 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML4H Abstract Track 2020
Nov 19, 2020A collection of the accepted abstracts for the Machine Learning for Health (ML4H) workshop at NeurIPS 2020. This index is not complete, as some accepted abstracts chose to opt-out of inclusion.
Type-Driven Automated Learning with Lale
May 24, 2019

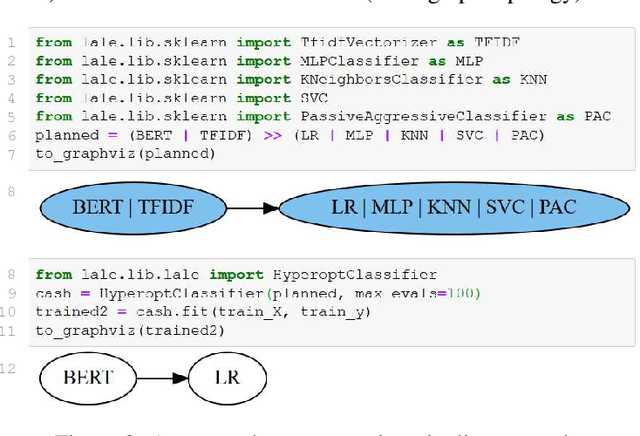

Machine-learning automation tools, ranging from humble grid-search to hyperopt, auto-sklearn, and TPOT, help explore large search spaces of possible pipelines. Unfortunately, each of these tools has a different syntax for specifying its search space, leading to lack of portability, missed relevant points, and spurious points that are inconsistent with error checks and documentation of the searchable base components. This paper proposes using types (such as enum, float, or dictionary) both for checking the correctness of, and for automatically searching over, hyperparameters and pipeline configurations. Using types for both of these purposes guarantees consistency. We present Lale, an embedded language that resembles scikit learn but provides better automation, correctness checks, and portability. Lale extends the reach of existing automation tools across data modalities (tables, text, images, time-series) and programming languages (Python, Java, R). Thus, data scientists can leverage automation while remaining in control of their work.
Machine Learning for removing EEG artifacts: Setting the benchmark
Mar 19, 2019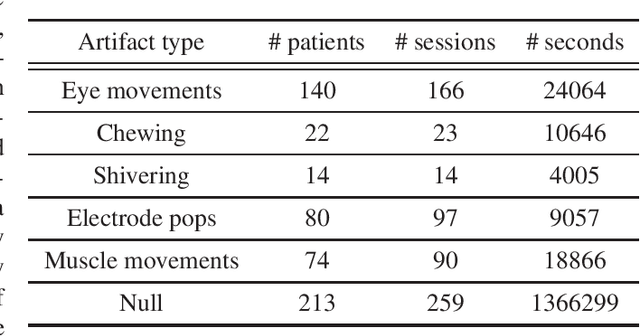
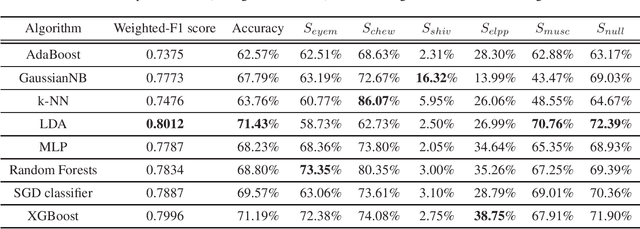
Electroencephalograms (EEG) are often contaminated by artifacts which make interpreting them more challenging for clinicians. Hence, automated artifact recognition systems have the potential to aid the clinical workflow. In this abstract, we share the first results on applying various machine learning algorithms to the recently released world's largest open-source artifact recognition dataset. We envision that these results will serve as a benchmark for researchers who might work with this dataset in future.
