 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACOS: Topology-Aware Collective Algorithm Synthesizer for Distributed Training
Apr 11, 2023



Collective communications are an indispensable part of distributed training. Running a topology-aware collective algorithm is crucial for optimizing communication performance by minimizing congestion. Today such algorithms only exist for a small set of simple topologies, limiting the topologies employed in training clusters and handling irregular topologies due to network failures. In this paper, we propose TACOS, an automated topology-aware collective synthesizer for arbitrary input network topologies. TACOS synthesized 3.73x faster All-Reduce algorithm over baselines, and synthesized collective algorithms for 512-NPU system in just 6.1 minutes.
ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale
Mar 24, 2023As deep learning models and input data are scaling at an unprecedented rate, it is inevitable to move towards distributed training platforms to fit the model and increase training throughput. State-of-the-art approaches and techniques, such as wafer-scale nodes, multi-dimensional network topologies, disaggregated memory systems, and parallelization strategies, have been actively adopted by emerging distributed training systems. This results in a complex SW/HW co-design stack of distributed training, necessitating a modeling/simulation infrastructure for design-space exploration. In this paper, we extend the open-source ASTRA-sim infrastructure and endow it with the capabilities to model state-of-the-art and emerging distributed training models and platforms. More specifically, (i) we enable ASTRA-sim to support arbitrary model parallelization strategies via a graph-based training-loop implementation, (ii) we implement a parameterizable multi-dimensional heterogeneous topology generation infrastructure with analytical performance estimates enabling simulating target systems at scale, and (iii) we enhance the memory system modeling to support accurate modeling of in-network collective communication and disaggregated memory systems. With such capabilities, we run comprehensive case studies targeting emerging distributed models and platforms. This infrastructure lets system designers swiftly traverse the complex co-design stack and give meaningful insights when designing and deploying distributed training platforms at scale.
BioADAPT-MRC: Adversarial Learning-based Domain Adaptation Improves Biomedical Machine Reading Comprehension Task
Feb 26, 2022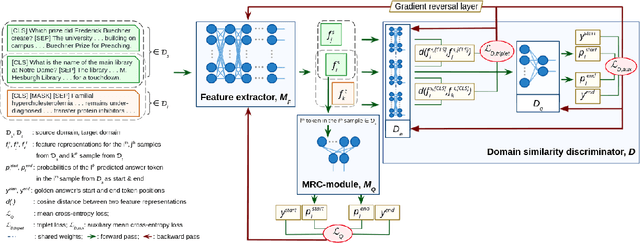

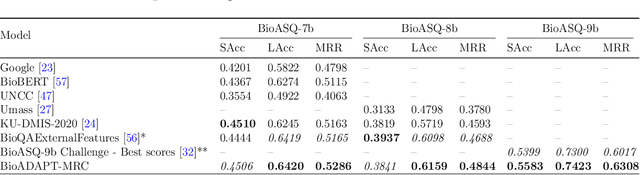
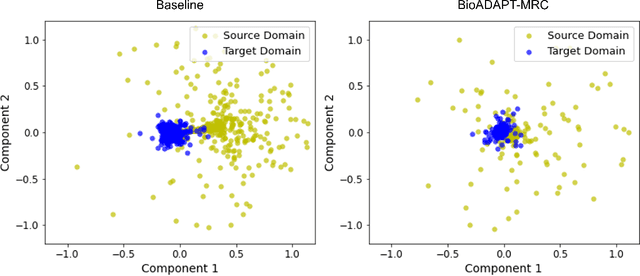
