 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound tongue imaging for diarization and alignment of child speech therapy sessions
Aug 15, 2019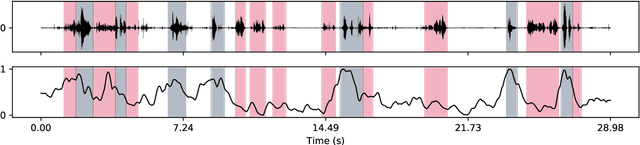
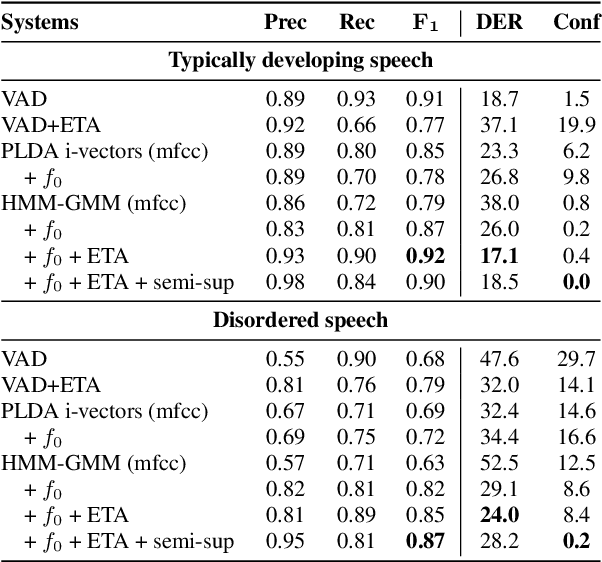
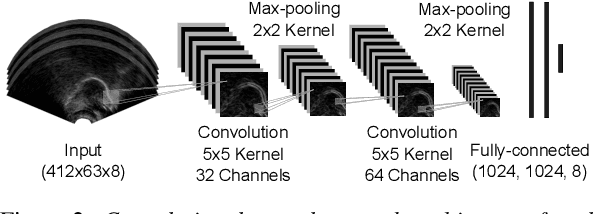
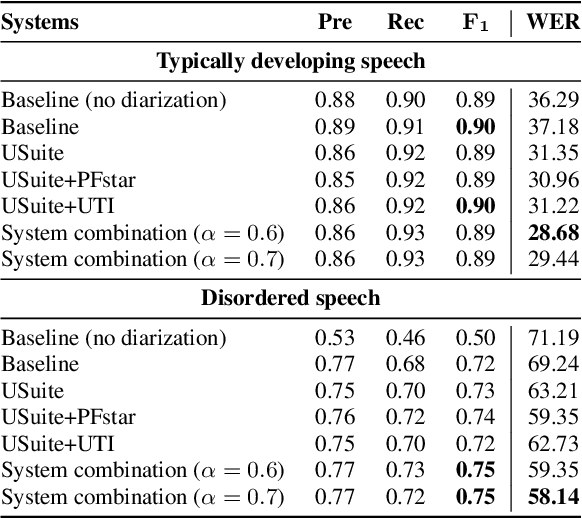
We investigate the automatic processing of child speech therapy sessions using ultrasound visual biofeedback, with a specific focus on complementing acoustic features with ultrasound images of the tongue for the tasks of speaker diarization and time-alignment of target words. For speaker diarization, we propose an ultrasound-based time-domain signal which we call estimated tongue activity. For word-alignment, we augment an acoustic model with low-dimensional representations of ultrasound images of the tongue, learned by a convolutional neural network. We conduct our experiments using the Ultrasuite repository of ultrasound and speech recordings for child speech therapy sessions. For both tasks, we observe that systems augmented with ultrasound data outperform corresponding systems using only the audio signal.
