 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Knowledge Distillation for Model Interpretability
May 25, 2023



Several recent studies have elucidated why knowledge distillation (KD) improves model performance. However, few have researched the other advantages of KD in addition to its improving model performance. In this study, we have attempted to show that KD enhances the interpretability as well as the accuracy of models. We measured the number of concept detectors identified in network dissection for a quantitative comparison of model interpretability. We attributed the improvement in interpretability to the class-similarity information transferred from the teacher to student models. First, we confirmed the transfer of class-similarity information from the teacher to student model via logit distillation. Then, we analyzed how class-similarity information affects model interpretability in terms of its presence or absence and degree of similarity information. We conducted various quantitative and qualitative experiments and examined the results on different datasets, different KD methods, and according to different measures of interpretability. Our research showed that KD models by large models could be used more reliably in various fields.
Edit-A-Video: Single Video Editing with Object-Aware Consistency
Apr 01, 2023



Despite the fact that text-to-video (TTV) model has recently achieved remarkable success, there have been few approaches on TTV for its extension to video editing. Motivated by approaches on TTV models adapting from diffusion-based text-to-image (TTI) models, we suggest the video editing framework given only a pretrained TTI model and a single <text, video> pair, which we term Edit-A-Video. The framework consists of two stages: (1) inflating the 2D model into the 3D model by appending temporal modules and tuning on the source video (2) inverting the source video into the noise and editing with target text prompt and attention map injection. Each stage enables the temporal modeling and preservation of semantic attributes of the source video. One of the key challenges for video editing include a background inconsistency problem, where the regions not included for the edit suffer from undesirable and inconsistent temporal alterations. To mitigate this issue, we also introduce a novel mask blending method, termed as sparse-causal blending (SC Blending). We improve previous mask blending methods to reflect the temporal consistency so that the area where the editing is applied exhibits smooth transition while also achieving spatio-temporal consistency of the unedited regions. We present extensive experimental results over various types of text and videos, and demonstrate the superiority of the proposed method compared to baselines in terms of background consistency, text alignment, and video editing quality.
Sample-efficient Adversarial Imitation Learning
Mar 14, 2023Imitation learning, in which learning is performed by demonstration, has been studied and advanced for sequential decision-making tasks in which a reward function is not predefined. However, imitation learning methods still require numerous expert demonstration samples to successfully imitate an expert's behavior. To improve sample efficiency, we utilize self-supervised representation learning, which can generate vast training signals from the given data. In this study, we propose a self-supervised representation-based adversarial imitation learning method to learn state and action representations that are robust to diverse distortions and temporally predictive, on non-image control tasks. In particular, in comparison with existing self-supervised learning methods for tabular data, we propose a different corruption method for state and action representations that is robust to diverse distortions. We theoretically and empirically observe that making an informative feature manifold with less sample complexity significantly improves the performance of imitation learning. The proposed method shows a 39% relative improvement over existing adversarial imitation learning methods on MuJoCo in a setting limited to 100 expert state-action pairs. Moreover, we conduct comprehensive ablations and additional experiments using demonstrations with varying optimality to provide insights into a range of factors.
New Insights for the Stability-Plasticity Dilemma in Online Continual Learning
Feb 17, 2023The aim of continual learning is to learn new tasks continuously (i.e., plasticity) without forgetting previously learned knowledge from old tasks (i.e., stability). In the scenario of online continual learning, wherein data comes strictly in a streaming manner, the plasticity of online continual learning is more vulnerable than offline continual learning because the training signal that can be obtained from a single data point is limited. To overcome the stability-plasticity dilemma in online continual learning, we propose an online continual learning framework named multi-scale feature adaptation network (MuFAN) that utilizes a richer context encoding extracted from different levels of a pre-trained network. Additionally, we introduce a novel structure-wise distillation loss and replace the commonly used batch normalization layer with a newly proposed stability-plasticity normalization module to train MuFAN that simultaneously maintains high plasticity and stability. MuFAN outperforms other state-of-the-art continual learning methods on the SVHN, CIFAR100, miniImageNet, and CORe50 datasets. Extensive experiments and ablation studies validate the significance and scalability of each proposed component: 1) multi-scale feature maps from a pre-trained encoder, 2) the structure-wise distillation loss, and 3) the stability-plasticity normalization module in MuFAN. Code is publicly available at https://github.com/whitesnowdrop/MuFAN.