A semi-supervised deep learning algorithm for abnormal EEG identification
Mar 19, 2019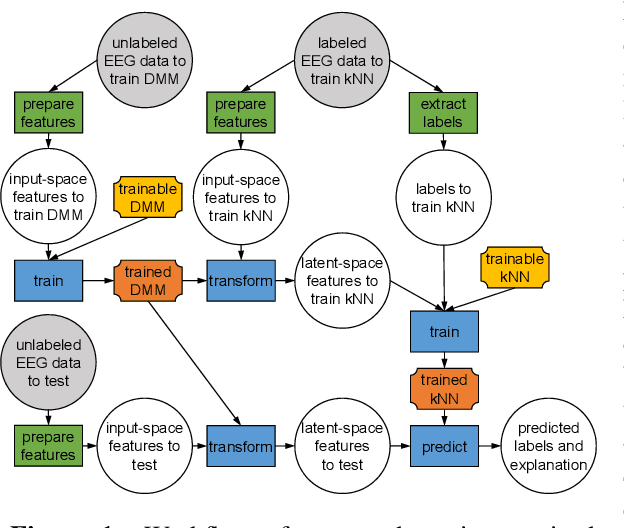
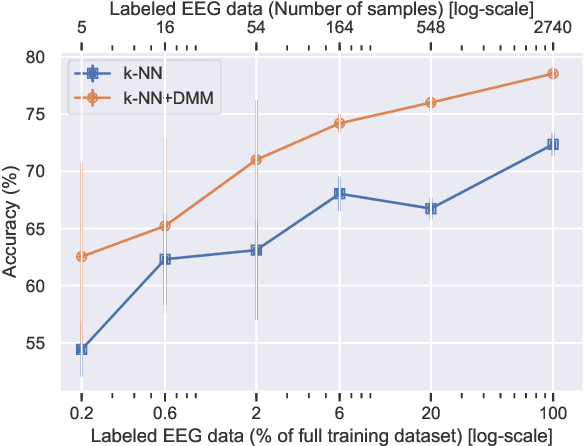
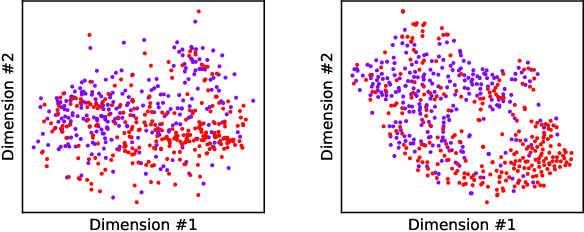
Systems that can automatically analyze EEG signals can aid neurologists by reducing heavy workload and delays. However, such systems need to be first trained using a labeled dataset. While large corpuses of EEG data exist, a fraction of them are labeled. Hand-labeling data increases workload for the very neurologists we try to aid. This paper proposes a semi-supervised learning algorithm that can not only extract meaningful information from large unlabeled EEG datasets but also perform task-specific learning on labeled datasets as small as 5 examples.
