 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoze: Sports Technique Feedback under Data Constraints
Nov 08, 2024Access to expert coaching is essential for developing technique in sports, yet economic barriers often place it out of reach for many enthusiasts. To bridge this gap, we introduce Poze, an innovative video processing framework that provides feedback on human motion, emulating the insights of a professional coach. Poze combines pose estimation with sequence comparison and is optimized to function effectively with minimal data. Poze surpasses state-of-the-art vision-language models in video question-answering frameworks, achieving 70% and 196% increase in accuracy over GPT4V and LLaVAv1.6 7b, respectively.
Off-Road LiDAR Intensity Based Semantic Segmentation
Jan 02, 2024LiDAR is used in autonomous driving to provide 3D spatial information and enable accurate perception in off-road environments, aiding in obstacle detection, mapping, and path planning. Learning-based LiDAR semantic segmentation utilizes machine learning techniques to automatically classify objects and regions in LiDAR point clouds. Learning-based models struggle in off-road environments due to the presence of diverse objects with varying colors, textures, and undefined boundaries, which can lead to difficulties in accurately classifying and segmenting objects using traditional geometric-based features. In this paper, we address this problem by harnessing the LiDAR intensity parameter to enhance object segmentation in off-road environments. Our approach was evaluated in the RELLIS-3D data set and yielded promising results as a preliminary analysis with improved mIoU for classes "puddle" and "grass" compared to more complex deep learning-based benchmarks. The methodology was evaluated for compatibility across both Velodyne and Ouster LiDAR systems, assuring its cross-platform applicability. This analysis advocates for the incorporation of calibrated intensity as a supplementary input, aiming to enhance the prediction accuracy of learning based semantic segmentation frameworks. https://github.com/MOONLABIISERB/lidar-intensity-predictor/tree/main
A COLREGs-Compliant Conflict Resolution Strategy for Autonomous Surface Vehicles
Dec 13, 2023



This paper presents a novel conflict resolution strategy for autonomous surface vehicles (ASVs) to safely navigate and avoid collisions in a multi-vessel environment at sea. Collisions between two or more marine vessels must be avoided by following the International Regulations for Preventing Collisions at Sea (COLREGs). We propose strategy a two-phase strategy called as COLREGs Compliant Conflict-Resolving (COMCORE) strategy, that generates collision-free trajectories for ASVs while complying with COLREGs. In phase-1, a shortest path for each agent is determined, while in phase-2 conflicts are detected and resolved by modifying the path in compliance with COLREGs. COMCORE solution optimises vessel trajectories for lower costs while also providing a safe and collision-free plan for each vessel. Simulation results are presented to show the applicability of COMCORE for larger number agents with very low computational requirement and hence scalable. Further, we experimentally demonstrate COMCORE for two ASVs in a lake to show its ability to determine solution and implementation capability in the real-world.
UAV Target Tracking in Urban Environments Using Deep Reinforcement Learning
Jul 21, 2020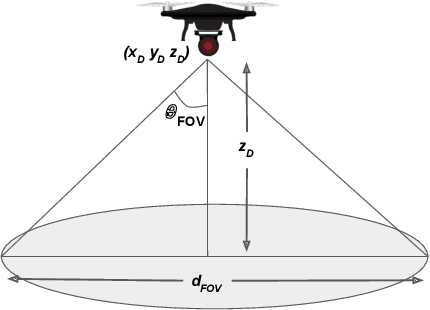
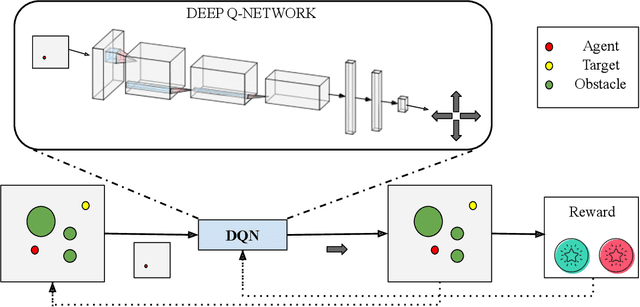
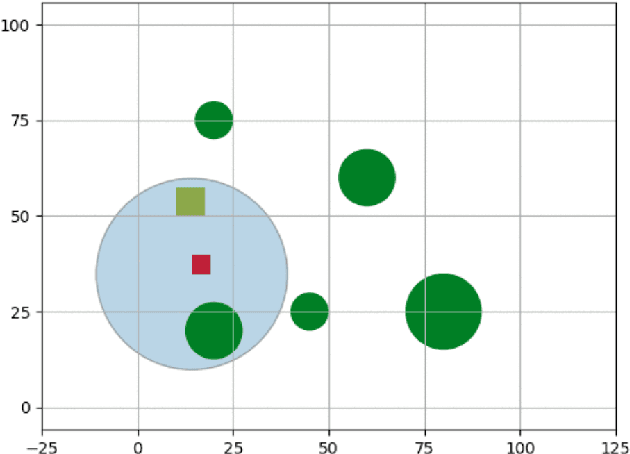
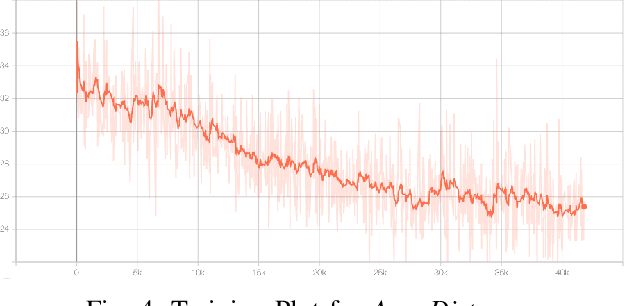
Persistent target tracking in urban environments using UAV is a difficult task due to the limited field of view, visibility obstruction from obstacles and uncertain target motion. The vehicle needs to plan intelligently in 3D such that the target visibility is maximized. In this paper, we introduce Target Following DQN (TF-DQN), a deep reinforcement learning technique based on Deep Q-Networks with a curriculum training framework for the UAV to persistently track the target in the presence of obstacles and target motion uncertainty. The algorithm is evaluated through several simulation experiments qualitatively as well as quantitatively. The results show that the UAV tracks the target persistently in diverse environments while avoiding obstacles on the trained environments as well as on unseen environments.