Synchronising audio and ultrasound by learning cross-modal embeddings
Jul 01, 2019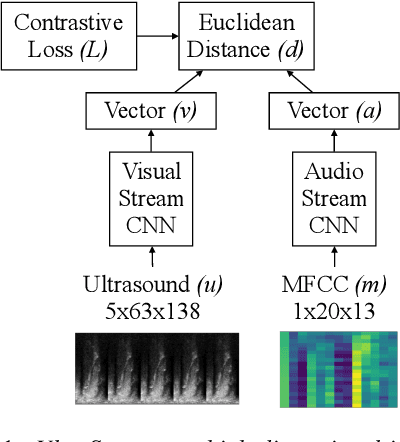
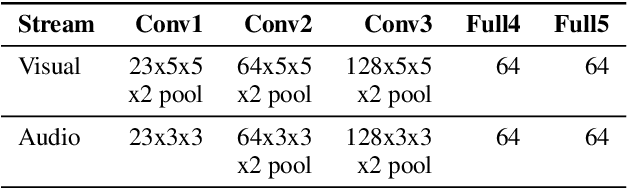
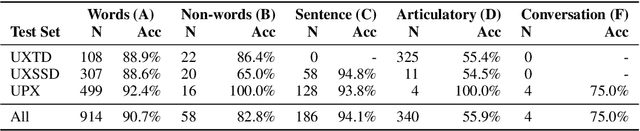
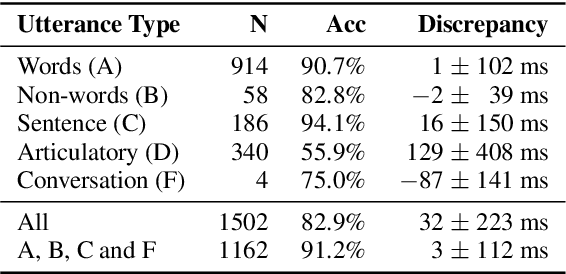
Audiovisual synchronisation is the task of determining the time offset between speech audio and a video recording of the articulators. In child speech therapy, audio and ultrasound videos of the tongue are captured using instruments which rely on hardware to synchronise the two modalities at recording time. Hardware synchronisation can fail in practice, and no mechanism exists to synchronise the signals post hoc. To address this problem, we employ a two-stream neural network which exploits the correlation between the two modalities to find the offset. We train our model on recordings from 69 speakers, and show that it correctly synchronises 82.9% of test utterances from unseen therapy sessions and unseen speakers, thus considerably reducing the number of utterances to be manually synchronised. An analysis of model performance on the test utterances shows that directed phone articulations are more difficult to automatically synchronise compared to utterances containing natural variation in speech such as words, sentences, or conversations.
Speaker-independent classification of phonetic segments from raw ultrasound in child speech
Jul 01, 2019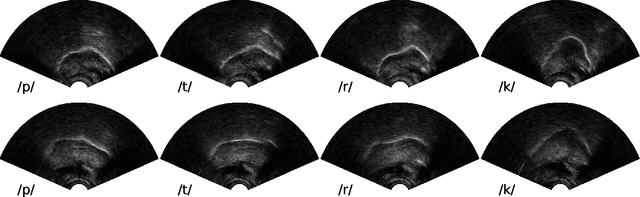
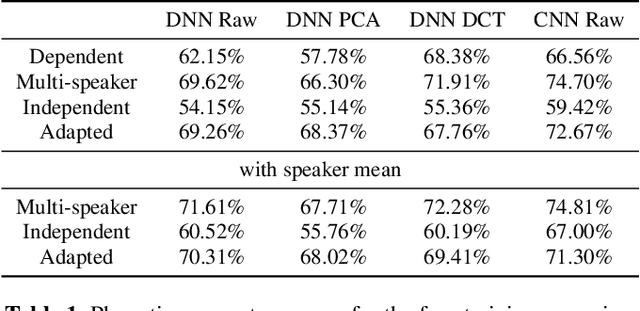

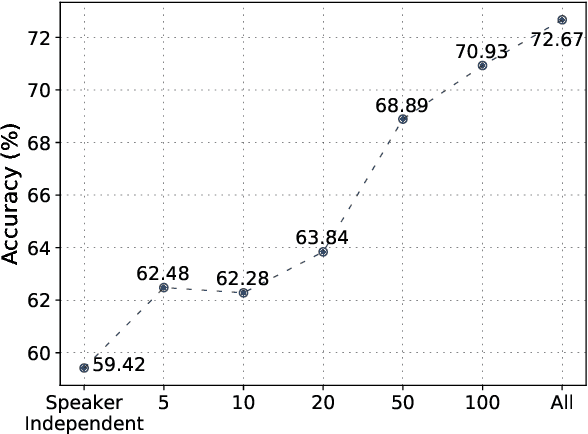
Ultrasound tongue imaging (UTI) provides a convenient way to visualize the vocal tract during speech production. UTI is increasingly being used for speech therapy, making it important to develop automatic methods to assist various time-consuming manual tasks currently performed by speech therapists. A key challenge is to generalize the automatic processing of ultrasound tongue images to previously unseen speakers. In this work, we investigate the classification of phonetic segments (tongue shapes) from raw ultrasound recordings under several training scenarios: speaker-dependent, multi-speaker, speaker-independent, and speaker-adapted. We observe that models underperform when applied to data from speakers not seen at training time. However, when provided with minimal additional speaker information, such as the mean ultrasound frame, the models generalize better to unseen speakers.
