 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargetNet: Functional microRNA Target Prediction with Deep Neural Networks
Jul 23, 2021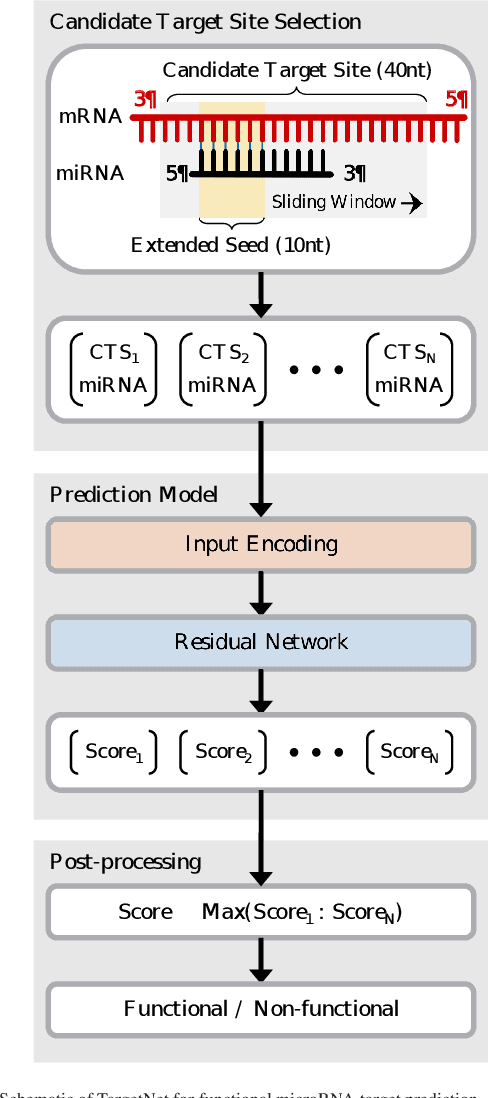
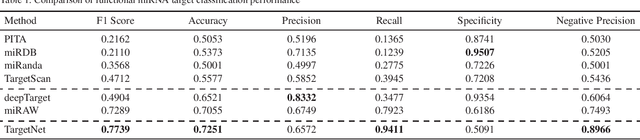
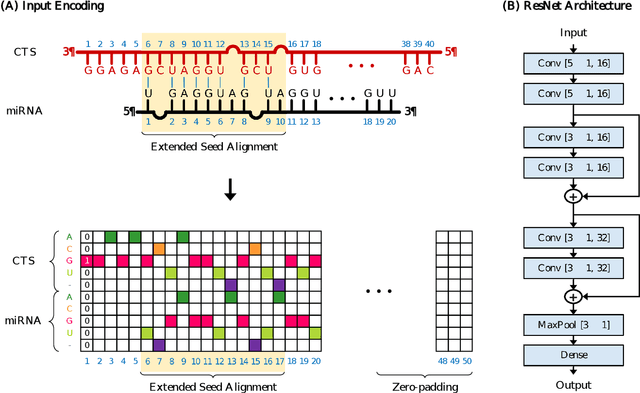
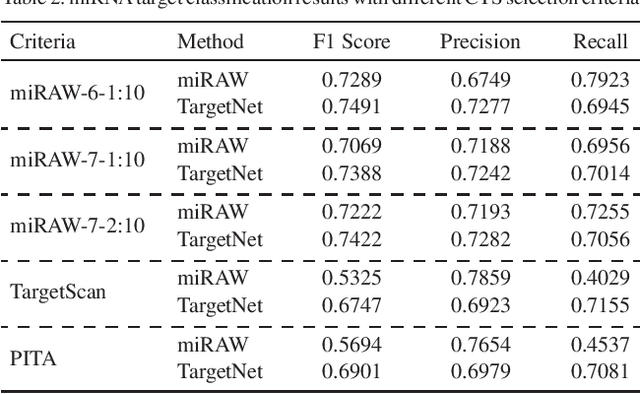
MicroRNAs (miRNAs) play pivotal roles in gene expression regulation by binding to target sites of messenger RNAs (mRNAs). While identifying functional targets of miRNAs is of utmost importance, their prediction remains a great challenge. Previous computational algorithms have major limitations. They use conservative candidate target site (CTS) selection criteria mainly focusing on canonical site types, rely on laborious and time-consuming manual feature extraction, and do not fully capitalize on the information underlying miRNA-CTS interactions. In this paper, we introduce TargetNet, a novel deep learning-based algorithm for functional miRNA target prediction. To address the limitations of previous approaches, TargetNet has three key components: (1) relaxed CTS selection criteria accommodating irregularities in the seed region, (2) a novel miRNA-CTS sequence encoding scheme incorporating extended seed region alignments, and (3) a deep residual network-based prediction model. The proposed model was trained with miRNA-CTS pair datasets and evaluated with miRNA-mRNA pair datasets. TargetNet advances the previous state-of-the-art algorithms used in functional miRNA target classification. Furthermore, it demonstrates great potential for distinguishing high-functional miRNA targets.
