 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGSSM: Diffusion guided state-space models for multimodal salient object detection
Apr 19, 2026Salient object detection (SOD) requires modeling both long-range contextual dependencies and fine-grained structural details, which remains challenging for convolutional, transformer-based, and Mamba-based state space models. While recent Mamba-based state space approaches enable efficient global reasoning, they often struggle to recover precise object boundaries. In contrast, diffusion models capture strong structural priors through iterative denoising, but their use in discriminative dense prediction is still limited due to computational cost and integration challenges. In this work, we propose DGSSM, a diffusion-guided state space (Mamba) framework that formulates multimodal salient object detection as a progressive denoising process. The framework integrates diffusion structural priors with multi-scale state space encoding, adaptive saliency prompting, and an iterative Mamba diffusion refinement mechanism to improve boundary accuracy. A boundary-aware refinement head and self-distillation strategy further enhance spatial coherence and feature consistency. Extensive experiments on 13 public benchmarks across RGB, RGB-D, and RGB-T settings demonstrate that DGSSM consistently outperforms state-of-the-art methods across multiple evaluation metrics while maintaining a compact model size. These results suggest that diffusion-guided state space modeling is an effective and generalizable paradigm for multimodal dense prediction tasks.
Universal Adversarial Suffixes Using Calibrated Gumbel-Softmax Relaxation
Dec 09, 2025Language models (LMs) are often used as zero-shot or few-shot classifiers by scoring label words, but they remain fragile to adversarial prompts. Prior work typically optimizes task- or model-specific triggers, making results difficult to compare and limiting transferability. We study universal adversarial suffixes: short token sequences (4-10 tokens) that, when appended to any input, broadly reduce accuracy across tasks and models. Our approach learns the suffix in a differentiable "soft" form using Gumbel-Softmax relaxation and then discretizes it for inference. Training maximizes calibrated cross-entropy on the label region while masking gold tokens to prevent trivial leakage, with entropy regularization to avoid collapse. A single suffix trained on one model transfers effectively to others, consistently lowering both accuracy and calibrated confidence. Experiments on sentiment analysis, natural language inference, paraphrase detection, commonsense QA, and physical reasoning with Qwen2-1.5B, Phi-1.5, and TinyLlama-1.1B demonstrate consistent attack effectiveness and transfer across tasks and model families.
Universal Adversarial Suffixes for Language Models Using Reinforcement Learning with Calibrated Reward
Dec 09, 2025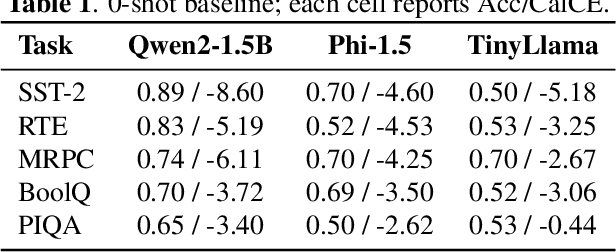
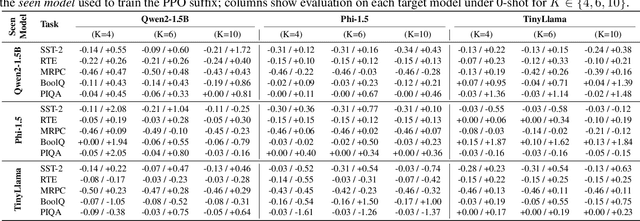
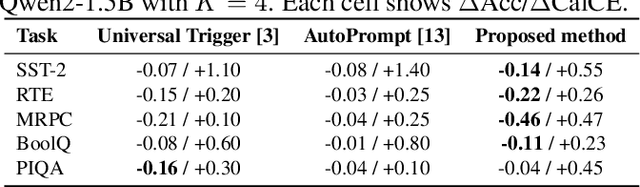
Language models are vulnerable to short adversarial suffixes that can reliably alter predictions. Previous works usually find such suffixes with gradient search or rule-based methods, but these are brittle and often tied to a single task or model. In this paper, a reinforcement learning framework is used where the suffix is treated as a policy and trained with Proximal Policy Optimization against a frozen model as a reward oracle. Rewards are shaped using calibrated cross-entropy, removing label bias and aggregating across surface forms to improve transferability. The proposed method is evaluated on five diverse NLP benchmark datasets, covering sentiment, natural language inference, paraphrase, and commonsense reasoning, using three distinct language models: Qwen2-1.5B Instruct, TinyLlama-1.1B Chat, and Phi-1.5. Results show that RL-trained suffixes consistently degrade accuracy and transfer more effectively across tasks and models than previous adversarial triggers of similar genres.
C-LEAD: Contrastive Learning for Enhanced Adversarial Defense
Oct 31, 2025



Deep neural networks (DNNs) have achieved remarkable success in computer vision tasks such as image classification, segmentation, and object detection. However, they are vulnerable to adversarial attacks, which can cause incorrect predictions with small perturbations in input images. Addressing this issue is crucial for deploying robust deep-learning systems. This paper presents a novel approach that utilizes contrastive learning for adversarial defense, a previously unexplored area. Our method leverages the contrastive loss function to enhance the robustness of classification models by training them with both clean and adversarially perturbed images. By optimizing the model's parameters alongside the perturbations, our approach enables the network to learn robust representations that are less susceptible to adversarial attacks. Experimental results show significant improvements in the model's robustness against various types of adversarial perturbations. This suggests that contrastive loss helps extract more informative and resilient features, contributing to the field of adversarial robustness in deep learning.
Trans-defense: Transformer-based Denoiser for Adversarial Defense with Spatial-Frequency Domain Representation
Oct 31, 2025



In recent times, deep neural networks (DNNs) have been successfully adopted for various applications. Despite their notable achievements, it has become evident that DNNs are vulnerable to sophisticated adversarial attacks, restricting their applications in security-critical systems. In this paper, we present two-phase training methods to tackle the attack: first, training the denoising network, and second, the deep classifier model. We propose a novel denoising strategy that integrates both spatial and frequency domain approaches to defend against adversarial attacks on images. Our analysis reveals that high-frequency components of attacked images are more severely corrupted compared to their lower-frequency counterparts. To address this, we leverage Discrete Wavelet Transform (DWT) for frequency analysis and develop a denoising network that combines spatial image features with wavelets through a transformer layer. Next, we retrain the classifier using the denoised images, which enhances the classifier's robustness against adversarial attacks. Experimental results across the MNIST, CIFAR-10, and Fashion-MNIST datasets reveal that the proposed method remarkably elevates classification accuracy, substantially exceeding the performance by utilizing a denoising network and adversarial training approaches. The code is available at https://github.com/Mayank94/Trans-Defense.