Motivation: Biomedical machine reading comprehension (biomedical-MRC) aims to comprehend complex biomedical narratives and assist healthcare professionals in retrieving information from them. The high performance of modern neural network-based MRC systems depends on high-quality, large-scale, human-annotated training datasets. In the biomedical domain, a crucial challenge in creating such datasets is the requirement for domain knowledge, inducing the scarcity of labeled data and the need for transfer learning from the labeled general-purpose (source) domain to the biomedical (target) domain. However, there is a discrepancy in marginal distributions between the general-purpose and biomedical domains due to the variances in topics. Therefore, direct-transferring of learned representations from a model trained on a general-purpose domain to the biomedical domain can hurt the model's performance. Results: We present an adversarial learning-based domain adaptation framework for the biomedical machine reading comprehension task (BioADAPT-MRC), a neural network-based method to address the discrepancies in the marginal distributions between the general and biomedical domain datasets. BioADAPT-MRC relaxes the need for generating pseudo labels for training a well-performing biomedical-MRC model. We extensively evaluate the performance of BioADAPT-MRC by comparing it with the best existing methods on three widely used benchmark biomedical-MRC datasets -- BioASQ-7b, BioASQ-8b, and BioASQ-9b. Our results suggest that without using any synthetic or human-annotated data from the biomedical domain, BioADAPT-MRC can achieve state-of-the-art performance on these datasets. Availability: BioADAPT-MRC is freely available as an open-source project at\\https://github.com/mmahbub/BioADAPT-MRC
Themis: A Network Bandwidth-Aware Collective Scheduling Policy for Distributed Training of DL Models
Oct 09, 2021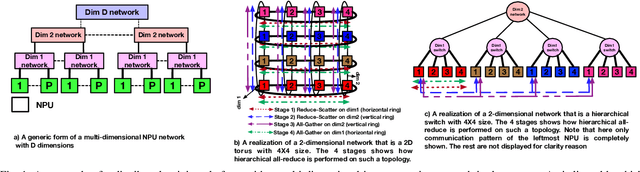



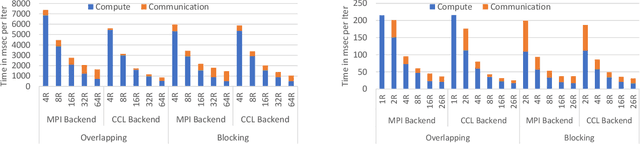
The continuous growth in both size and training data for modern Deep Neural Networks (DNNs) models has led to training tasks taking days or even months. Distributed training is a solution to reduce training time by splitting the task across multiple NPUs (e.g., GPU/TPU). However, distributed training adds communication overhead between the NPUs in order to synchronize the gradients and/or activation, depending on the parallelization strategy. In today's datacenters, for training at scale, NPUs are connected through multi-dimensional interconnection links with different bandwidth and latency. Hence, keeping all network dimensions busy and maximizing the network BW is a challenging task in such a hybrid network environment, as this work identifies. We propose Themis, a novel collective scheduling scheme that dynamically schedules collectives (divided into chunks) to balance the communication loads across all dimensions, further improving the network BW utilization. Our results show that on average, Themis can improve the network BW utilization of single All-Reduce by 1.88x (2.92x max), and improve the end-to-end training iteration performance of real workloads such as ResNet-50, GNMT, DLRM, and Transformer- 1T by 1.49x (1.96x max), 1.41x (1.81x max), 1.42x (1.80x max), and 1.35x (1.78x max), respectively.