SeizureNet: A Deep Convolutional Neural Network for Accurate Seizure Type Classification and Seizure Detection
Mar 08, 2019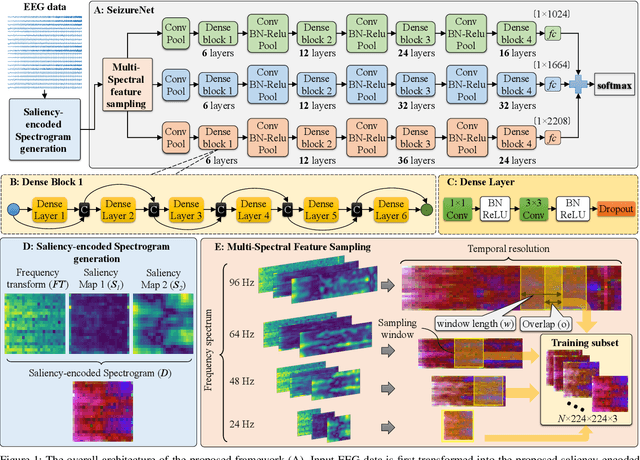

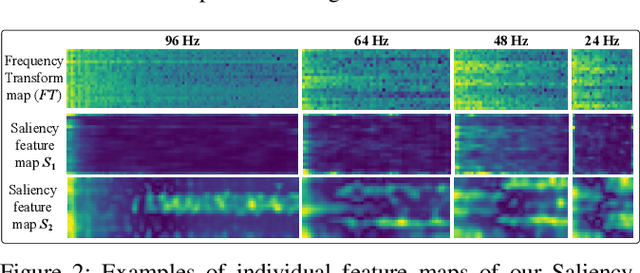
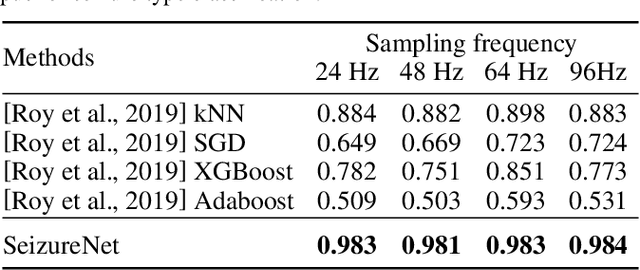
Automatic epileptic seizure analysis is important because the differentiation of neural patterns among different patients can be used to classify people with specific types of epilepsy. This could enable more efficient management of the disease. Automatic seizure type classification using clinical electroencephalograms (EEGs) is challenging due to factors such as low signal to noise ratios, signal artefacts, high variance in the seizure semiology among individual epileptic patients, and limited clinical data constraints. To overcome these challenges, in this paper, we present a deep learning based framework which uses a Convolutional Neural Network (CNN) with dense connections and learns highly robust features at different spatial and temporal resolutions of the EEG data spectrum for accurate cross-patient seizure type classification. We evaluate our framework for seizure type classification and seizure detection on the recently released TUH EEG Seizure Corpus, where our framework achieves overall weighted f 1 scores of up to 0.90 and 0.88, thereby setting new benchmarks on the dataset.
Machine Learning for Seizure Type Classification: Setting the benchmark
Feb 04, 2019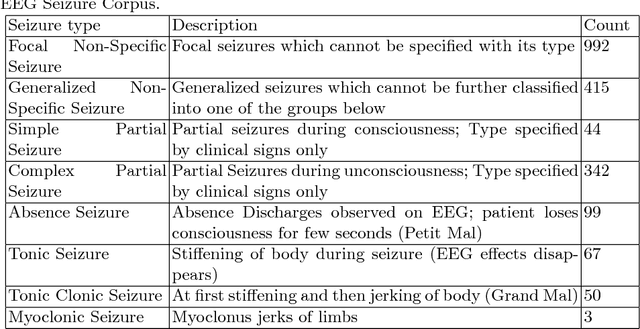
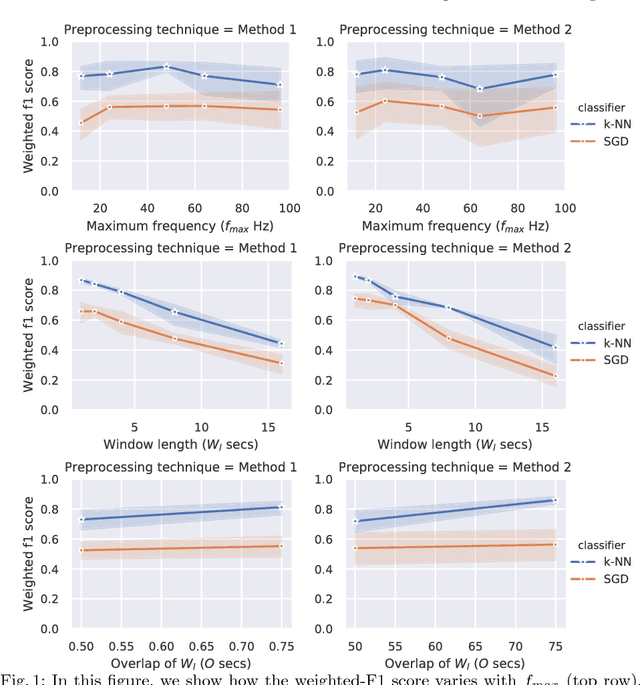
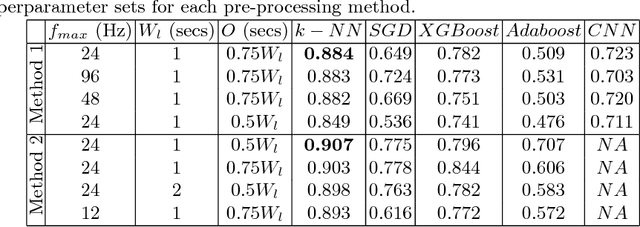
Accurate classification of seizure types plays a crucial role in the treatment and disease management of epileptic patients. Epileptic seizure type not only impacts on the choice of drugs but also on the range of activities a patient can safely engage in. With recent advances being made towards artificial intelligence enabled automatic seizure detection, the next frontier is the automatic classification of seizure types. On that note, in this paper, we undertake the first study to explore the application of machine learning algorithms for multi-class seizure type classification. We used the