Geometry-aware Transformer for molecular property prediction
Jun 29, 2021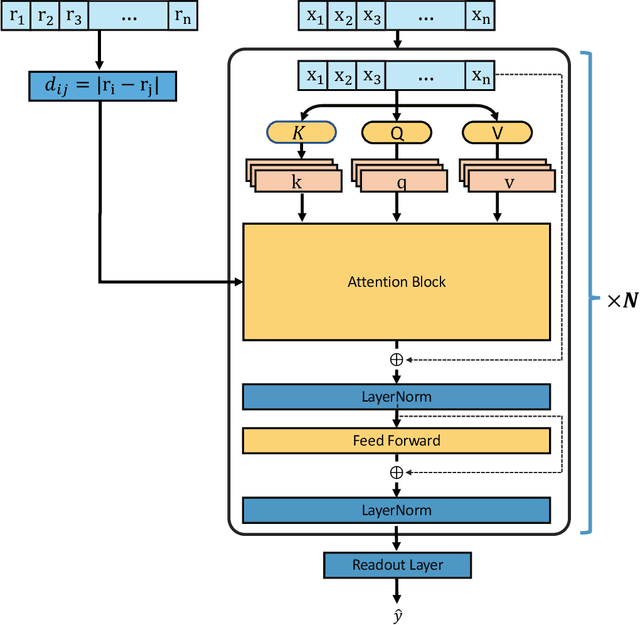
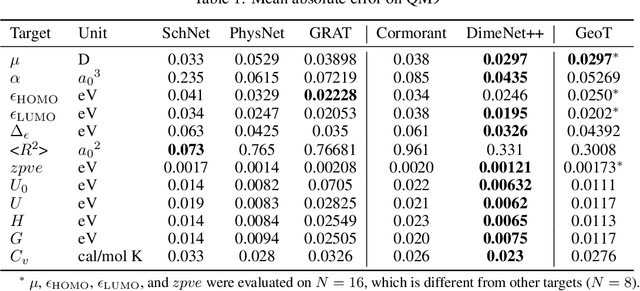
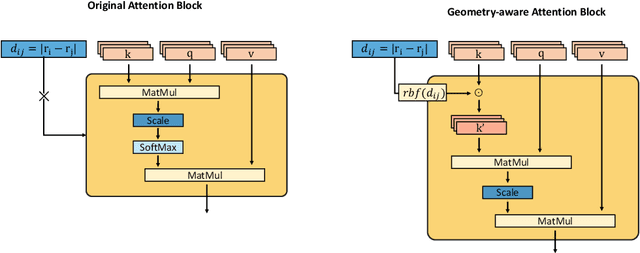
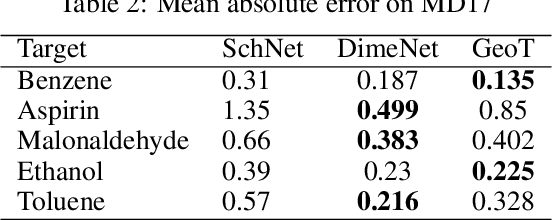
Recently, graph neural networks (GNNs) have achieved remarkable performances for quantum mechanical problems. However, a graph convolution can only cover a localized region, and cannot capture long-range interactions of atoms. This behavior is contrary to theoretical interatomic potentials, which is a fundamental limitation of the spatial based GNNs. In this work, we propose a novel attention-based framework for molecular property prediction tasks. We represent a molecular conformation as a discrete atomic sequence combined by atom-atom distance attributes, named Geometry-aware Transformer (GeoT). In particular, we adopt a Transformer architecture, which has been widely used for sequential data. Our proposed model trains sequential representations of molecular graphs based on globally constructed attentions, maintaining all spatial arrangements of atom pairs. Our method does not suffer from cost intensive computations, such as angle calculations. The experimental results on several public benchmarks and visualization maps verified that keeping the long-range interatomic attributes can significantly improve the model predictability.