Exploring Multi-dimensional Hierarchical Network Topologies for Efficient Distributed Training of Trillion Parameter DL Models
Sep 24, 2021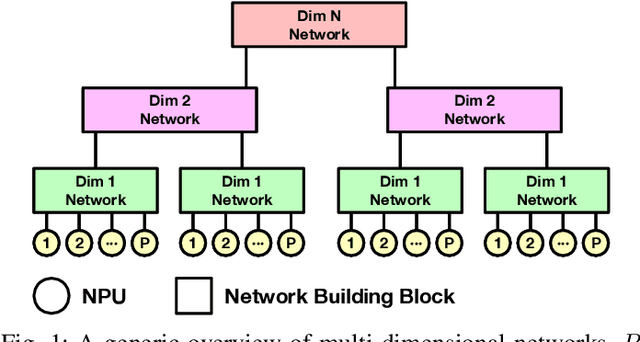
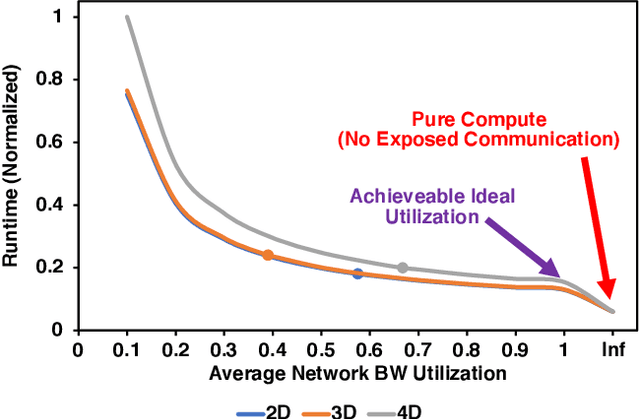
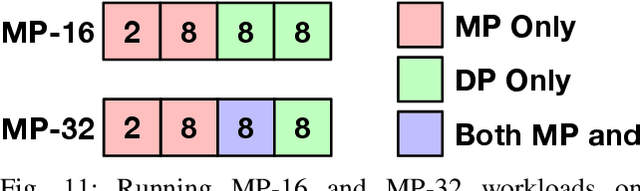
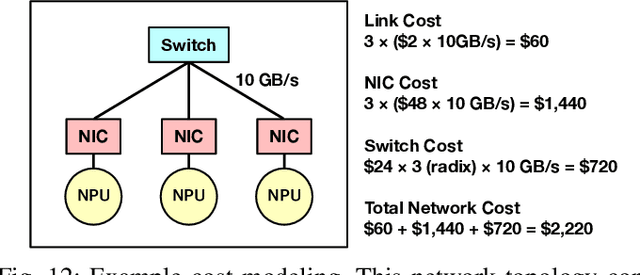
Deep Neural Networks have gained significant attraction due to their wide applicability in different domains. DNN sizes and training samples are constantly growing, making training of such workloads more challenging. Distributed training is a solution to reduce the training time. High-performance distributed training platforms should leverage multi-dimensional hierarchical networks, which interconnect accelerators through different levels of the network, to dramatically reduce expensive NICs required for the scale-out network. However, it comes at the expense of communication overhead between distributed accelerators to exchange gradients or input/output activation. In order to allow for further scaling of the workloads, communication overhead needs to be minimized. In this paper, we motivate the fact that in training platforms, adding more intermediate network dimensions is beneficial for efficiently mitigating the excessive use of expensive NIC resources. Further, we address different challenges of the DNN training on hierarchical networks. We discuss when designing the interconnect, how to distribute network bandwidth resources across different dimensions in order to (i) maximize BW utilization of all dimensions, and (ii) minimizing the overall training time for the target workload. We then implement a framework that, for a given workload, determines the best network configuration that maximizes performance, or performance-per-cost.
The Sensitivity of Word Embeddings-based Author Detection Models to Semantic-preserving Adversarial Perturbations
Feb 23, 2021

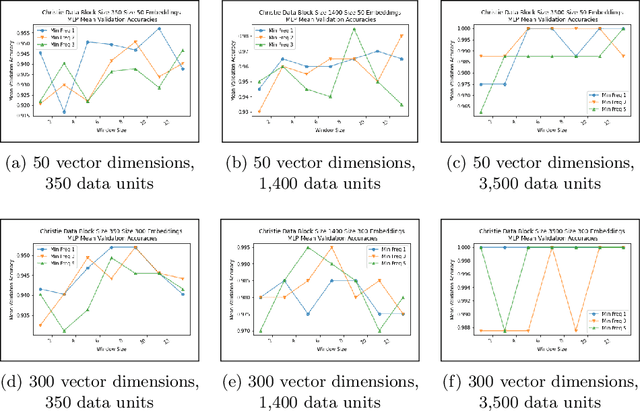

Authorship analysis is an important subject in the field of natural language processing. It allows the detection of the most likely writer of articles, news, books, or messages. This technique has multiple uses in tasks related to authorship attribution, detection of plagiarism, style analysis, sources of misinformation, etc. The focus of this paper is to explore the limitations and sensitiveness of established approaches to adversarial manipulations of inputs. To this end, and using those established techniques, we first developed an experimental frame-work for author detection and input perturbations. Next, we experimentally evaluated the performance of the authorship detection model to a collection of semantic-preserving adversarial perturbations of input narratives. Finally, we compare and analyze the effects of different perturbation strategies, input and model configurations, and the effects of these on the author detection model.