recently released TUH EEG Seizure Corpus and conducted a thorough search space exploration to evaluate the performance of a combination of various pre-processing techniques, machine learning algorithms, and corresponding hyperparameters on this task. We show that our algorithms can reach a weighted F1 score of up to 0.907 thereby setting the first benchmark for scalp EEG based multi-class seizure type classification.
ChronoNet: A Deep Recurrent Neural Network for Abnormal EEG Identification
May 18, 2018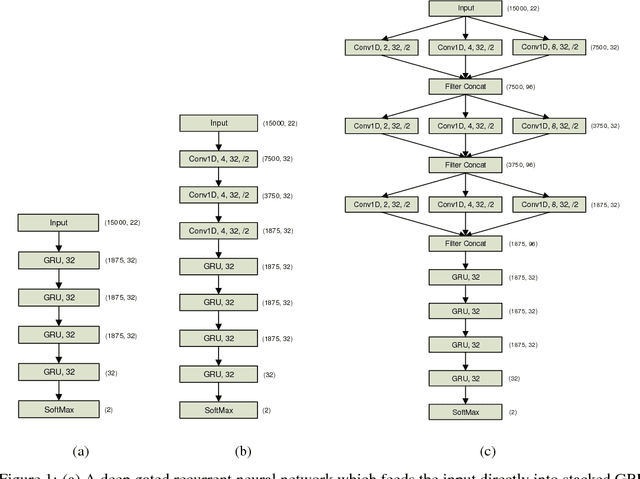

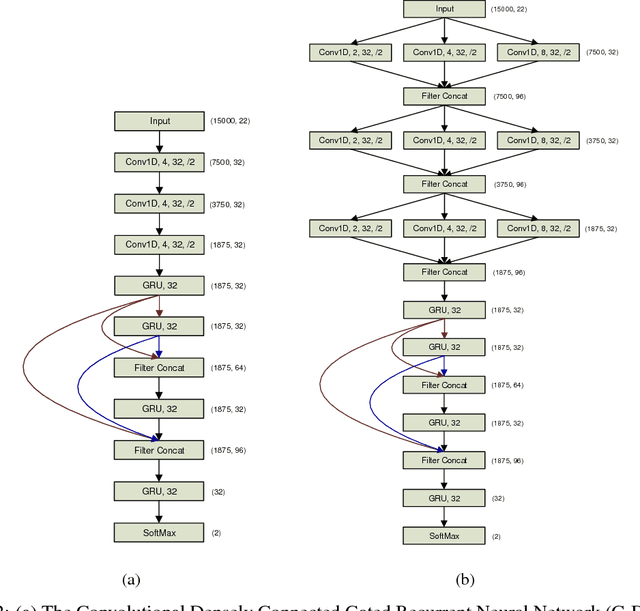
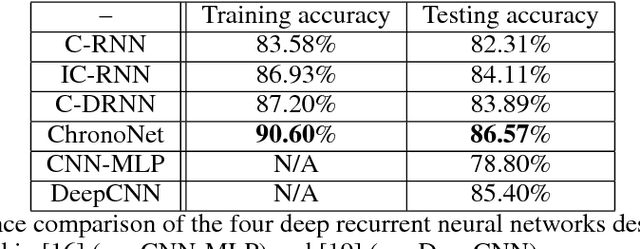
Brain-related disorders such as epilepsy can be diagnosed by analyzing electroencephalograms (EEG). However, manual analysis of EEG data requires highly trained clinicians, and is a procedure that is known to have relatively low inter-rater agreement (IRA). Moreover, the volume of the data and the rate at which new data becomes available make manual interpretation a time-consuming, resource-hungry, and expensive process. In contrast, automated analysis of EEG data offers the potential to improve the quality of patient care by shortening the time to diagnosis and reducing manual error. In this paper, we focus on one of the first steps in interpreting an EEG session - identifying whether the brain activity is abnormal or normal. To solve this task, we propose a novel recurrent neural network (RNN) architecture termed ChronoNet which is inspired by recent developments from the field of image classification and designed to work efficiently with EEG data. ChronoNet is formed by stacking multiple 1D convolution layers followed by deep gated recurrent unit (GRU) layers where each 1D convolution layer uses multiple filters of exponentially varying lengths and the stacked GRU layers are densely connected in a feed-forward manner. We used the recently released TUH Abnormal EEG Corpus dataset for evaluating the performance of ChronoNet. Unlike previous studies using this dataset, ChronoNet directly takes time-series EEG as input and learns meaningful representations of brain activity patterns. ChronoNet outperforms the previously reported best results by 7.79% thereby setting a new benchmark for this dataset. Furthermore, we demonstrate the domain-independent nature of ChronoNet by successfully applying it to classify speech commands.