Flexible dual-branched message passing neural network for quantum mechanical property prediction with molecular conformation
Jun 14, 2021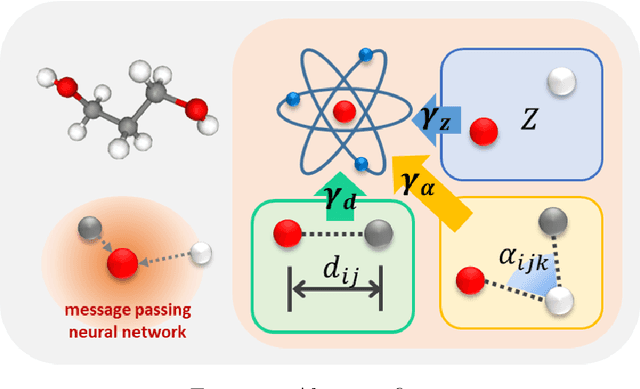
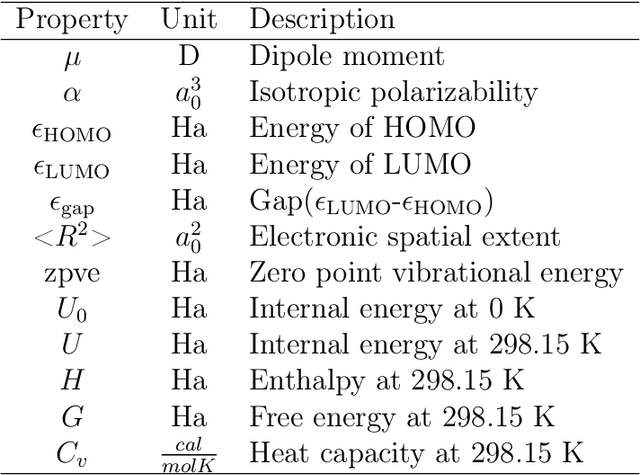
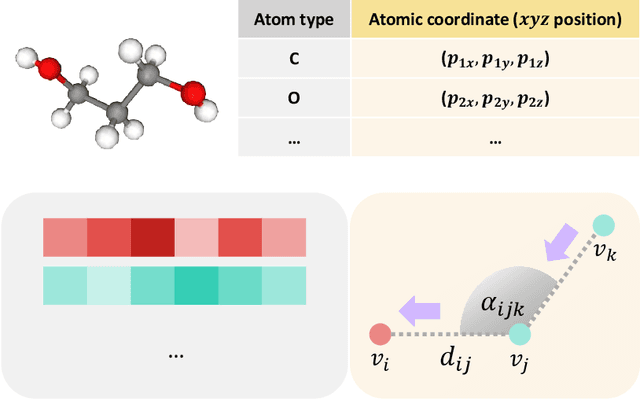
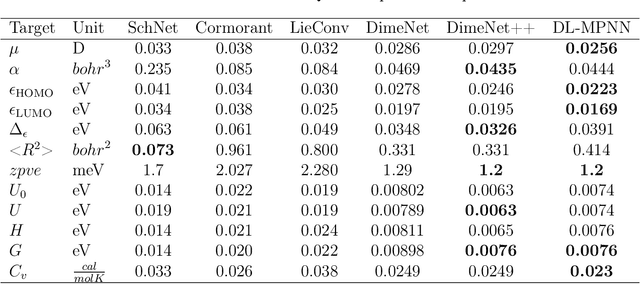
A molecule is a complex of heterogeneous components, and the spatial arrangements of these components determine the whole molecular properties and characteristics. With the advent of deep learning in computational chemistry, several studies have focused on how to predict molecular properties based on molecular configurations. Message passing neural network provides an effective framework for capturing molecular geometric features with the perspective of a molecule as a graph. However, most of these studies assumed that all heterogeneous molecular features, such as atomic charge, bond length, or other geometric features always contribute equivalently to the target prediction, regardless of the task type. In this study, we propose a dual-branched neural network for molecular property prediction based on message-passing framework. Our model learns heterogeneous molecular features with different scales, which are trained flexibly according to each prediction target. In addition, we introduce a discrete branch to learn single atom features without local aggregation, apart from message-passing steps. We verify that this novel structure can improve the model performance with faster convergence in most targets. The proposed model outperforms other recent models with sparser representations. Our experimental results indicate that in the chemical property prediction tasks, the diverse chemical nature of targets should be carefully considered for both model performance and generalizability.