Optimizing Deep Learning Recommender Systems' Training On CPU Cluster Architectures
May 10, 2020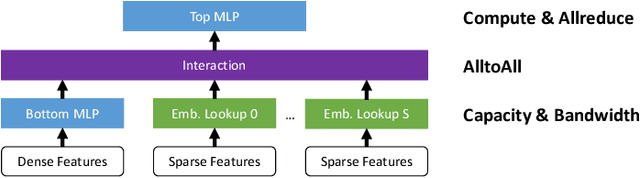
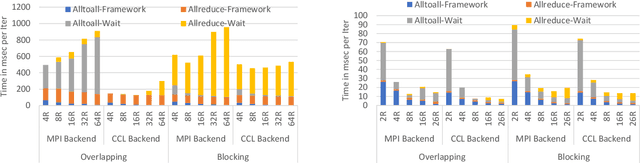

During the last two years, the goal of many researchers has been to squeeze the last bit of performance out of HPC system for AI tasks. Often this discussion is held in the context of how fast ResNet50 can be trained. Unfortunately, ResNet50 is no longer a representative workload in 2020. Thus, we focus on Recommender Systems which account for most of the AI cycles in cloud computing centers. More specifically, we focus on Facebook's DLRM benchmark. By enabling it to run on latest CPU hardware and software tailored for HPC, we are able to achieve more than two-orders of magnitude improvement in performance (110x) on a single socket compared to the reference CPU implementation, and high scaling efficiency up to 64 sockets, while fitting ultra-large datasets. This paper discusses the optimization techniques for the various operators in DLRM and which component of the systems are stressed by these different operators. The presented techniques are applicable to a broader set of DL workloads that pose the same scaling challenges/characteristics as DLRM.
K-TanH: Hardware Efficient Activations For Deep Learning
Oct 21, 2019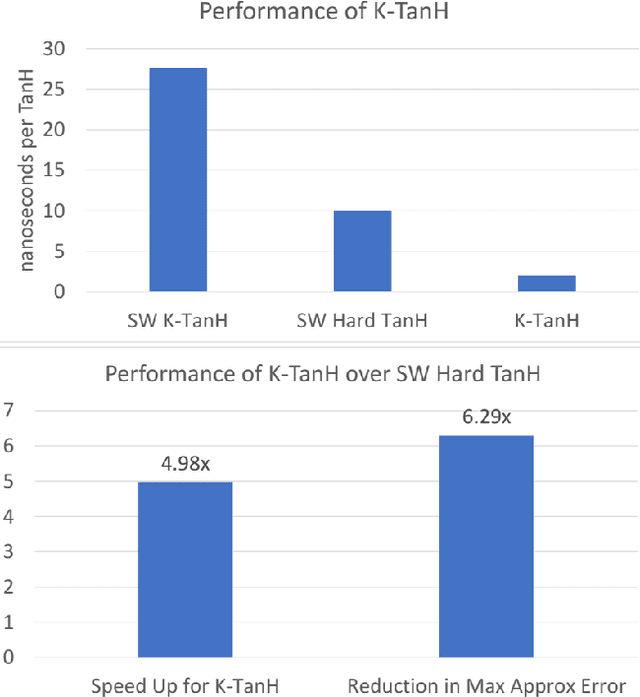
