 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Adversarial Suffixes for Language Models Using Reinforcement Learning with Calibrated Reward
Dec 09, 2025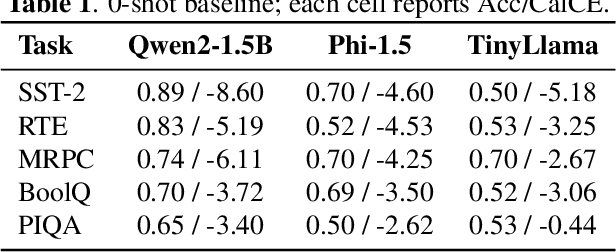
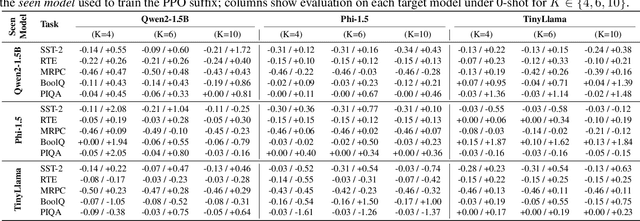
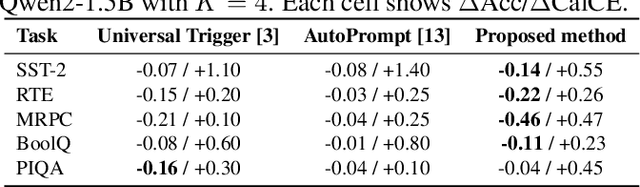
Language models are vulnerable to short adversarial suffixes that can reliably alter predictions. Previous works usually find such suffixes with gradient search or rule-based methods, but these are brittle and often tied to a single task or model. In this paper, a reinforcement learning framework is used where the suffix is treated as a policy and trained with Proximal Policy Optimization against a frozen model as a reward oracle. Rewards are shaped using calibrated cross-entropy, removing label bias and aggregating across surface forms to improve transferability. The proposed method is evaluated on five diverse NLP benchmark datasets, covering sentiment, natural language inference, paraphrase, and commonsense reasoning, using three distinct language models: Qwen2-1.5B Instruct, TinyLlama-1.1B Chat, and Phi-1.5. Results show that RL-trained suffixes consistently degrade accuracy and transfer more effectively across tasks and models than previous adversarial triggers of similar genres.
Universal Adversarial Suffixes Using Calibrated Gumbel-Softmax Relaxation
Dec 09, 2025Language models (LMs) are often used as zero-shot or few-shot classifiers by scoring label words, but they remain fragile to adversarial prompts. Prior work typically optimizes task- or model-specific triggers, making results difficult to compare and limiting transferability. We study universal adversarial suffixes: short token sequences (4-10 tokens) that, when appended to any input, broadly reduce accuracy across tasks and models. Our approach learns the suffix in a differentiable "soft" form using Gumbel-Softmax relaxation and then discretizes it for inference. Training maximizes calibrated cross-entropy on the label region while masking gold tokens to prevent trivial leakage, with entropy regularization to avoid collapse. A single suffix trained on one model transfers effectively to others, consistently lowering both accuracy and calibrated confidence. Experiments on sentiment analysis, natural language inference, paraphrase detection, commonsense QA, and physical reasoning with Qwen2-1.5B, Phi-1.5, and TinyLlama-1.1B demonstrate consistent attack effectiveness and transfer across tasks and model families.
A UNet Model for Accelerated Preprocessing of CRISM Hyperspectral Data for Mineral Identification on Mars
May 04, 2025Accurate mineral identification on the Martian surface is critical for understanding the planet's geological history. This paper presents a UNet-based autoencoder model for efficient spectral preprocessing of CRISM MTRDR hyperspectral data, addressing the limitations of traditional methods that are computationally intensive and time-consuming. The proposed model automates key preprocessing steps, such as smoothing and continuum removal, while preserving essential mineral absorption features. Trained on augmented spectra from the MICA spectral library, the model introduces realistic variability to simulate MTRDR data conditions. By integrating this framework, preprocessing time for an 800x800 MTRDR scene is reduced from 1.5 hours to just 5 minutes on an NVIDIA T1600 GPU. The preprocessed spectra are subsequently classified using MICAnet, a deep learning model for Martian mineral identification. Evaluation on labeled CRISM TRDR data demonstrates that the proposed approach achieves competitive accuracy while significantly enhancing preprocessing efficiency. This work highlights the potential of the UNet-based preprocessing framework to improve the speed and reliability of mineral mapping on Mars.
Weighted Sum of Segmented Correlation: An Efficient Method for Spectra Matching in Hyperspectral Images
Jun 18, 2024


Matching a target spectrum with known spectra in a spectral library is a common method for material identification in hyperspectral imaging research. Hyperspectral spectra exhibit precise absorption features across different wavelength segments, and the unique shapes and positions of these absorptions create distinct spectral signatures for each material, aiding in their identification. Therefore, only the specific positions can be considered for material identification. This study introduces the Weighted Sum of Segmented Correlation method, which calculates correlation indices between various segments of a library and a test spectrum, and derives a matching index, favoring positive correlations and penalizing negative correlations using assigned weights. The effectiveness of this approach is evaluated for mineral identification in hyperspectral images from both Earth and Martian surfaces.