FedClassAvg: Local Representation Learning for Personalized Federated Learning on Heterogeneous Neural Networks
Oct 27, 2022



Personalized federated learning is aimed at allowing numerous clients to train personalized models while participating in collaborative training in a communication-efficient manner without exchanging private data. However, many personalized federated learning algorithms assume that clients have the same neural network architecture, and those for heterogeneous models remain understudied. In this study, we propose a novel personalized federated learning method called federated classifier averaging (FedClassAvg). Deep neural networks for supervised learning tasks consist of feature extractor and classifier layers. FedClassAvg aggregates classifier weights as an agreement on decision boundaries on feature spaces so that clients with not independently and identically distributed (non-iid) data can learn about scarce labels. In addition, local feature representation learning is applied to stabilize the decision boundaries and improve the local feature extraction capabilities for clients. While the existing methods require the collection of auxiliary data or model weights to generate a counterpart, FedClassAvg only requires clients to communicate with a couple of fully connected layers, which is highly communication-efficient. Moreover, FedClassAvg does not require extra optimization problems such as knowledge transfer, which requires intensive computation overhead. We evaluated FedClassAvg through extensive experiments and demonstrated it outperforms the current state-of-the-art algorithms on heterogeneous personalized federated learning tasks.
E2V-SDE: From Asynchronous Events to Fast and Continuous Video Reconstruction via Neural Stochastic Differential Equations
Jun 15, 2022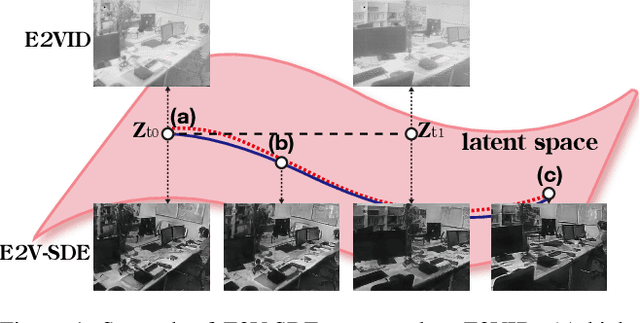
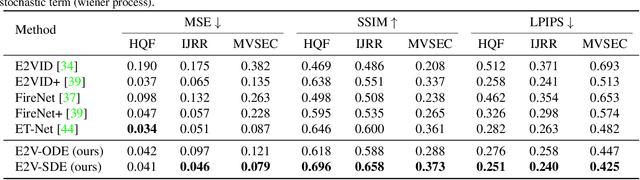
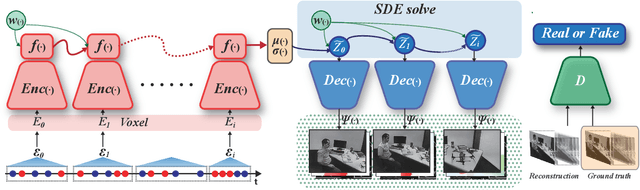
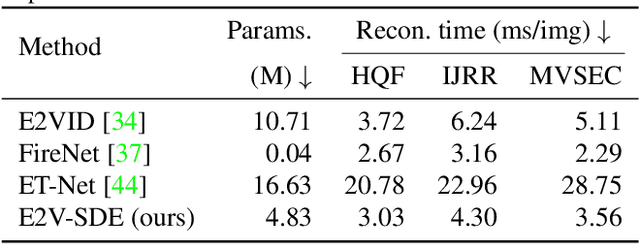
Event cameras respond to brightness changes in the scene asynchronously and independently for every pixel. Due to the properties, these cameras have distinct features: high dynamic range (HDR), high temporal resolution, and low power consumption. However, the results of event cameras should be processed into an alternative representation for computer vision tasks. Also, they are usually noisy and cause poor performance in areas with few events. In recent years, numerous researchers have attempted to reconstruct videos from events. However, they do not provide good quality videos due to a lack of temporal information from irregular and discontinuous data. To overcome these difficulties, we introduce an E2V-SDE whose dynamics are governed in a latent space by Stochastic differential equations (SDE). Therefore, E2V-SDE can rapidly reconstruct images at arbitrary time steps and make realistic predictions on unseen data. In addition, we successfully adopted a variety of image composition techniques for improving image clarity and temporal consistency. By conducting extensive experiments on simulated and real-scene datasets, we verify that our model outperforms state-of-the-art approaches under various video reconstruction settings. In terms of image quality, the LPIPS score improves by up to 12% and the reconstruction speed is 87% higher than that of ET-Net.