Lattice-Based Unsupervised Test-Time Adaptation of Neural Network Acoustic Models
Jun 27, 2019



Acoustic model adaptation to unseen test recordings aims to reduce the mismatch between training and testing conditions. Most adaptation schemes for neural network models require the use of an initial one-best transcription for the test data, generated by an unadapted model, in order to estimate the adaptation transform. It has been found that adaptation methods using discriminative objective functions - such as cross-entropy loss - often require careful regularisation to avoid over-fitting to errors in the one-best transcriptions. In this paper we solve this problem by performing discriminative adaptation using lattices obtained from a first pass decoding, an approach that can be readily integrated into the lattice-free maximum mutual information (LF-MMI) framework. We investigate this approach on three transcription tasks of varying difficulty: TED talks, multi-genre broadcast (MGB) and a low-resource language (Somali). We find that our proposed approach enables many more parameters to be adapted without over-fitting being observed, and is successful even when the initial transcription has a WER in excess of 50%.
Lattice-based lightly-supervised acoustic model training
May 30, 2019
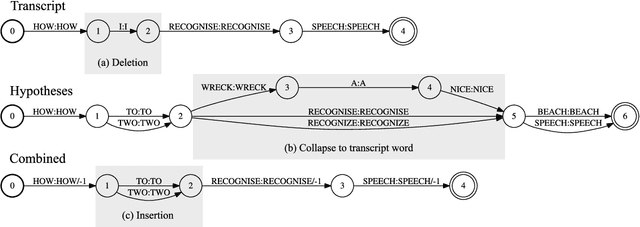
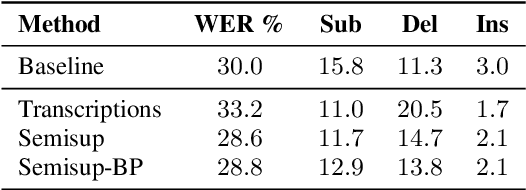
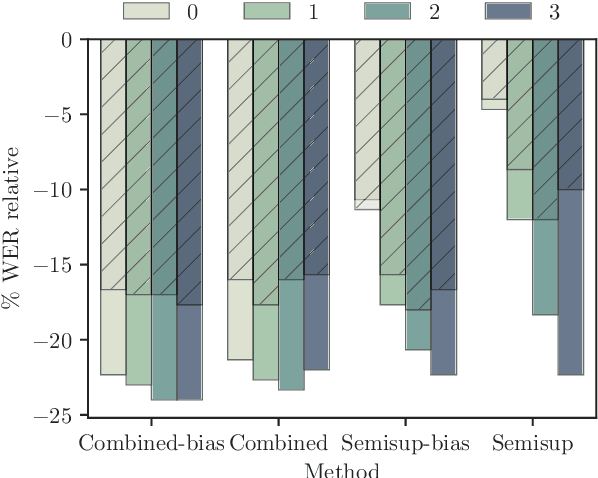
In the broadcast domain there is an abundance of related text data and partial transcriptions, such as closed captions and subtitles. This text data can be used for lightly supervised training, in which text matching the audio is selected using an existing speech recognition model. Current approaches to light supervision typically filter the data based on matching error rates between the transcriptions and biased decoding hypotheses. In contrast, semi-supervised training does not require matching text data, instead generating a hypothesis using a background language model. State-of-the-art semi-supervised training uses lattice-based supervision with the lattice-free MMI (LF-MMI) objective function. We propose a technique to combine inaccurate transcriptions with the lattices generated for semi-supervised training, thus preserving uncertainty in the lattice where appropriate. We demonstrate that this combined approach reduces the expected error rates over the lattices, and reduces the word error rate (WER) on a broadcast task.