Energy-efficient Knowledge Distillation for Spiking Neural Networks
Jun 14, 2021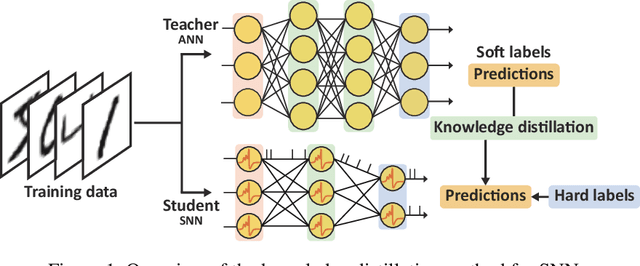
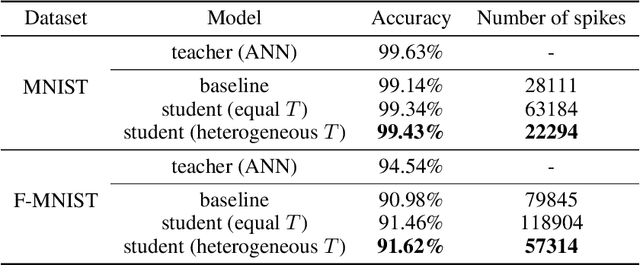
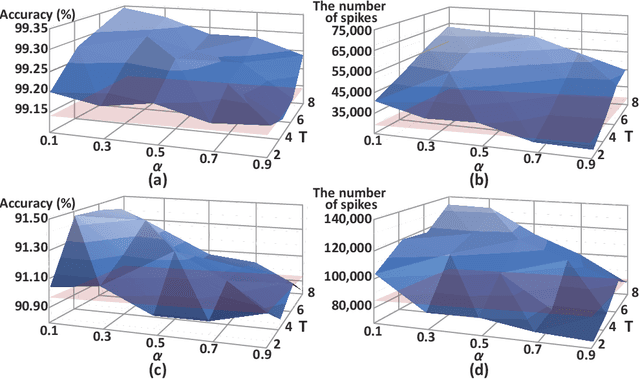
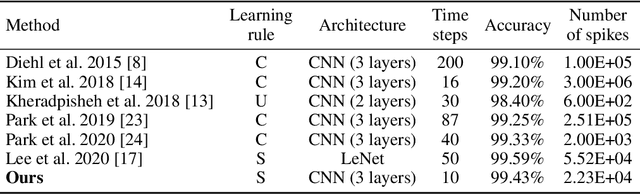
Spiking neural networks (SNNs) have been gaining interest as energy-efficient alternatives of conventional artificial neural networks (ANNs) due to their event-driven computation. Considering the future deployment of SNN models to constrained neuromorphic devices, many studies have applied techniques originally used for ANN model compression, such as network quantization, pruning, and knowledge distillation, to SNNs. Among them, existing works on knowledge distillation reported accuracy improvements of student SNN model. However, analysis on energy efficiency, which is also an important feature of SNN, was absent. In this paper, we thoroughly analyze the performance of the distilled SNN model in terms of accuracy and energy efficiency. In the process, we observe a substantial increase in the number of spikes, leading to energy inefficiency, when using the conventional knowledge distillation methods. Based on this analysis, to achieve energy efficiency, we propose a novel knowledge distillation method with heterogeneous temperature parameters. We evaluate our method on two different datasets and show that the resulting SNN student satisfies both accuracy improvement and reduction of the number of spikes. On MNIST dataset, our proposed student SNN achieves up to 0.09% higher accuracy and produces 65% less spikes compared to the student SNN trained with conventional knowledge distillation method. We also compare the results with other SNN compression techniques and training methods.