An Online Structural Plasticity Rule for Generating Better Reservoirs
Apr 19, 2016In this article, a novel neuro-inspired low-resolution online unsupervised learning rule is proposed to train the reservoir or liquid of Liquid State Machine. The liquid is a sparsely interconnected huge recurrent network of spiking neurons. The proposed learning rule is inspired from structural plasticity and trains the liquid through formation and elimination of synaptic connections. Hence, the learning involves rewiring of the reservoir connections similar to structural plasticity observed in biological neural networks. The network connections can be stored as a connection matrix and updated in memory by using Address Event Representation (AER) protocols which are generally employed in neuromorphic systems. On investigating the 'pairwise separation property' we find that trained liquids provide 1.36 $\pm$ 0.18 times more inter-class separation while retaining similar intra-class separation as compared to random liquids. Moreover, analysis of the 'linear separation property' reveals that trained liquids are 2.05 $\pm$ 0.27 times better than random liquids. Furthermore, we show that our liquids are able to retain the 'generalization' ability and 'generality' of random liquids. A memory analysis shows that trained liquids have 83.67 $\pm$ 5.79 ms longer fading memory than random liquids which have shown 92.8 $\pm$ 5.03 ms fading memory for a particular type of spike train inputs. We also throw some light on the dynamics of the evolution of recurrent connections within the liquid. Moreover, compared to 'Separation Driven Synaptic Modification' - a recently proposed algorithm for iteratively refining reservoirs, our learning rule provides 9.30%, 15.21% and 12.52% more liquid separations and 2.8%, 9.1% and 7.9% better classification accuracies for four, eight and twelve class pattern recognition tasks respectively.