Dynamic Evaluation of Transformer Language Models
Apr 17, 2019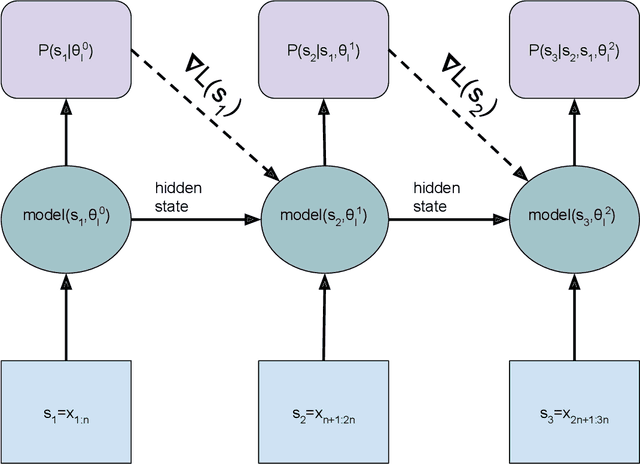
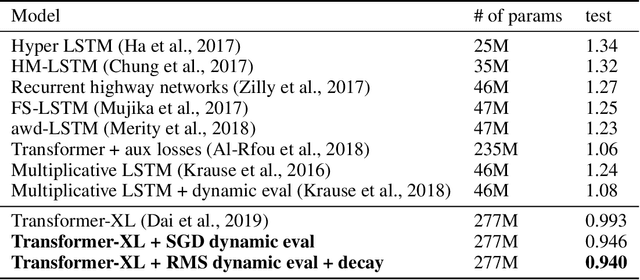


This research note combines two methods that have recently improved the state of the art in language modeling: Transformers and dynamic evaluation. Transformers use stacked layers of self-attention that allow them to capture long range dependencies in sequential data. Dynamic evaluation fits models to the recent sequence history, allowing them to assign higher probabilities to re-occurring sequential patterns. By applying dynamic evaluation to Transformer-XL models, we improve the state of the art on enwik8 from 0.99 to 0.94 bits/char, text8 from 1.08 to 1.04 bits/char, and WikiText-103 from 18.3 to 16.4 perplexity points.
Analyzing deep CNN-based utterance embeddings for acoustic model adaptation
Nov 12, 2018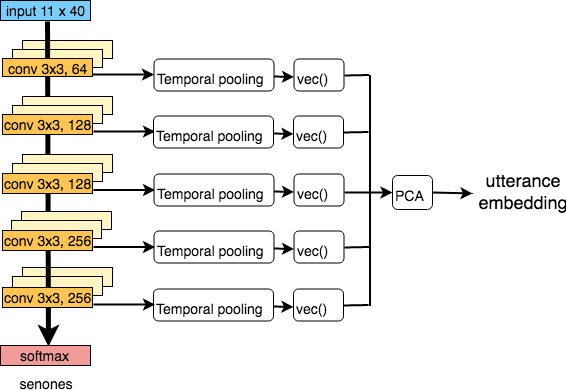
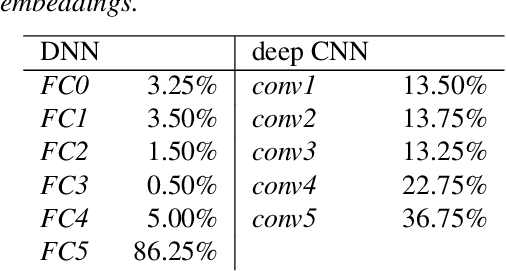
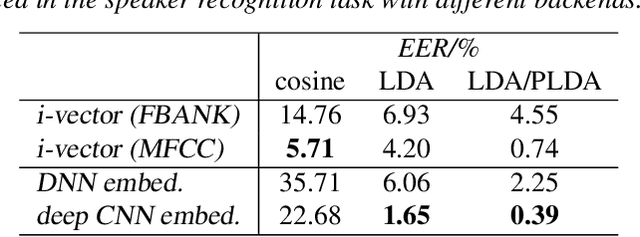
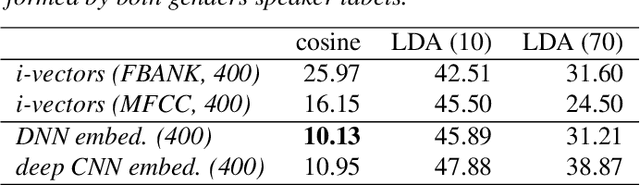
We explore why deep convolutional neural networks (CNNs) with small two-dimensional kernels, primarily used for modeling spatial relations in images, are also effective in speech recognition. We analyze the representations learned by deep CNNs and compare them with deep neural network (DNN) representations and i-vectors, in the context of acoustic model adaptation. To explore whether interpretable information can be decoded from the learned representations we evaluate their ability to discriminate between speakers, acoustic conditions, noise type, and gender using the Aurora-4 dataset. We extract both whole model embeddings (to capture the information learned across the whole network) and layer-specific embeddings which enable understanding of the flow of information across the network. We also use learned representations as the additional input for a time-delay neural network (TDNN) for the Aurora-4 and MGB-3 English datasets. We find that deep CNN embeddings outperform DNN embeddings for acoustic model adaptation and auxiliary features based on deep CNN embeddings result in similar word error rates to i-vectors.
