 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-enabled Analysis-Through-Synthesis for ISAR Imaging of Small Everyday Objects with Sparse and Noisy UWB Radar Data
Oct 14, 2024



Inverse Synthetic Aperture Radar (ISAR) imaging presents a formidable challenge when it comes to small everyday objects due to their limited Radar Cross-Section (RCS) and the inherent resolution constraints of radar systems. Existing ISAR reconstruction methods including backprojection (BP) often require complex setups and controlled environments, rendering them impractical for many real-world noisy scenarios. In this paper, we propose a novel Analysis-through-Synthesis (ATS) framework enabled by Neural Radiance Fields (NeRF) for high-resolution coherent ISAR imaging of small objects using sparse and noisy Ultra-Wideband (UWB) radar data with an inexpensive and portable setup. Our end-to-end framework integrates ultra-wideband radar wave propagation, reflection characteristics, and scene priors, enabling efficient 2D scene reconstruction without the need for costly anechoic chambers or complex measurement test beds. With qualitative and quantitative comparisons, we demonstrate that the proposed method outperforms traditional techniques and generates ISAR images of complex scenes with multiple targets and complex structures in Non-Line-of-Sight (NLOS) and noisy scenarios, particularly with limited number of views and sparse UWB radar scans. This work represents a significant step towards practical, cost-effective ISAR imaging of small everyday objects, with broad implications for robotics and mobile sensing applications.
Turbulence Strength $C_n^2$ Estimation from Video using Physics-based Deep Learning
Aug 29, 2024



Images captured from a long distance suffer from dynamic image distortion due to turbulent flow of air cells with random temperatures, and thus refractive indices. This phenomenon, known as image dancing, is commonly characterized by its refractive-index structure constant $C_n^2$ as a measure of the turbulence strength. For many applications such as atmospheric forecast model, long-range/astronomy imaging, and aviation safety, optical communication technology, $C_n^2$ estimation is critical for accurately sensing the turbulent environment. Previous methods for $C_n^2$ estimation include estimation from meteorological data (temperature, relative humidity, wind shear, etc.) for single-point measurements, two-ended pathlength measurements from optical scintillometer for path-averaged $C_n^2$, and more recently estimating $C_n^2$ from passive video cameras for low cost and hardware complexity. In this paper, we present a comparative analysis of classical image gradient methods for $C_n^2$ estimation and modern deep learning-based methods leveraging convolutional neural networks. To enable this, we collect a dataset of video capture along with reference scintillometer measurements for ground truth, and we release this unique dataset to the scientific community. We observe that deep learning methods can achieve higher accuracy when trained on similar data, but suffer from generalization errors to other, unseen imagery as compared to classical methods. To overcome this trade-off, we present a novel physics-based network architecture that combines learned convolutional layers with a differentiable image gradient method that maintains high accuracy while being generalizable across image datasets.
* Code Available: https://github.com/Riponcs/Cn2Estimation
Turb-Seg-Res: A Segment-then-Restore Pipeline for Dynamic Videos with Atmospheric Turbulence
Apr 21, 2024



Tackling image degradation due to atmospheric turbulence, particularly in dynamic environment, remains a challenge for long-range imaging systems. Existing techniques have been primarily designed for static scenes or scenes with small motion. This paper presents the first segment-then-restore pipeline for restoring the videos of dynamic scenes in turbulent environment. We leverage mean optical flow with an unsupervised motion segmentation method to separate dynamic and static scene components prior to restoration. After camera shake compensation and segmentation, we introduce foreground/background enhancement leveraging the statistics of turbulence strength and a transformer model trained on a novel noise-based procedural turbulence generator for fast dataset augmentation. Benchmarked against existing restoration methods, our approach restores most of the geometric distortion and enhances sharpness for videos. We make our code, simulator, and data publicly available to advance the field of video restoration from turbulence: riponcs.github.io/TurbSegRes
PathFinder: Attention-Driven Dynamic Non-Line-of-Sight Tracking with a Mobile Robot
Apr 07, 2024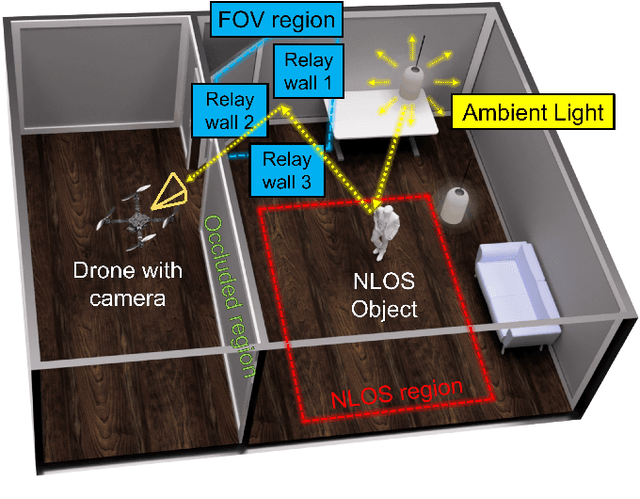
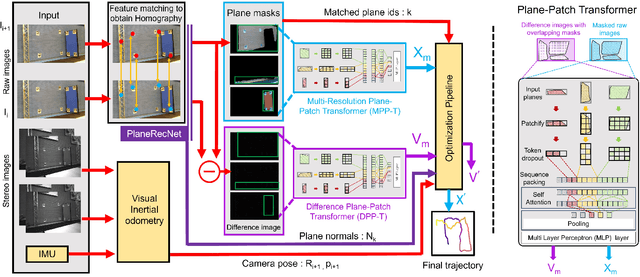