An Online Unsupervised Structural Plasticity Algorithm for Spiking Neural Networks
Dec 04, 2015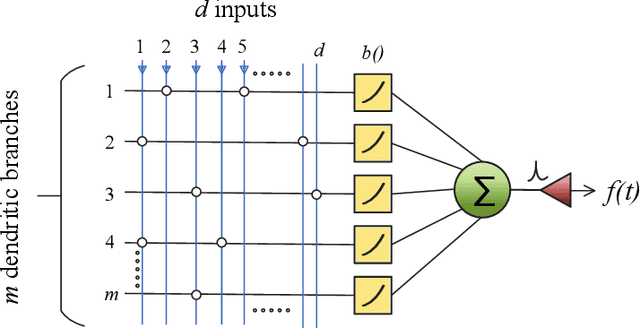
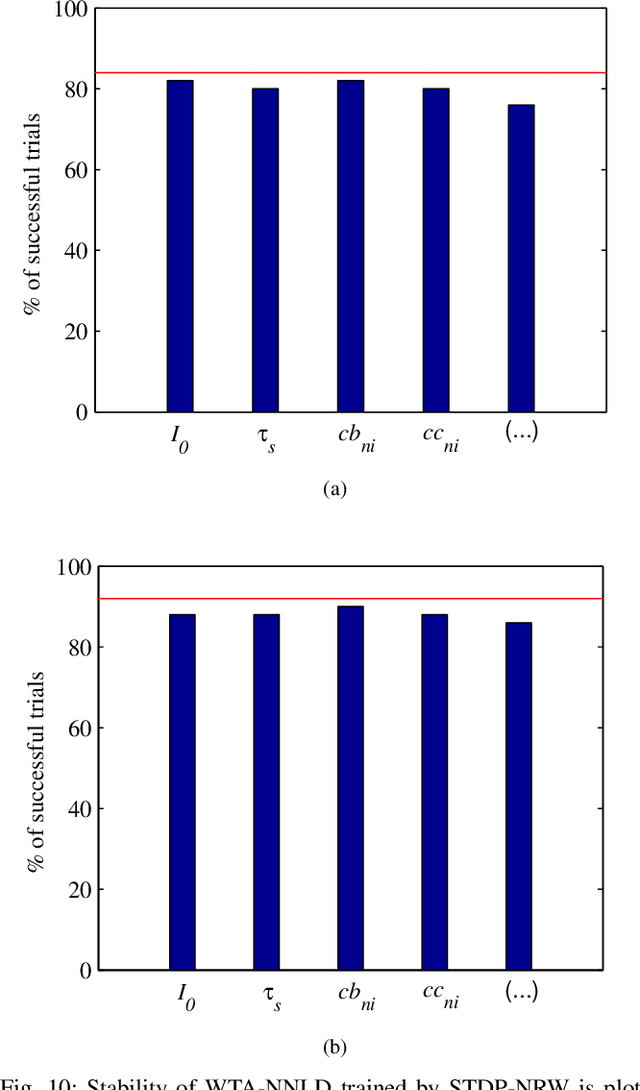
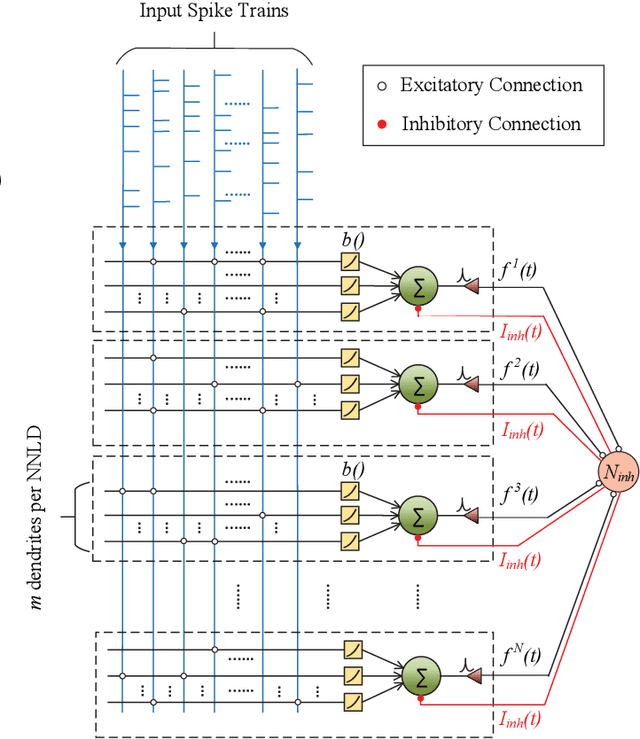
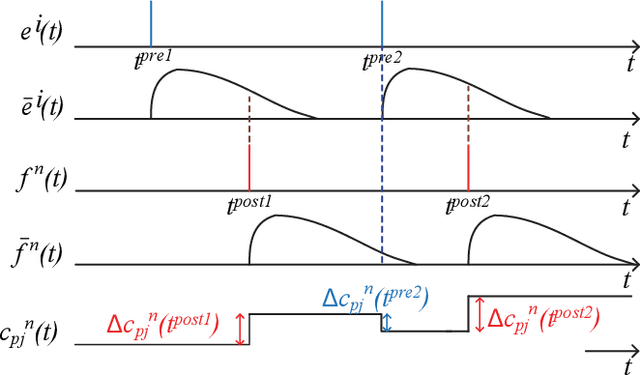
In this article, we propose a novel Winner-Take-All (WTA) architecture employing neurons with nonlinear dendrites and an online unsupervised structural plasticity rule for training it. Further, to aid hardware implementations, our network employs only binary synapses. The proposed learning rule is inspired by spike time dependent plasticity (STDP) but differs for each dendrite based on its activation level. It trains the WTA network through formation and elimination of connections between inputs and synapses. To demonstrate the performance of the proposed network and learning rule, we employ it to solve two, four and six class classification of random Poisson spike time inputs. The results indicate