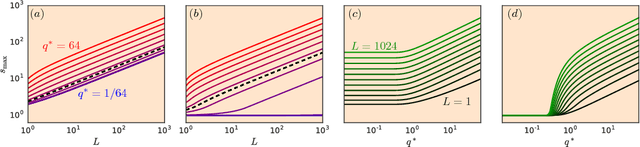
It is well known that the initialization of weights in deep neural networks can have a dramatic impact on learning speed. For example, ensuring the mean squared singular value of a network's input-output Jacobian is $O(1)$ is essential for avoiding the exponential vanishing or explosion of gradients. The stronger condition that all singular values of the Jacobian concentrate near $1$ is a property known as dynamical isometry. For deep linear networks, dynamical isometry can be achieved through orthogonal weight initialization and has been shown to dramatically speed up learning; however, it has remained unclear how to extend these results to the nonlinear setting. We address this question by employing powerful tools from free probability theory to compute analytically the entire singular value distribution of a deep network's input-output Jacobian. We explore the dependence of the singular value distribution on the depth of the network, the weight initialization, and the choice of nonlinearity. Intriguingly, we find that ReLU networks are incapable of dynamical isometry. On the other hand, sigmoidal networks can achieve isometry, but only with orthogonal weight initialization. Moreover, we demonstrate empirically that deep nonlinear networks achieving dynamical isometry learn orders of magnitude faster than networks that do not. Indeed, we show that properly-initialized deep sigmoidal networks consistently outperform deep ReLU networks. Overall, our analysis reveals that controlling the entire distribution of Jacobian singular values is an important design consideration in deep learning.
Variational Walkback: Learning a Transition Operator as a Stochastic Recurrent Net
Nov 07, 2017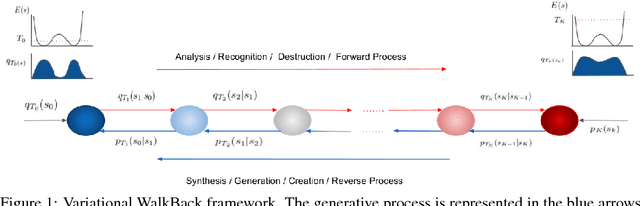

We propose a novel method to directly learn a stochastic transition operator whose repeated application provides generated samples. Traditional undirected graphical models approach this problem indirectly by learning a Markov chain model whose stationary distribution obeys detailed balance with respect to a parameterized energy function. The energy function is then modified so the model and data distributions match, with no guarantee on the number of steps required for the Markov chain to converge. Moreover, the detailed balance condition is highly restrictive: energy based models corresponding to neural networks must have symmetric weights, unlike biological neural circuits. In contrast, we develop a method for directly learning arbitrarily parameterized transition operators capable of expressing non-equilibrium stationary distributions that violate detailed balance, thereby enabling us to learn more biologically plausible asymmetric neural networks and more general non-energy based dynamical systems. The proposed training objective, which we derive via principled variational methods, encourages the transition operator to "walk back" in multi-step trajectories that start at data-points, as quickly as possible back to the original data points. We present a series of experimental results illustrating the soundness of the proposed approach, Variational Walkback (VW), on the MNIST, CIFAR-10, SVHN and CelebA datasets, demonstrating superior samples compared to earlier attempts to learn a transition operator. We also show that although each rapid training trajectory is limited to a finite but variable number of steps, our transition operator continues to generate good samples well past the length of such trajectories, thereby demonstrating the match of its non-equilibrium stationary distribution to the data distribution. Source Code: http://github.com/anirudh9119/walkback_nips17
SuperSpike: Supervised learning in multi-layer spiking neural networks
Oct 14, 2017A vast majority of computation in the brain is performed by spiking neural networks. Despite the ubiquity of such spiking, we currently lack an understanding of how biological spiking neural circuits learn and compute in-vivo, as well as how we can instantiate such capabilities in artificial spiking circuits in-silico. Here we revisit the problem of supervised learning in temporally coding multi-layer spiking neural networks. First, by using a surrogate gradient approach, we derive SuperSpike, a nonlinear voltage-based three factor learning rule capable of training multi-layer networks of deterministic integrate-and-fire neurons to perform nonlinear computations on spatiotemporal spike patterns. Second, inspired by recent results on feedback alignment, we compare the performance of our learning rule under different credit assignment strategies for propagating output errors to hidden units. Specifically, we test uniform, symmetric and random feedback, finding that simpler tasks can be solved with any type of feedback, while more complex tasks require symmetric feedback. In summary, our results open the door to obtaining a better scientific understanding of learning and computation in spiking neural networks by advancing our ability to train them to solve nonlinear problems involving transformations between different spatiotemporal spike-time patterns.