* 2022 CVPR oral
Confidence Score for Source-Free Unsupervised Domain Adaptation
Jun 14, 2022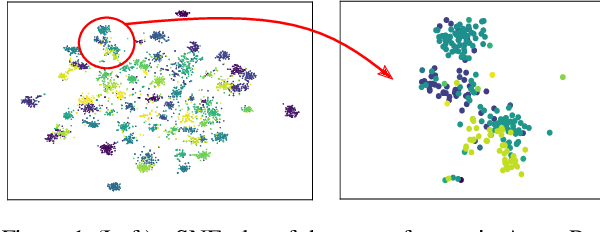
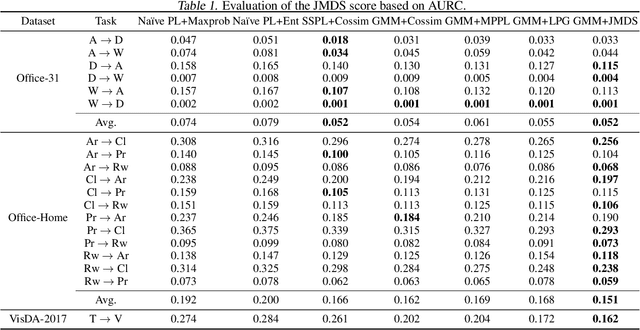
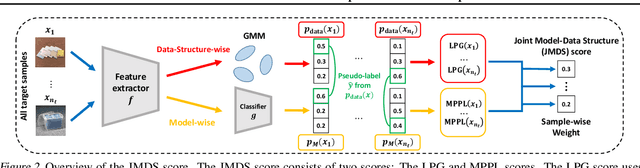
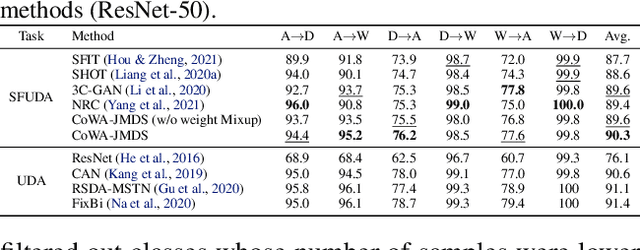
Source-free unsupervised domain adaptation (SFUDA) aims to obtain high performance in the unlabeled target domain using the pre-trained source model, not the source data. Existing SFUDA methods assign the same importance to all target samples, which is vulnerable to incorrect pseudo-labels. To differentiate between sample importance, in this study, we propose a novel sample-wise confidence score, the Joint Model-Data Structure (JMDS) score for SFUDA. Unlike existing confidence scores that use only one of the source or target domain knowledge, the JMDS score uses both knowledge. We then propose a Confidence score Weighting Adaptation using the JMDS (CoWA-JMDS) framework for SFUDA. CoWA-JMDS consists of the JMDS scores as sample weights and weight Mixup that is our proposed variant of Mixup. Weight Mixup promotes the model make more use of the target domain knowledge. The experimental results show that the JMDS score outperforms the existing confidence scores. Moreover, CoWA-JMDS achieves state-of-the-art performance on various SFUDA scenarios: closed, open, and partial-set scenarios.
