 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Outlier Exposure for Anomaly Detection with Contaminated Data
Feb 20, 2022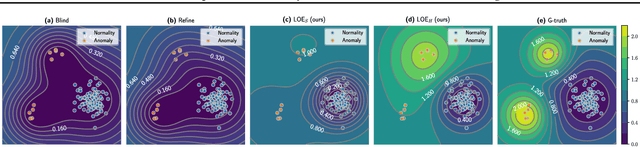
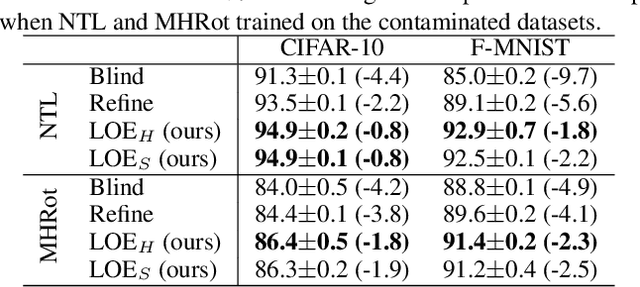
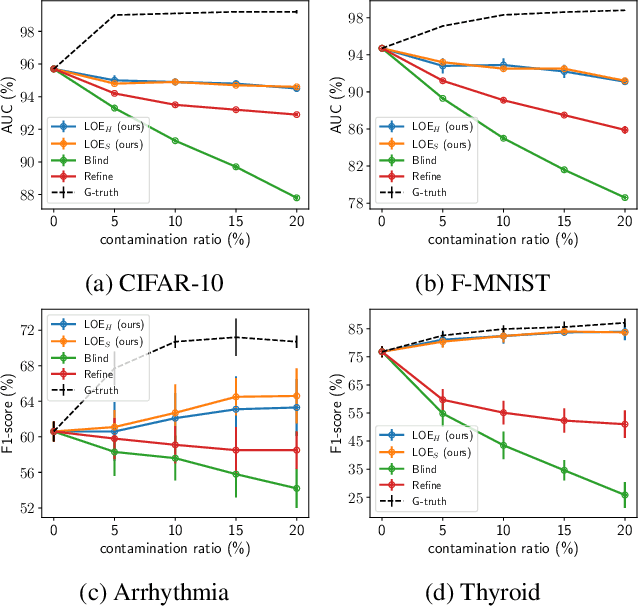
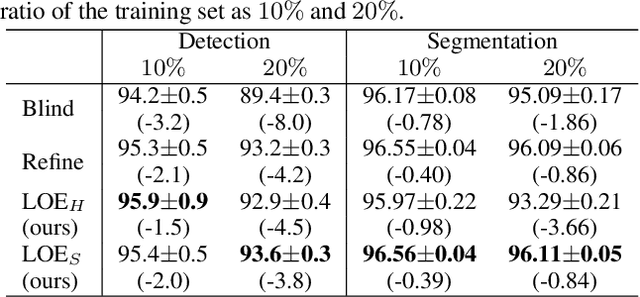
Anomaly detection aims at identifying data points that show systematic deviations from the majority of data in an unlabeled dataset. A common assumption is that clean training data (free of anomalies) is available, which is often violated in practice. We propose a strategy for training an anomaly detector in the presence of unlabeled anomalies that is compatible with a broad class of models. The idea is to jointly infer binary labels to each datum (normal vs. anomalous) while updating the model parameters. Inspired by outlier exposure (Hendrycks et al., 2018) that considers synthetically created, labeled anomalies, we thereby use a combination of two losses that share parameters: one for the normal and one for the anomalous data. We then iteratively proceed with block coordinate updates on the parameters and the most likely (latent) labels. Our experiments with several backbone models on three image datasets, 30 tabular data sets, and a video anomaly detection benchmark showed consistent and significant improvements over the baselines.