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Driven Adaptive Prior
Jun 11, 2021
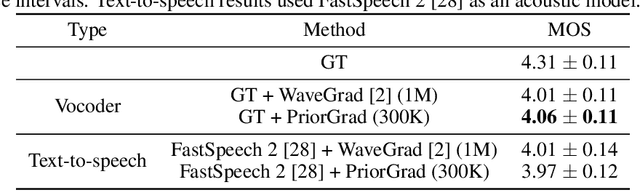


Denoising diffusion probabilistic models have been recently proposed to generate high-quality samples by estimating the gradient of the data density. The framework assumes the prior noise as a standard Gaussian distribution, whereas the corresponding data distribution may be more complicated than the standard Gaussian distribution, which potentially introduces inefficiency in denoising the prior noise into the data sample because of the discrepancy between the data and the prior. In this paper, we propose PriorGrad to improve the efficiency of the conditional diffusion model (for example, a vocoder using a mel-spectrogram as the condition) by applying an adaptive prior derived from the data statistics based on the conditional information. We formulate the training and sampling procedures of PriorGrad and demonstrate the advantages of an adaptive prior through a theoretical analysis. Focusing on the audio domain, we consider the recently proposed diffusion-based audio generative models based on both the spectral and time domains and show that PriorGrad achieves a faster convergence leading to data and parameter efficiency and improved quality, and thereby demonstrating the efficiency of a data-driven adaptive prior.
Stein Latent Optimization for GANs
Jun 09, 2021
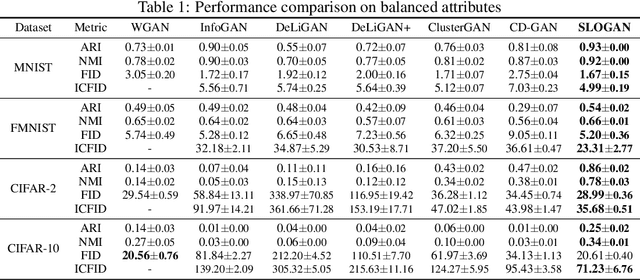

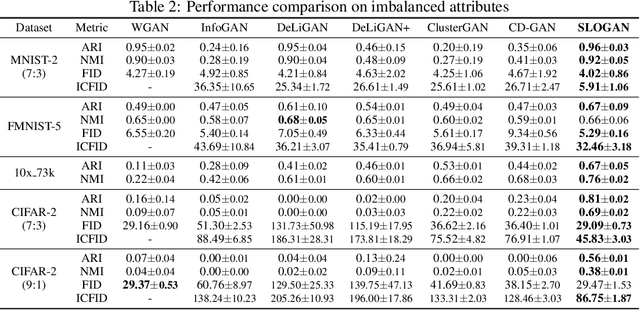
Generative adversarial networks (GANs) with clustered latent spaces can perform conditional generation in a completely unsupervised manner. However, the salient attributes of unlabeled data in the real-world are mostly imbalanced. Existing unsupervised conditional GANs cannot properly cluster the attributes in their latent spaces because they assume uniform distributions of the attributes. To address this problem, we theoretically derive Stein latent optimization that provides reparameterizable gradient estimations of the latent distribution parameters assuming a Gaussian mixture prior in a continuous latent space. Structurally, we introduce an encoder network and a novel contrastive loss to help generated data from a single mixture component to represent a single attribute. We confirm that the proposed method, named Stein Latent Optimization for GANs (SLOGAN), successfully learns the balanced or imbalanced attributes and performs unsupervised tasks such as unsupervised conditional generation, unconditional generation, and cluster assignment even in the absence of information of the attributes (e.g. the imbalance ratio). Moreover, we demonstrate that the attributes to be learned can be manipulated using a small amount of probe data.
Accelerating Neural Architecture Search via Proxy Data
Jun 09, 2021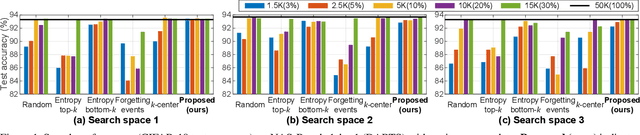
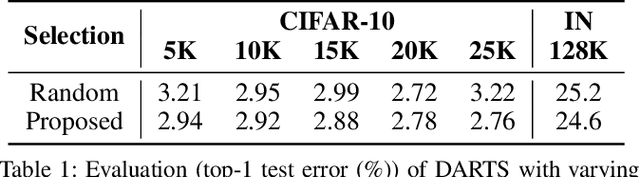

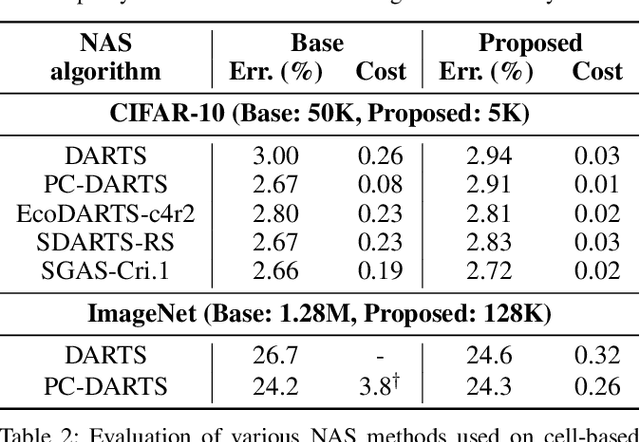
