 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Adversarial Suffixes for Language Models Using Reinforcement Learning with Calibrated Reward
Paper and Code
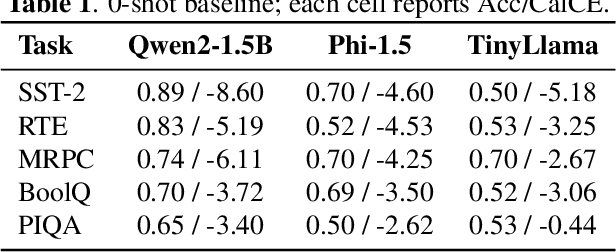
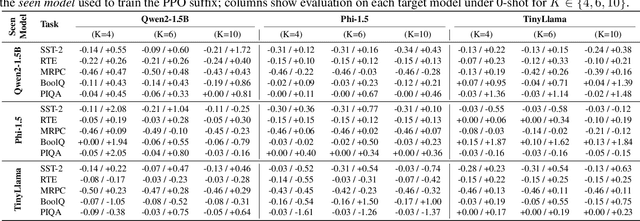
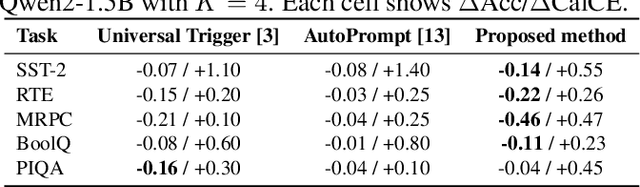
Language models are vulnerable to short adversarial suffixes that can reliably alter predictions. Previous works usually find such suffixes with gradient search or rule-based methods, but these are brittle and often tied to a single task or model. In this paper, a reinforcement learning framework is used where the suffix is treated as a policy and trained with Proximal Policy Optimization against a frozen model as a reward oracle. Rewards are shaped using calibrated cross-entropy, removing label bias and aggregating across surface forms to improve transferability. The proposed method is evaluated on five diverse NLP benchmark datasets, covering sentiment, natural language inference, paraphrase, and commonsense reasoning, using three distinct language models: Qwen2-1.5B Instruct, TinyLlama-1.1B Chat, and Phi-1.5. Results show that RL-trained suffixes consistently degrade accuracy and transfer more effectively across tasks and models than previous adversarial triggers of similar genres.