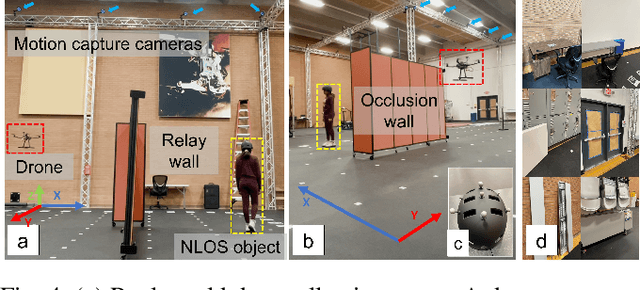
The study of non-line-of-sight (NLOS) imaging is growing due to its many potential applications, including rescue operations and pedestrian detection by self-driving cars. However, implementing NLOS imaging on a moving camera remains an open area of research. Existing NLOS imaging methods rely on time-resolved detectors and laser configurations that require precise optical alignment, making it difficult to deploy them in dynamic environments. This work proposes a data-driven approach to NLOS imaging, PathFinder, that can be used with a standard RGB camera mounted on a small, power-constrained mobile robot, such as an aerial drone. Our experimental pipeline is designed to accurately estimate the 2D trajectory of a person who moves in a Manhattan-world environment while remaining hidden from the camera's field-of-view. We introduce a novel approach to process a sequence of dynamic successive frames in a line-of-sight (LOS) video using an attention-based neural network that performs inference in real-time. The method also includes a preprocessing selection metric that analyzes images from a moving camera which contain multiple vertical planar surfaces, such as walls and building facades, and extracts planes that return maximum NLOS information. We validate the approach on in-the-wild scenes using a drone for video capture, thus demonstrating low-cost NLOS imaging in dynamic capture environments.
Z-Splat: Z-Axis Gaussian Splatting for Camera-Sonar Fusion
Apr 06, 2024



Differentiable 3D-Gaussian splatting (GS) is emerging as a prominent technique in computer vision and graphics for reconstructing 3D scenes. GS represents a scene as a set of 3D Gaussians with varying opacities and employs a computationally efficient splatting operation along with analytical derivatives to compute the 3D Gaussian parameters given scene images captured from various viewpoints. Unfortunately, capturing surround view ($360^{\circ}$ viewpoint) images is impossible or impractical in many real-world imaging scenarios, including underwater imaging, rooms inside a building, and autonomous navigation. In these restricted baseline imaging scenarios, the GS algorithm suffers from a well-known 'missing cone' problem, which results in poor reconstruction along the depth axis. In this manuscript, we demonstrate that using transient data (from sonars) allows us to address the missing cone problem by sampling high-frequency data along the depth axis. We extend the Gaussian splatting algorithms for two commonly used sonars and propose fusion algorithms that simultaneously utilize RGB camera data and sonar data. Through simulations, emulations, and hardware experiments across various imaging scenarios, we show that the proposed fusion algorithms lead to significantly better novel view synthesis (5 dB improvement in PSNR) and 3D geometry reconstruction (60% lower Chamfer distance).
Unsupervised Region-Growing Network for Object Segmentation in Atmospheric Turbulence
Nov 06, 2023