Despite the increasing interest in neural architecture search (NAS), the significant computational cost of NAS is a hindrance to researchers. Hence, we propose to reduce the cost of NAS using proxy data, i.e., a representative subset of the target data, without sacrificing search performance. Even though data selection has been used across various fields, our evaluation of existing selection methods for NAS algorithms offered by NAS-Bench-1shot1 reveals that they are not always appropriate for NAS and a new selection method is necessary. By analyzing proxy data constructed using various selection methods through data entropy, we propose a novel proxy data selection method tailored for NAS. To empirically demonstrate the effectiveness, we conduct thorough experiments across diverse datasets, search spaces, and NAS algorithms. Consequently, NAS algorithms with the proposed selection discover architectures that are competitive with those obtained using the entire dataset. It significantly reduces the search cost: executing DARTS with the proposed selection requires only 40 minutes on CIFAR-10 and 7.5 hours on ImageNet with a single GPU. Additionally, when the architecture searched on ImageNet using the proposed selection is inversely transferred to CIFAR-10, a state-of-the-art test error of 2.4\% is yielded. Our code is available at https://github.com/nabk89/NAS-with-Proxy-data.
Training Energy-Efficient Deep Spiking Neural Networks with Time-to-First-Spike Coding
Jun 04, 2021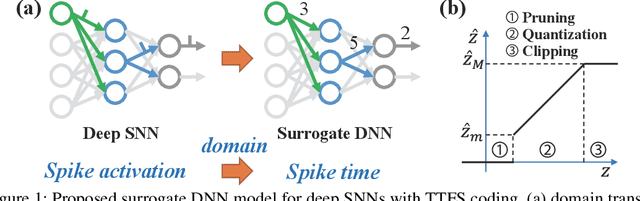
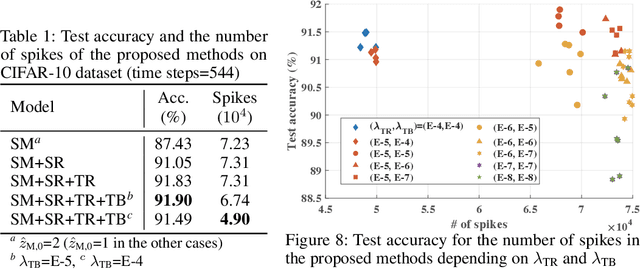
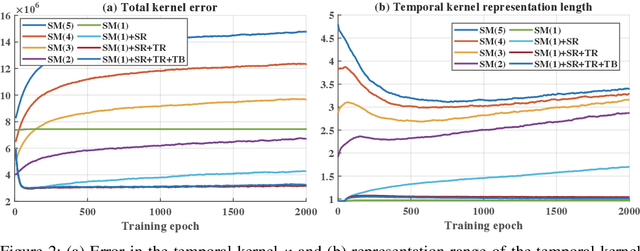
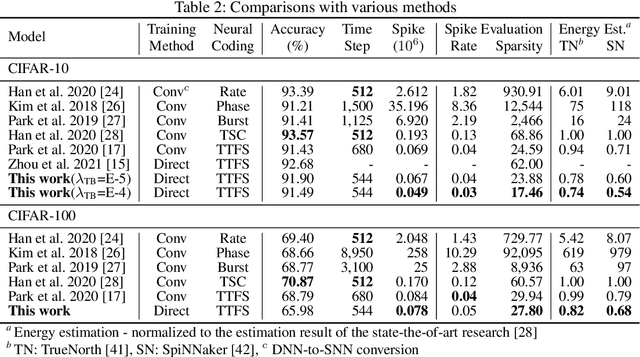
The tremendous energy consumption of deep neural networks (DNNs) has become a serious problem in deep learning. Spiking neural networks (SNNs), which mimic the operations in the human brain, have been studied as prominent energy-efficient neural networks. Due to their event-driven and spatiotemporally sparse operations, SNNs show possibilities for energy-efficient processing. To unlock their potential, deep SNNs have adopted temporal coding such as time-to-first-spike (TTFS)coding, which represents the information between neurons by the first spike time. With TTFS coding, each neuron generates one spike at most, which leads to a significant improvement in energy efficiency. Several studies have successfully introduced TTFS coding in deep SNNs, but they showed restricted efficiency improvement owing to the lack of consideration for efficiency during training. To address the aforementioned issue, this paper presents training methods for energy-efficient deep SNNs with TTFS coding. We introduce a surrogate DNN model to train the deep SNN in a feasible time and analyze the effect of the temporal kernel on training performance and efficiency. Based on the investigation, we propose stochastically relaxed activation and initial value-based regularization for the temporal kernel parameters. In addition, to reduce the number of spikes even further, we present temporal kernel-aware batch normalization. With the proposed methods, we could achieve comparable training results with significantly reduced spikes, which could lead to energy-efficient deep SNNs.
