 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILOT: Steering Synthetic Data Generation with Psychological & Linguistic Output Targeting
Sep 18, 2025Generative AI applications commonly leverage user personas as a steering mechanism for synthetic data generation, but reliance on natural language representations forces models to make unintended inferences about which attributes to emphasize, limiting precise control over outputs. We introduce PILOT (Psychological and Linguistic Output Targeting), a two-phase framework for steering large language models with structured psycholinguistic profiles. In Phase 1, PILOT translates natural language persona descriptions into multidimensional profiles with normalized scores across linguistic and psychological dimensions. In Phase 2, these profiles guide generation along measurable axes of variation. We evaluate PILOT across three state-of-the-art LLMs (Mistral Large 2, Deepseek-R1, LLaMA 3.3 70B) using 25 synthetic personas under three conditions: Natural-language Persona Steering (NPS), Schema-Based Steering (SBS), and Hybrid Persona-Schema Steering (HPS). Results demonstrate that schema-based approaches significantly reduce artificial-sounding persona repetition while improving output coherence, with silhouette scores increasing from 0.098 to 0.237 and topic purity from 0.773 to 0.957. Our analysis reveals a fundamental trade-off: SBS produces more concise outputs with higher topical consistency, while NPS offers greater lexical diversity but reduced predictability. HPS achieves a balance between these extremes, maintaining output variety while preserving structural consistency. Expert linguistic evaluation confirms that PILOT maintains high response quality across all conditions, with no statistically significant differences between steering approaches.
Reverse engineering recurrent networks for sentiment classification reveals line attractor dynamics
Jun 25, 2019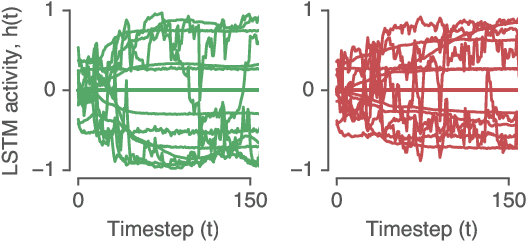
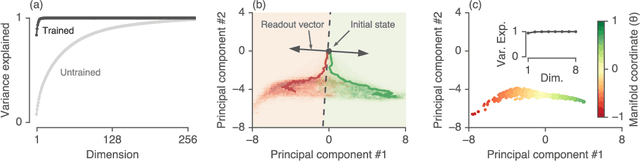
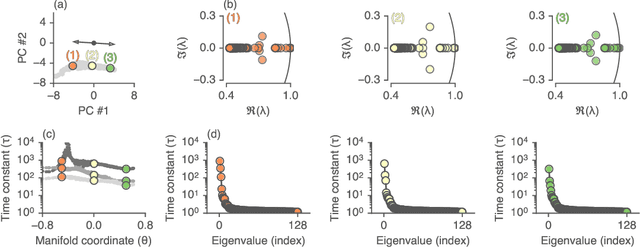
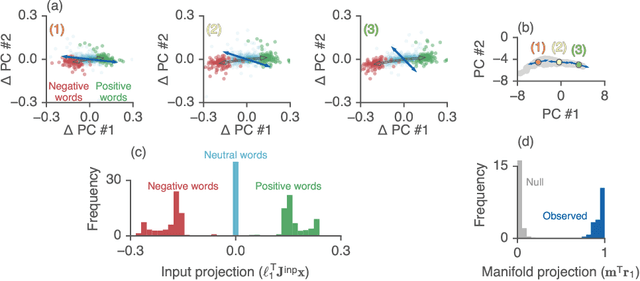
Recurrent neural networks (RNNs) are a widely used tool for modeling sequential data, yet they are often treated as inscrutable black boxes. Given a trained recurrent network, we would like to reverse engineer it--to obtain a quantitative, interpretable description of how it solves a particular task. Even for simple tasks, a detailed understanding of how recurrent networks work, or a prescription for how to develop such an understanding, remains elusive. In this work, we use tools from dynamical systems analysis to reverse engineer recurrent networks trained to perform sentiment classification, a foundational natural language processing task. Given a trained network, we find fixed points of the recurrent dynamics and linearize the nonlinear system around these fixed points. Despite their theoretical capacity to implement complex, high-dimensional computations, we find that trained networks converge to highly interpretable, low-dimensional representations. In particular, the topological structure of the fixed points and corresponding linearized dynamics reveal an approximate line attractor within the RNN, which we can use to quantitatively understand how the RNN solves the sentiment analysis task. Finally, we find this mechanism present across RNN architectures (including LSTMs, GRUs, and vanilla RNNs) trained on multiple datasets, suggesting that our findings are not unique to a particular architecture or dataset. Overall, these results demonstrate that surprisingly universal and human interpretable computations can arise across a range of recurrent networks.