Dynamic Evaluation of Neural Sequence Models
Oct 25, 2017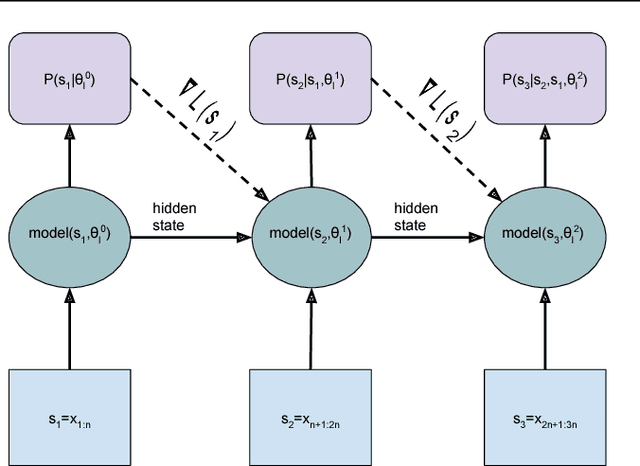
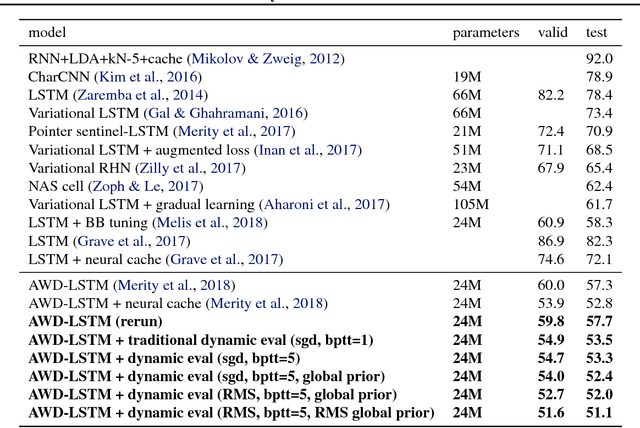
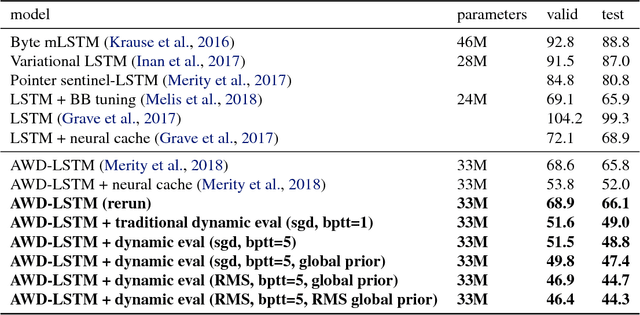
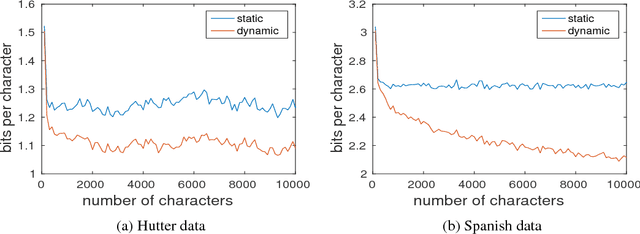
We present methodology for using dynamic evaluation to improve neural sequence models. Models are adapted to recent history via a gradient descent based mechanism, causing them to assign higher probabilities to re-occurring sequential patterns. Dynamic evaluation outperforms existing adaptation approaches in our comparisons. Dynamic evaluation improves the state-of-the-art word-level perplexities on the Penn Treebank and WikiText-2 datasets to 51.1 and 44.3 respectively, and the state-of-the-art character-level cross-entropies on the text8 and Hutter Prize datasets to 1.19 bits/char and 1.08 bits/char respectively.