that by proper tuning of the inhibitory time constant of the WTA, a trade-off between specificity and sensitivity of the network can be achieved. We use the inhibitory time constant to set the number of subpatterns per pattern we want to detect. We show that while the percentage of successful trials are 92%, 88% and 82% for two, four and six class classification when no pattern subdivisions are made, it increases to 100% when each pattern is subdivided into 5 or 10 subpatterns. However, the former scenario of no pattern subdivision is more jitter resilient than the later ones.
Learning Spike time codes through Morphological Learning with Binary Synapses
Jun 17, 2015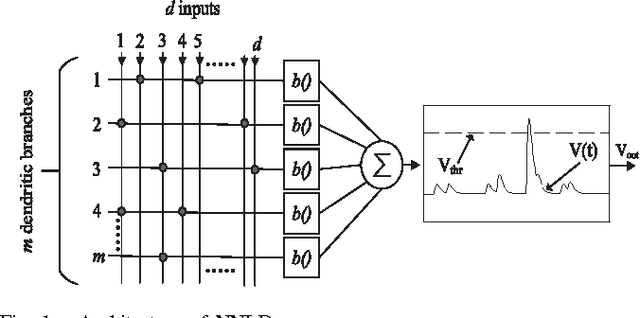
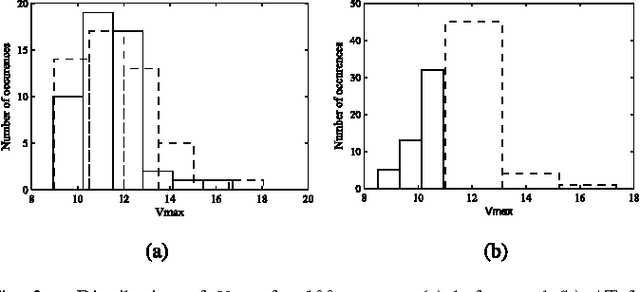
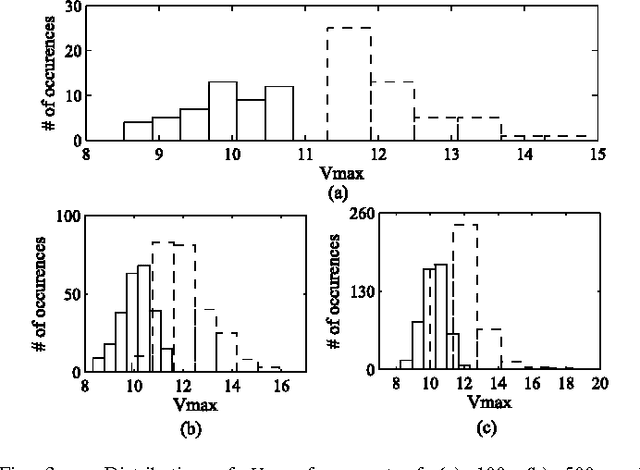
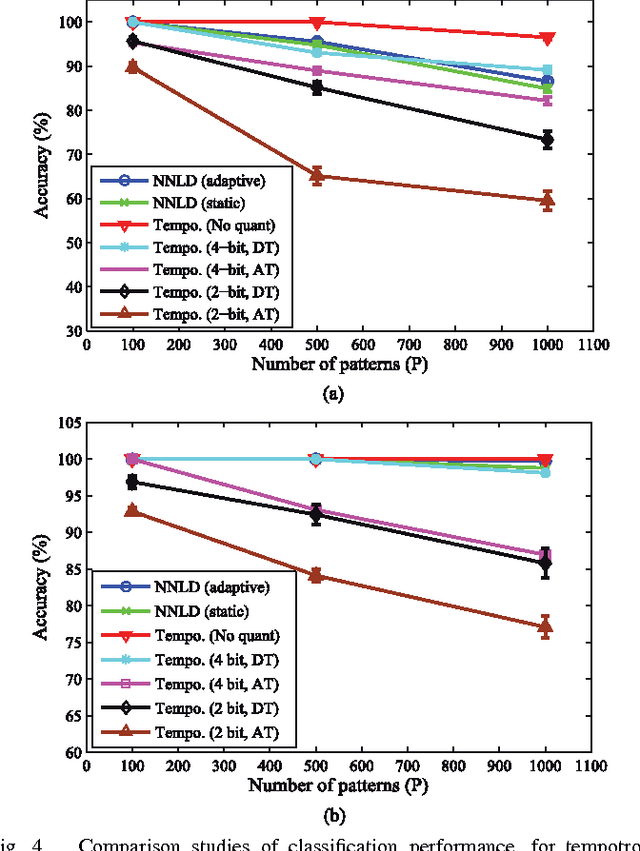
In this paper, a neuron with nonlinear dendrites (NNLD) and binary synapses that is able to learn temporal features of spike input patterns is considered. Since binary synapses are considered, learning happens through formation and elimination of connections between the inputs and the dendritic branches to modify the structure or "morphology" of the NNLD. A morphological learning algorithm inspired by the 'Tempotron', i.e., a recently proposed temporal learning algorithm-is presented in this work. Unlike 'Tempotron', the proposed learning rule uses a technique to automatically adapt the NNLD threshold during training. Experimental results indicate that our NNLD with 1-bit synapses can obtain similar accuracy as a traditional Tempotron with 4-bit synapses in classifying single spike random latency and pair-wise synchrony patterns. Hence, the proposed method is better suited for robust hardware implementation in the presence of statistical variations. We also present results of applying this rule to real life spike classification problems from the field of tactile sensing.