Out of Sight, Out of Mind: A Source-View-Wise Feature Aggregation for Multi-View Image-Based Rendering
Jun 10, 2022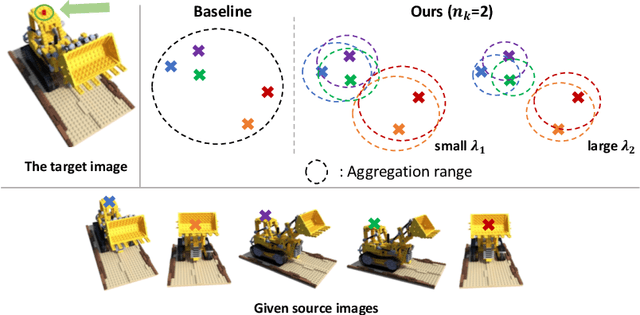
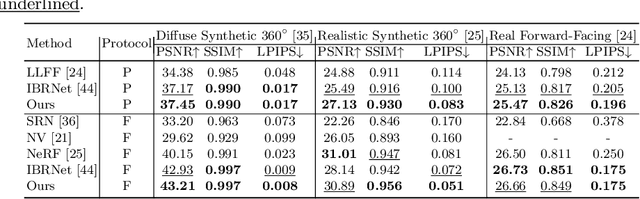
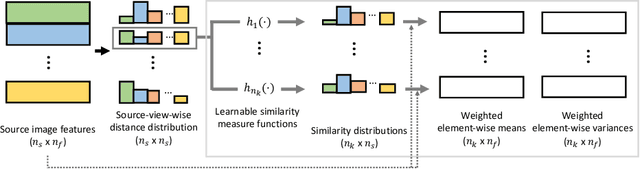

To estimate the volume density and color of a 3D point in the multi-view image-based rendering, a common approach is to inspect the consensus existence among the given source image features, which is one of the informative cues for the estimation procedure. To this end, most of the previous methods utilize equally-weighted aggregation features. However, this could make it hard to check the consensus existence when some outliers, which frequently occur by occlusions, are included in the source image feature set. In this paper, we propose a novel source-view-wise feature aggregation method, which facilitates us to find out the consensus in a robust way by leveraging local structures in the feature set. We first calculate the source-view-wise distance distribution for each source feature for the proposed aggregation. After that, the distance distribution is converted to several similarity distributions with the proposed learnable similarity mapping functions. Finally, for each element in the feature set, the aggregation features are extracted by calculating the weighted means and variances, where the weights are derived from the similarity distributions. In experiments, we validate the proposed method on various benchmark datasets, including synthetic and real image scenes. The experimental results demonstrate that incorporating the proposed features improves the performance by a large margin, resulting in the state-of-the-art performance.