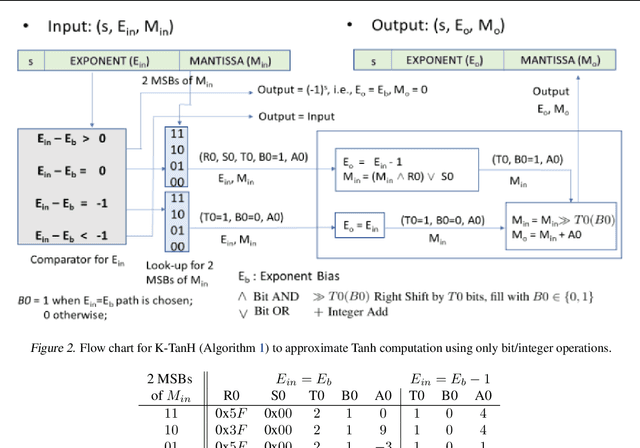

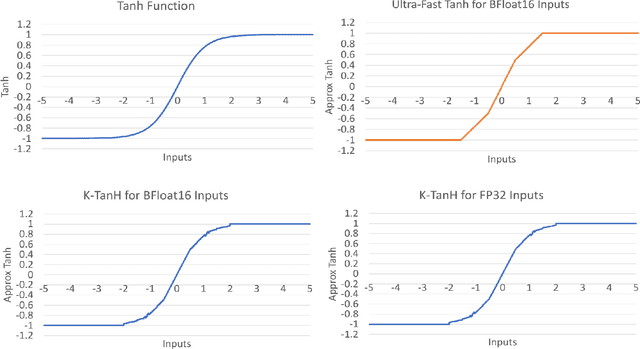
We propose K-TanH, a novel, highly accurate, hardware efficient approximation of popular activation function Tanh for Deep Learning. K-TanH consists of a sequence of parameterized bit/integer operations, such as, masking, shift and add/subtract (no floating point operation needed) where parameters are stored in a very small look-up table (bit-masking step can be eliminated). The design of K-TanH is flexible enough to deal with multiple numerical formats, such as, FP32 and BFloat16. High quality approximations to other activation functions, e.g., Swish and GELU, can be derived from K-TanH. We provide RTL design for K-TanH to demonstrate its area/power/performance efficacy. It is more accurate than existing piecewise approximations for Tanh. For example, K-TanH achieves $\sim 5\times$ speed up and $> 6\times$ reduction in maximum approximation error over software implementation of Hard TanH. Experimental results for low-precision BFloat16 training of language translation model GNMT on WMT16 data sets with approximate Tanh and Sigmoid obtained via K-TanH achieve similar accuracy and convergence as training with exact Tanh and Sigmoid.
High Performance Scalable FPGA Accelerator for Deep Neural Networks