Noise-Robust Deep Spiking Neural Networks with Temporal Information
Apr 22, 2021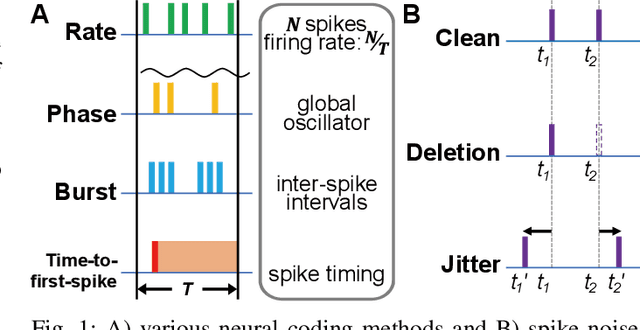
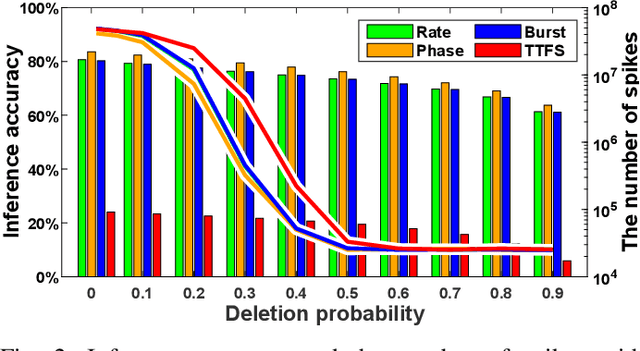
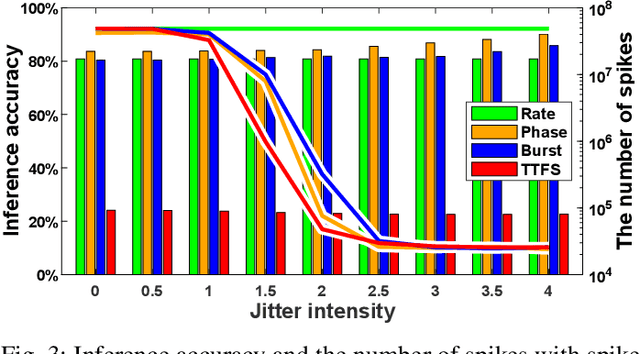
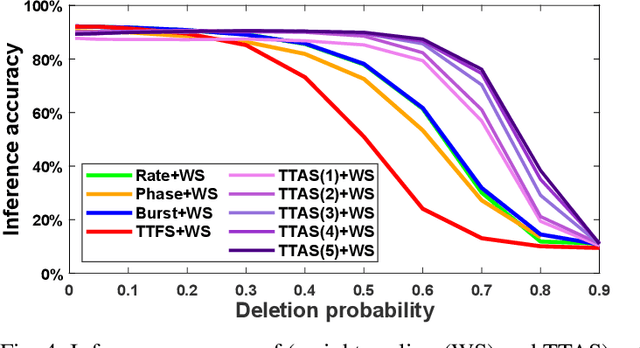
Spiking neural networks (SNNs) have emerged as energy-efficient neural networks with temporal information. SNNs have shown a superior efficiency on neuromorphic devices, but the devices are susceptible to noise, which hinders them from being applied in real-world applications. Several studies have increased noise robustness, but most of them considered neither deep SNNs nor temporal information. In this paper, we investigate the effect of noise on deep SNNs with various neural coding methods and present a noise-robust deep SNN with temporal information. With the proposed methods, we have achieved a deep SNN that is efficient and robust to spike deletion and jitter.