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Jun 09, 2022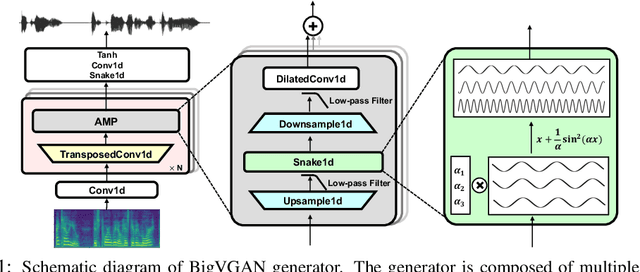

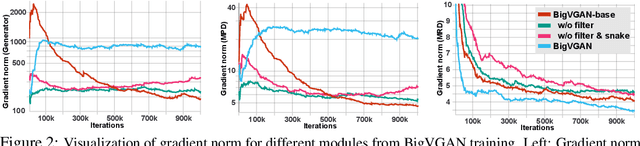

Despite recent progress in generative adversarial network(GAN)-based vocoders, where the model generates raw waveform conditioned on mel spectrogram, it is still challenging to synthesize high-fidelity audio for numerous speakers across varied recording environments. In this work, we present BigVGAN, a universal vocoder that generalizes well under various unseen conditions in zero-shot setting. We introduce periodic nonlinearities and anti-aliased representation into the generator, which brings the desired inductive bias for waveform synthesis and significantly improves audio quality. Based on our improved generator and the state-of-the-art discriminators, we train our GAN vocoder at the largest scale up to 112M parameters, which is unprecedented in the literature. In particular, we identify and address the training instabilities specific to such scale, while maintaining high-fidelity output without over-regularization. Our BigVGAN achieves the state-of-the-art zero-shot performance for various out-of-distribution scenarios, including new speakers, novel languages, singing voices, music and instrumental audio in unseen (even noisy) recording environments. We will release our code and model at: https://github.com/NVIDIA/BigVGAN
Guided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
May 30, 2022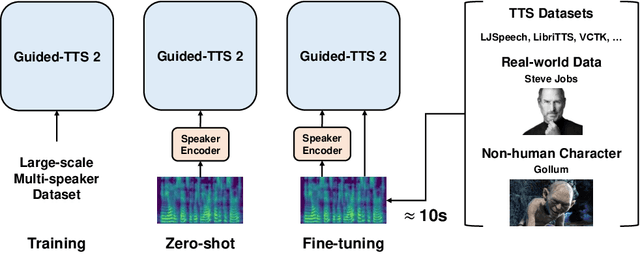
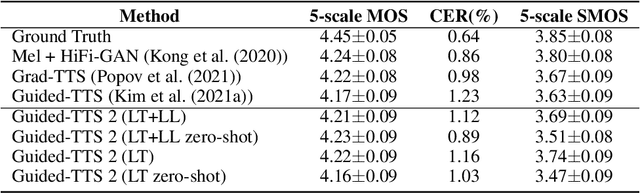
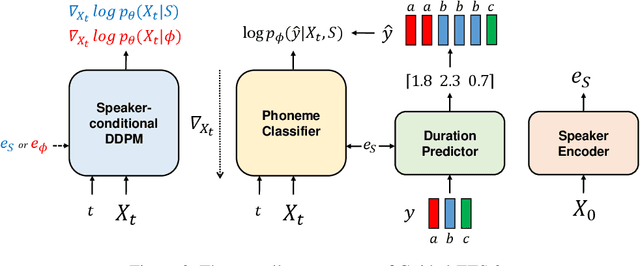
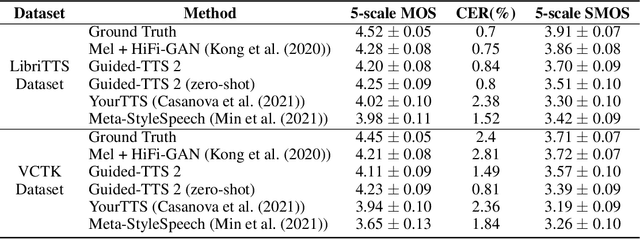
We propose Guided-TTS 2, a diffusion-based generative model for high-quality adaptive TTS using untranscribed data. Guided-TTS 2 combines a speaker-conditional diffusion model with a speaker-dependent phoneme classifier for adaptive text-to-speech. We train the speaker-conditional diffusion model on large-scale untranscribed datasets for a classifier-free guidance method and further fine-tune the diffusion model on the reference speech of the target speaker for adaptation, which only takes 40 seconds. We demonstrate that Guided-TTS 2 shows comparable performance to high-quality single-speaker TTS baselines in terms of speech quality and speaker similarity with only a ten-second untranscribed data. We further show that Guided-TTS 2 outperforms adaptive TTS baselines on multi-speaker datasets even with a zero-shot adaptation setting. Guided-TTS 2 can adapt to a wide range of voices only using untranscribed speech, which enables adaptive TTS with the voice of non-human characters such as Gollum in \textit{"The Lord of the Rings"}.