 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2CT: Towards 3D CT Volume Generation from Free-text Descriptions Using Diffusion Model
May 07, 2025



Generating 3D CT volumes from descriptive free-text inputs presents a transformative opportunity in diagnostics and research. In this paper, we introduce Text2CT, a novel approach for synthesizing 3D CT volumes from textual descriptions using the diffusion model. Unlike previous methods that rely on fixed-format text input, Text2CT employs a novel prompt formulation that enables generation from diverse, free-text descriptions. The proposed framework encodes medical text into latent representations and decodes them into high-resolution 3D CT scans, effectively bridging the gap between semantic text inputs and detailed volumetric representations in a unified 3D framework. Our method demonstrates superior performance in preserving anatomical fidelity and capturing intricate structures as described in the input text. Extensive evaluations show that our approach achieves state-of-the-art results, offering promising potential applications in diagnostics, and data augmentation.
Multi-Domain Image Completion for Random Missing Input Data
Jul 10, 2020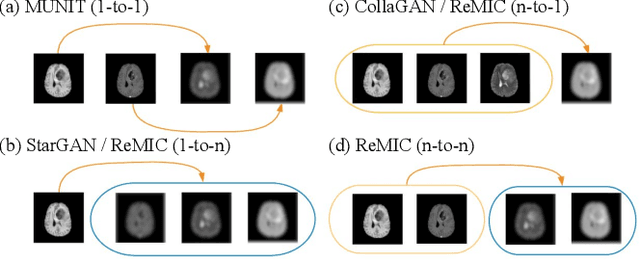
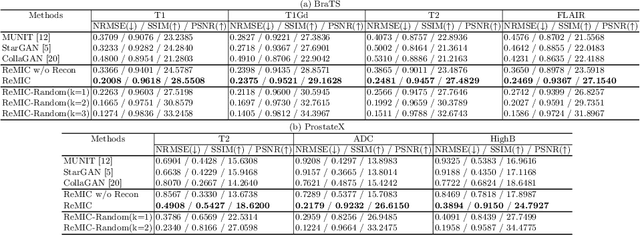
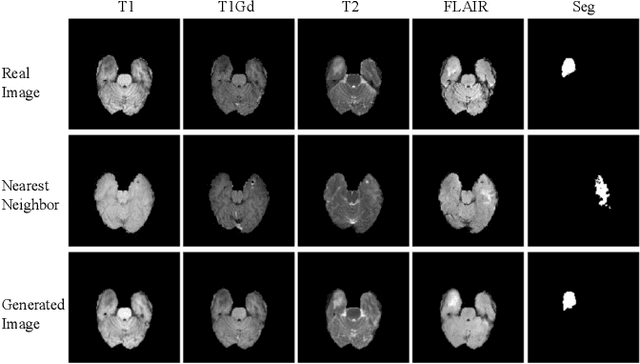
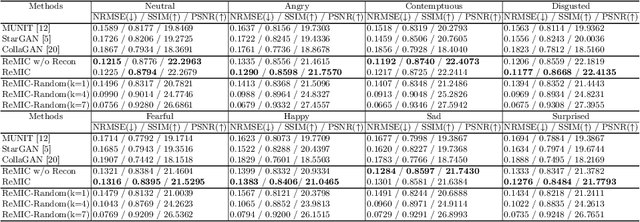
Multi-domain data are widely leveraged in vision applications taking advantage of complementary information from different modalities, e.g., brain tumor segmentation from multi-parametric magnetic resonance imaging (MRI). However, due to possible data corruption and different imaging protocols, the availability of images for each domain could vary amongst multiple data sources in practice, which makes it challenging to build a universal model with a varied set of input data. To tackle this problem, we propose a general approach to complete the random missing domain(s) data in real applications. Specifically, we develop a novel multi-domain image completion method that utilizes a generative adversarial network (GAN) with a representational disentanglement scheme to extract shared skeleton encoding and separate flesh encoding across multiple domains. We further illustrate that the learned representation in multi-domain image completion could be leveraged for high-level tasks, e.g., segmentation, by introducing a unified framework consisting of image completion and segmentation with a shared content encoder. The experiments demonstrate consistent performance improvement on three datasets for brain tumor segmentation, prostate segmentation, and facial expression image completion respectively.