Hybridizing Physical and Data-driven Prediction Methods for Physicochemical Properties
Feb 17, 2022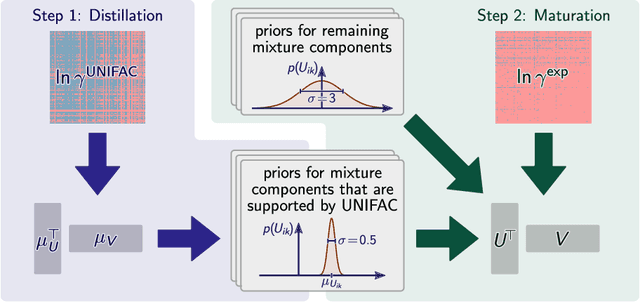
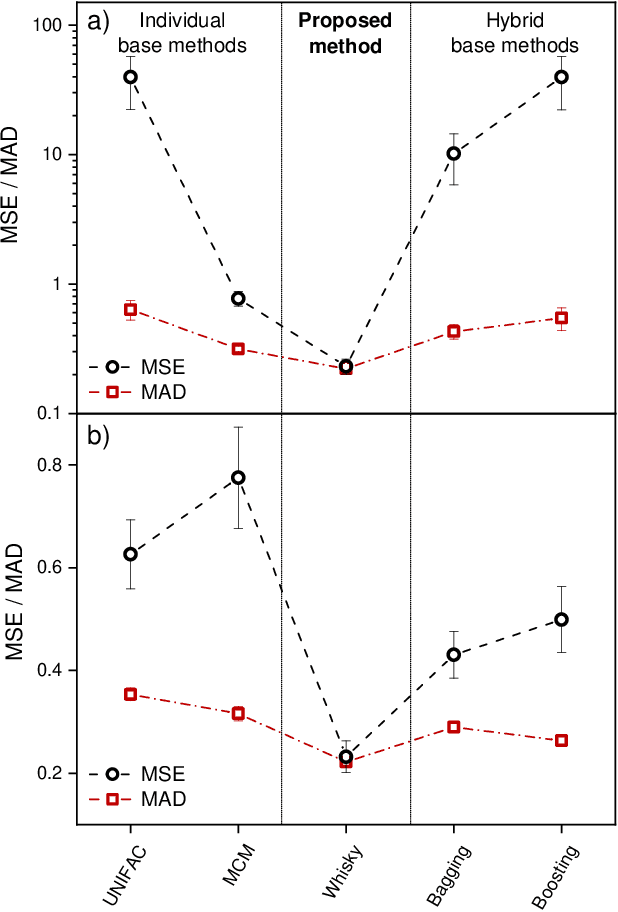
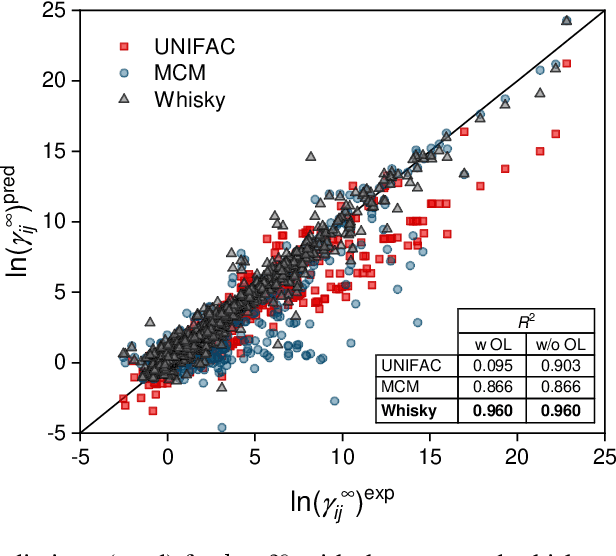
We present a generic way to hybridize physical and data-driven methods for predicting physicochemical properties. The approach `distills' the physical method's predictions into a prior model and combines it with sparse experimental data using Bayesian inference. We apply the new approach to predict activity coefficients at infinite dilution and obtain significant improvements compared to the data-driven and physical baselines and established ensemble methods from the machine learning literature.
* Published version
An Introduction to Neural Data Compression
Feb 14, 2022



Neural compression is the application of neural networks and other machine learning methods to data compression. While machine learning deals with many concepts closely related to compression, entering the field of neural compression can be difficult due to its reliance on information theory, perceptual metrics, and other knowledge specific to the field. This introduction hopes to fill in the necessary background by reviewing basic coding topics such as entropy coding and rate-distortion theory, related machine learning ideas such as bits-back coding and perceptual metrics, and providing a guide through the representative works in the literature so far.
Detecting Anomalies within Time Series using Local Neural Transformations
Feb 08, 2022We develop a new method to detect anomalies within time series, which is essential in many application domains, reaching from self-driving cars, finance, and marketing to medical diagnosis and epidemiology. The method is based on self-supervised deep learning that has played a key role in facilitating deep anomaly detection on images, where powerful image transformations are available. However, such transformations are widely unavailable for time series. Addressing this, we develop Local Neural Transformations(LNT), a method learning local transformations of time series from data. The method produces an anomaly score for each time step and thus can be used to detect anomalies within time series. We prove in a theoretical analysis that our novel training objective is more suitable for transformation learning than previous deep Anomaly detection(AD) methods. Our experiments demonstrate that LNT can find anomalies in speech segments from the LibriSpeech data set and better detect interruptions to cyber-physical systems than previous work. Visualization of the learned transformations gives insight into the type of transformations that LNT learns.