XProtoNet: Diagnosis in Chest Radiography with Global and Local Explanations
Mar 19, 2021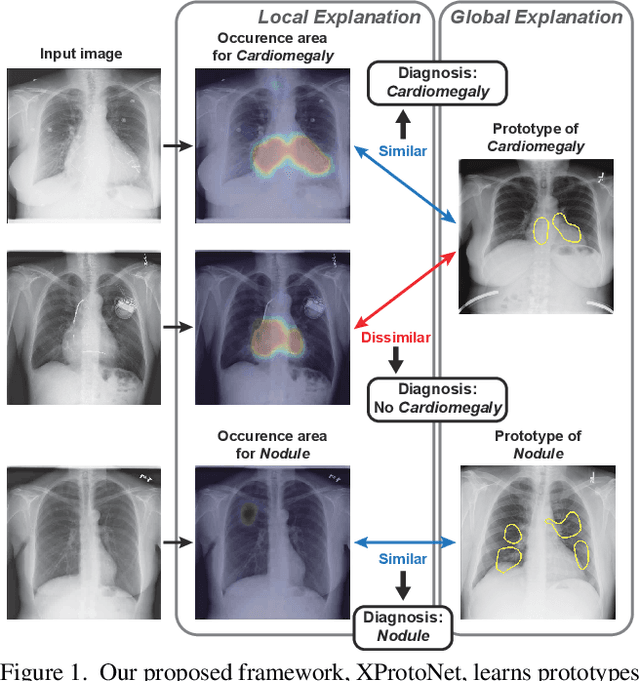
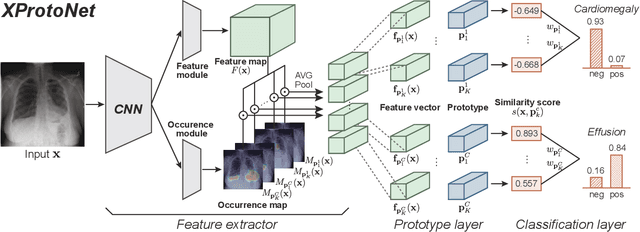
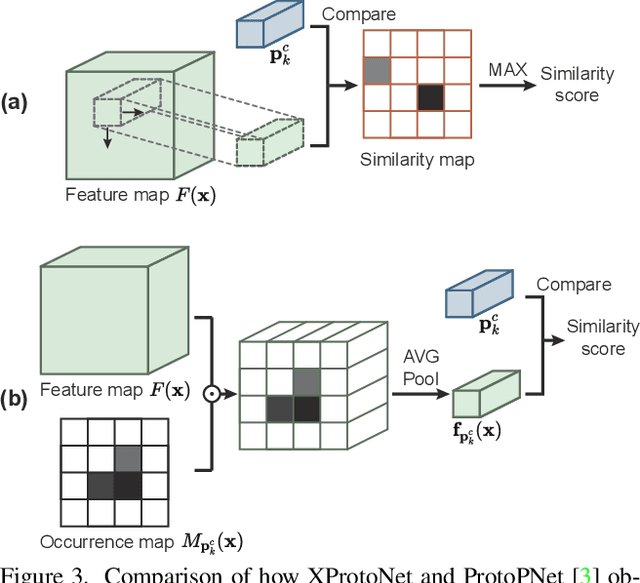
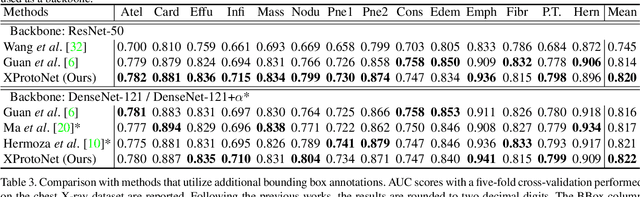
Automated diagnosis using deep neural networks in chest radiography can help radiologists detect life-threatening diseases. However, existing methods only provide predictions without accurate explanations, undermining the trustworthiness of the diagnostic methods. Here, we present XProtoNet, a globally and locally interpretable diagnosis framework for chest radiography. XProtoNet learns representative patterns of each disease from X-ray images, which are prototypes, and makes a diagnosis on a given X-ray image based on the patterns. It predicts the area where a sign of the disease is likely to appear and compares the features in the predicted area with the prototypes. It can provide a global explanation, the prototype, and a local explanation, how the prototype contributes to the prediction of a single image. Despite the constraint for interpretability, XProtoNet achieves state-of-the-art classification performance on the public NIH chest X-ray dataset.