Multiplicative LSTM for sequence modelling
Oct 12, 2017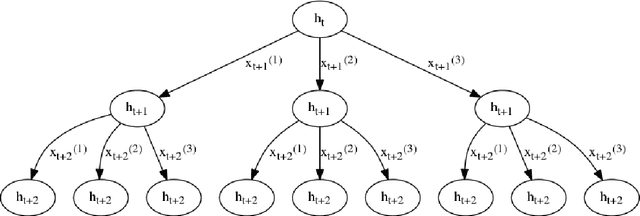
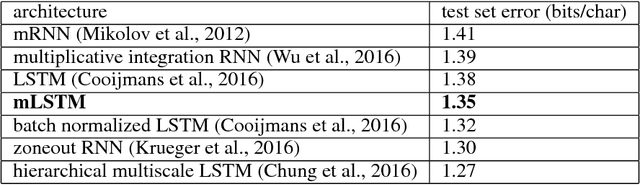
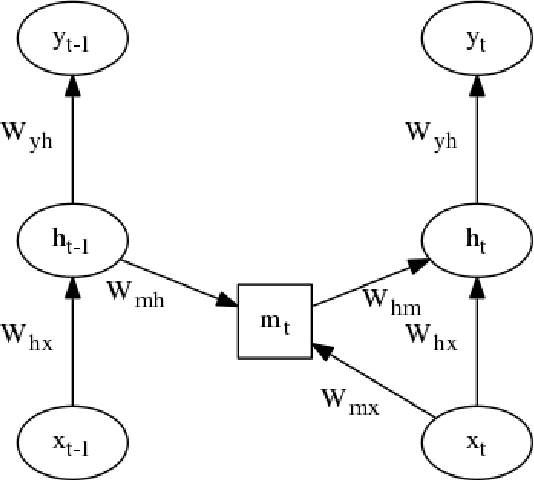

We introduce multiplicative LSTM (mLSTM), a recurrent neural network architecture for sequence modelling that combines the long short-term memory (LSTM) and multiplicative recurrent neural network architectures. mLSTM is characterised by its ability to have different recurrent transition functions for each possible input, which we argue makes it more expressive for autoregressive density estimation. We demonstrate empirically that mLSTM outperforms standard LSTM and its deep variants for a range of character level language modelling tasks. In this version of the paper, we regularise mLSTM to achieve 1.27 bits/char on text8 and 1.24 bits/char on Hutter Prize. We also apply a purely byte-level mLSTM on the WikiText-2 dataset to achieve a character level entropy of 1.26 bits/char, corresponding to a word level perplexity of 88.8, which is comparable to word level LSTMs regularised in similar ways on the same task.
WERd: Using Social Text Spelling Variants for Evaluating Dialectal Speech Recognition
Sep 21, 2017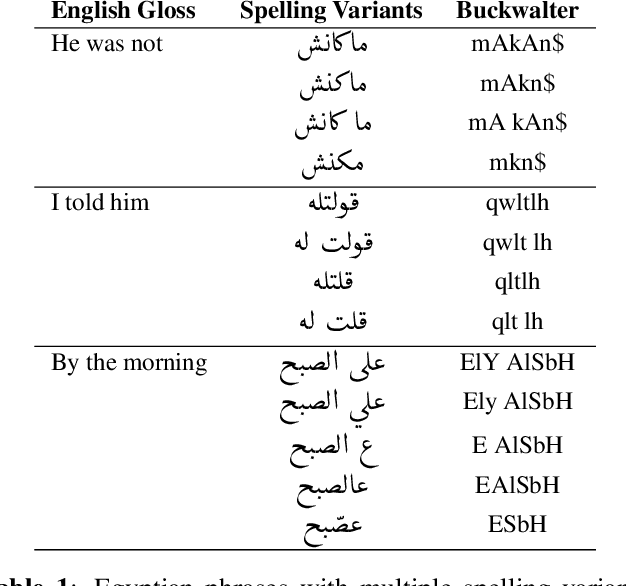