Aug 29, 2019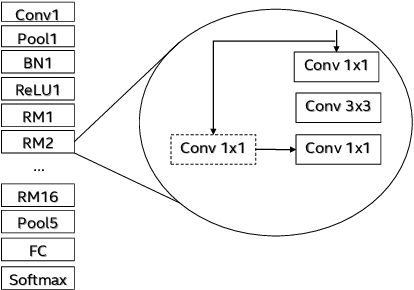
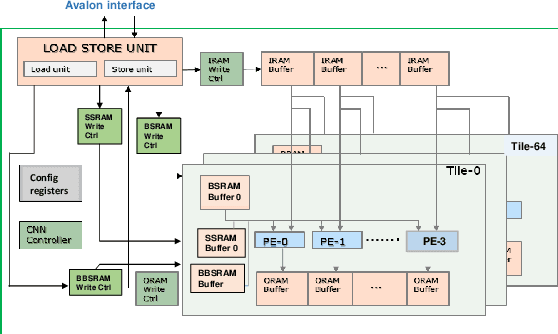
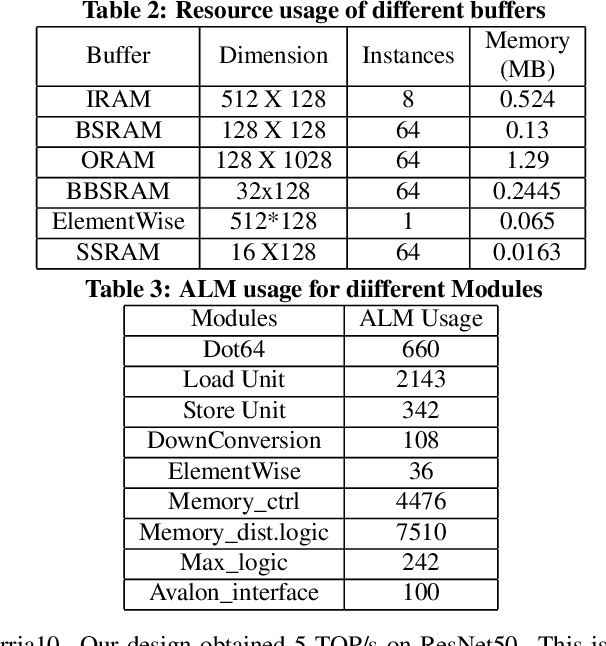
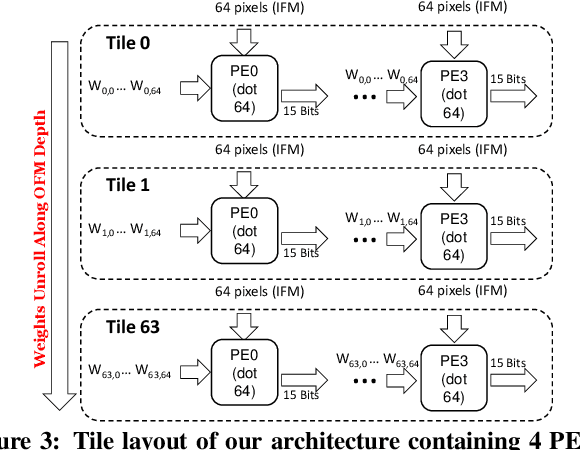
Low-precision is the first order knob for achieving higher Artificial Intelligence Operations (AI-TOPS). However the algorithmic space for sub-8-bit precision compute is diverse, with disruptive changes happening frequently, making FPGAs a natural choice for Deep Neural Network inference, In this work we present an FPGA-based accelerator for CNN inference acceleration. We use {\it INT-8-2} compute (with {\it 8 bit} activation and {2 bit} weights) which is recently showing promise in the literature, and which no known ASIC, CPU or GPU natively supports today. Using a novel Adaptive Logic Module (ALM) based design, as a departure from traditional DSP based designs, we are able to achieve high performance measurement of 5 AI-TOPS for {\it Arria10} and project a performance of 76 AI-TOPS at 0.7 TOPS/W for {\it Stratix10}. This exceeds known CPU, GPU performance and comes close to best known ASIC (TPU) numbers, while retaining the versatility of the FPGA platform for other applications.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019
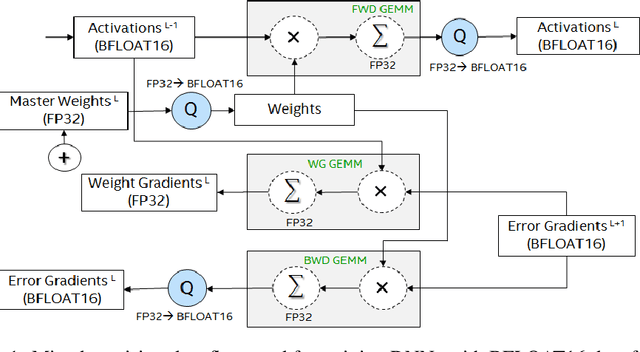
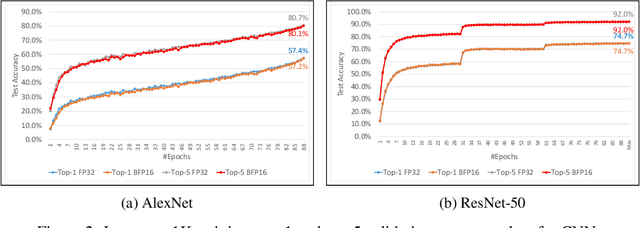

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.