 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024



Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Functional Interpolation for Relative Positions Improves Long Context Transformers
Oct 06, 2023Preventing the performance decay of Transformers on inputs longer than those used for training has been an important challenge in extending the context length of these models. Though the Transformer architecture has fundamentally no limits on the input sequence lengths it can process, the choice of position encoding used during training can limit the performance of these models on longer inputs. We propose a novel functional relative position encoding with progressive interpolation, FIRE, to improve Transformer generalization to longer contexts. We theoretically prove that this can represent some of the popular relative position encodings, such as T5's RPE, Alibi, and Kerple. We next empirically show that FIRE models have better generalization to longer contexts on both zero-shot language modeling and long text benchmarks.
MEMORY-VQ: Compression for Tractable Internet-Scale Memory
Aug 28, 2023



Retrieval augmentation is a powerful but expensive method to make language models more knowledgeable about the world. Memory-based methods like LUMEN pre-compute token representations for retrieved passages to drastically speed up inference. However, memory also leads to much greater storage requirements from storing pre-computed representations. We propose MEMORY-VQ, a new method to reduce storage requirements of memory-augmented models without sacrificing performance. Our method uses a vector quantization variational autoencoder (VQ-VAE) to compress token representations. We apply MEMORY-VQ to the LUMEN model to obtain LUMEN-VQ, a memory model that achieves a 16x compression rate with comparable performance on the KILT benchmark. LUMEN-VQ enables practical retrieval augmentation even for extremely large retrieval corpora.
GLIMMER: generalized late-interaction memory reranker
Jun 17, 2023



Memory-augmentation is a powerful approach for efficiently incorporating external information into language models, but leads to reduced performance relative to retrieving text. Recent work introduced LUMEN, a memory-retrieval hybrid that partially pre-computes memory and updates memory representations on the fly with a smaller live encoder. We propose GLIMMER, which improves on this approach through 1) exploiting free access to the powerful memory representations by applying a shallow reranker on top of memory to drastically improve retrieval quality at low cost, and 2) incorporating multi-task training to learn a general and higher quality memory and live encoder. GLIMMER achieves strong gains in performance at faster speeds compared to LUMEN and FiD on the KILT benchmark of knowledge-intensive tasks.
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
May 22, 2023



Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) propose a recipe for uptraining existing multi-head language model checkpoints into models with MQA using 5% of original pre-training compute, and (2) introduce grouped-query attention (GQA), a generalization of multi-query attention which uses an intermediate (more than one, less than number of query heads) number of key-value heads. We show that uptrained GQA achieves quality close to multi-head attention with comparable speed to MQA.
CoLT5: Faster Long-Range Transformers with Conditional Computation
Mar 17, 2023Many natural language processing tasks benefit from long inputs, but processing long documents with Transformers is expensive -- not only due to quadratic attention complexity but also from applying feedforward and projection layers to every token. However, not all tokens are equally important, especially for longer documents. We propose CoLT5, a long-input Transformer model that builds on this intuition by employing conditional computation, devoting more resources to important tokens in both feedforward and attention layers. We show that CoLT5 achieves stronger performance than LongT5 with much faster training and inference, achieving SOTA on the long-input SCROLLS benchmark. Moreover, CoLT5 can effectively and tractably make use of extremely long inputs, showing strong gains up to 64k input length.
Pre-computed memory or on-the-fly encoding? A hybrid approach to retrieval augmentation makes the most of your compute
Jan 25, 2023



Retrieval-augmented language models such as Fusion-in-Decoder are powerful, setting the state of the art on a variety of knowledge-intensive tasks. However, they are also expensive, due to the need to encode a large number of retrieved passages. Some work avoids this cost by pre-encoding a text corpus into a memory and retrieving dense representations directly. However, pre-encoding memory incurs a severe quality penalty as the memory representations are not conditioned on the current input. We propose LUMEN, a hybrid between these two extremes, pre-computing the majority of the retrieval representation and completing the encoding on the fly using a live encoder that is conditioned on the question and fine-tuned for the task. We show that LUMEN significantly outperforms pure memory on multiple question-answering tasks while being much cheaper than FiD, and outperforms both for any given compute budget. Moreover, the advantage of LUMEN over FiD increases with model size.
ImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022



Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.
FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022



Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
Generate-and-Retrieve: use your predictions to improve retrieval for semantic parsing
Sep 29, 2022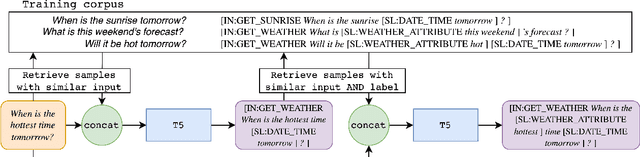
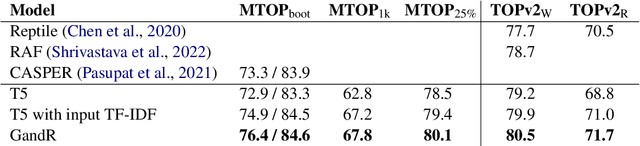
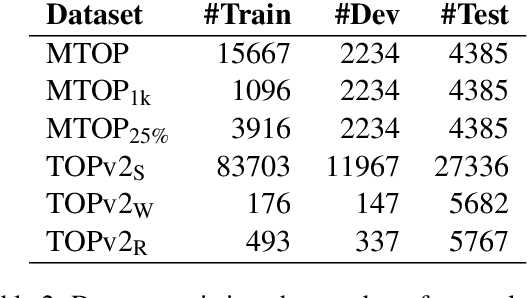
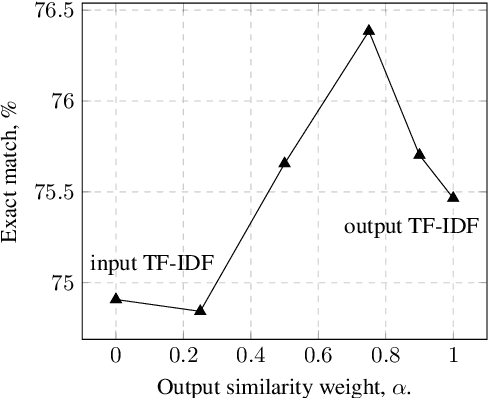
A common recent approach to semantic parsing augments sequence-to-sequence models by retrieving and appending a set of training samples, called exemplars. The effectiveness of this recipe is limited by the ability to retrieve informative exemplars that help produce the correct parse, which is especially challenging in low-resource settings. Existing retrieval is commonly based on similarity of query and exemplar inputs. We propose GandR, a retrieval procedure that retrieves exemplars for which outputs are also similar. GandRfirst generates a preliminary prediction with input-based retrieval. Then, it retrieves exemplars with outputs similar to the preliminary prediction which are used to generate a final prediction. GandR sets the state of the art on multiple low-resource semantic parsing tasks.