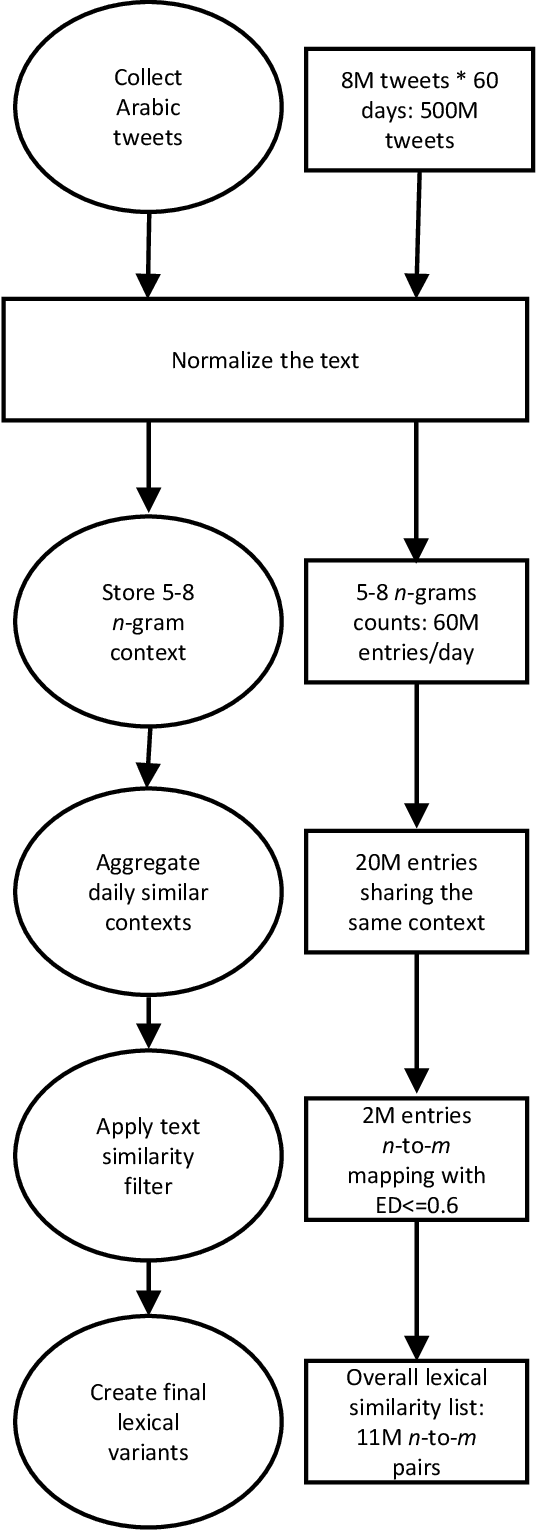
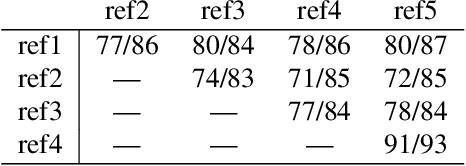
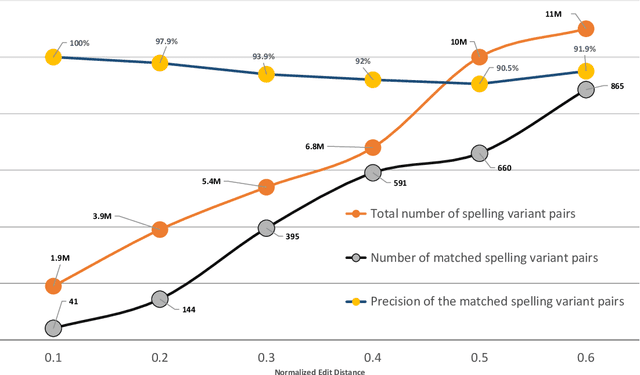
We study the problem of evaluating automatic speech recognition (ASR) systems that target dialectal speech input. A major challenge in this case is that the orthography of dialects is typically not standardized. From an ASR evaluation perspective, this means that there is no clear gold standard for the expected output, and several possible outputs could be considered correct according to different human annotators, which makes standard word error rate (WER) inadequate as an evaluation metric. Such a situation is typical for machine translation (MT), and thus we borrow ideas from an MT evaluation metric, namely TERp, an extension of translation error rate which is closely-related to WER. In particular, in the process of comparing a hypothesis to a reference, we make use of spelling variants for words and phrases, which we mine from Twitter in an unsupervised fashion. Our experiments with evaluating ASR output for Egyptian Arabic, and further manual analysis, show that the resulting WERd (i.e., WER for dialects) metric, a variant of TERp, is more adequate than WER for evaluating dialectal ASR.