In this paper, we present a two-stage unsupervised foreground object segmentation network tailored for dynamic scenes affected by atmospheric turbulence. In the first stage, we utilize averaged optical flow from turbulence-distorted image sequences to feed a novel region-growing algorithm, crafting preliminary masks for each moving object in the video. In the second stage, we employ a U-Net architecture with consistency and grouping losses to further refine these masks optimizing their spatio-temporal alignment. Our approach does not require labeled training data and works across varied turbulence strengths for long-range video. Furthermore, we release the first moving object segmentation dataset of turbulence-affected videos, complete with manually annotated ground truth masks. Our method, evaluated on this new dataset, demonstrates superior segmentation accuracy and robustness as compared to current state-of-the-art unsupervised methods.
Learning Repeatable Speech Embeddings Using An Intra-class Correlation Regularizer
Oct 25, 2023



A good supervised embedding for a specific machine learning task is only sensitive to changes in the label of interest and is invariant to other confounding factors. We leverage the concept of repeatability from measurement theory to describe this property and propose to use the intra-class correlation coefficient (ICC) to evaluate the repeatability of embeddings. We then propose a novel regularizer, the ICC regularizer, as a complementary component for contrastive losses to guide deep neural networks to produce embeddings with higher repeatability. We use simulated data to explain why the ICC regularizer works better on minimizing the intra-class variance than the contrastive loss alone. We implement the ICC regularizer and apply it to three speech tasks: speaker verification, voice style conversion, and a clinical application for detecting dysphonic voice. The experimental results demonstrate that adding an ICC regularizer can improve the repeatability of learned embeddings compared to only using the contrastive loss; further, these embeddings lead to improved performance in these downstream tasks.
Neural Volumetric Reconstruction for Coherent Synthetic Aperture Sonar
Jun 16, 2023Synthetic aperture sonar (SAS) measures a scene from multiple views in order to increase the resolution of reconstructed imagery. Image reconstruction methods for SAS coherently combine measurements to focus acoustic energy onto the scene. However, image formation is typically under-constrained due to a limited number of measurements and bandlimited hardware, which limits the capabilities of existing reconstruction methods. To help meet these challenges, we design an analysis-by-synthesis optimization that leverages recent advances in neural rendering to perform coherent SAS imaging. Our optimization enables us to incorporate physics-based constraints and scene priors into the image formation process. We validate our method on simulation and experimental results captured in both air and water. We demonstrate both quantitatively and qualitatively that our method typically produces superior reconstructions than existing approaches. We share code and data for reproducibility.
Eulerian Phase-based Motion Magnification for High-Fidelity Vital Sign Estimation with Radar in Clinical Settings
Dec 03, 2022



Efficient and accurate detection of subtle motion generated from small objects in noisy environments, as needed for vital sign monitoring, is challenging, but can be substantially improved with magnification. We developed a complex Gabor filter-based decomposition method to amplify phases at different spatial wavelength levels to magnify motion and extract 1D motion signals for fundamental frequency estimation. The phase-based complex Gabor filter outputs are processed and then used to train machine learning models that predict respiration and heart rate with greater accuracy. We show that our proposed technique performs better than the conventional temporal FFT-based method in clinical settings, such as sleep laboratories and emergency departments, as well for a variety of human postures.
Towards Live 3D Reconstruction from Wearable Video: An Evaluation of V-SLAM, NeRF, and Videogrammetry Techniques
Nov 21, 2022



Mixed reality (MR) is a key technology which promises to change the future of warfare. An MR hybrid of physical outdoor environments and virtual military training will enable engagements with long distance enemies, both real and simulated. To enable this technology, a large-scale 3D model of a physical environment must be maintained based on live sensor observations. 3D reconstruction algorithms should utilize the low cost and pervasiveness of video camera sensors, from both overhead and soldier-level perspectives. Mapping speed and 3D quality can be balanced to enable live MR training in dynamic environments. Given these requirements, we survey several 3D reconstruction algorithms for large-scale mapping for military applications given only live video. We measure 3D reconstruction performance from common structure from motion, visual-SLAM, and photogrammetry techniques. This includes the open source algorithms COLMAP, ORB-SLAM3, and NeRF using Instant-NGP. We utilize the autonomous driving academic benchmark KITTI, which includes both dashboard camera video and lidar produced 3D ground truth. With the KITTI data, our primary contribution is a quantitative evaluation of 3D reconstruction computational speed when considering live video.