Analyzing High-Resolution Clouds and Convection using Multi-Channel VAEs
Dec 01, 2021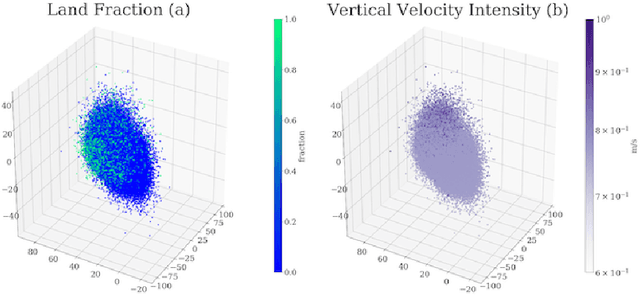
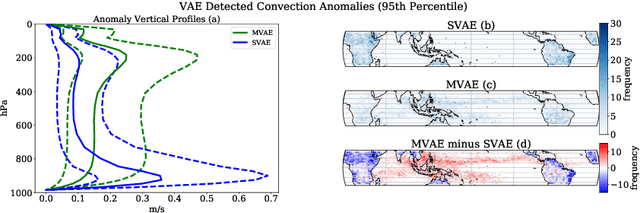
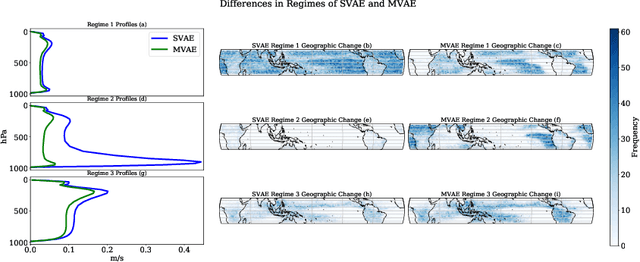
Understanding the details of small-scale convection and storm formation is crucial to accurately represent the larger-scale planetary dynamics. Presently, atmospheric scientists run high-resolution, storm-resolving simulations to capture these kilometer-scale weather details. However, because they contain abundant information, these simulations can be overwhelming to analyze using conventional approaches. This paper takes a data-driven approach and jointly embeds spatial arrays of vertical wind velocities, temperatures, and water vapor information as three "channels" of a VAE architecture. Our "multi-channel VAE" results in more interpretable and robust latent structures than earlier work analyzing vertical velocities in isolation. Analyzing and clustering the VAE's latent space identifies weather patterns and their geographical manifestations in a fully unsupervised fashion. Our approach shows that VAEs can play essential roles in analyzing high-dimensional simulation data and extracting critical weather and climate characteristics.
Towards Empirical Sandwich Bounds on the Rate-Distortion Function
Nov 23, 2021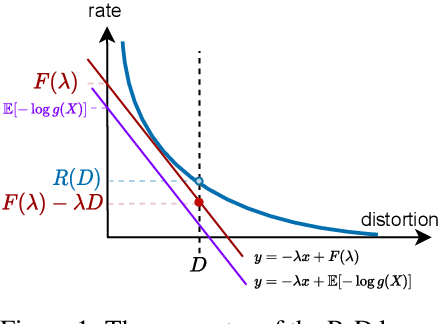
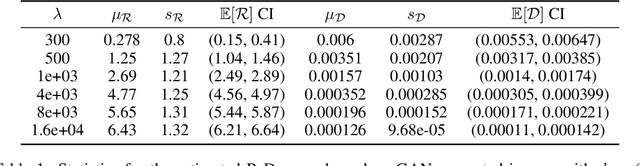
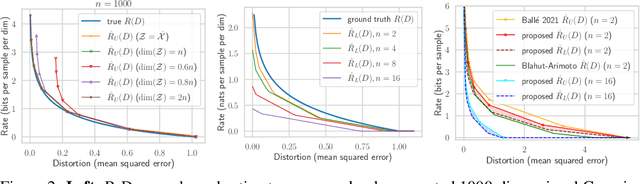
Rate-distortion (R-D) function, a key quantity in information theory, characterizes the fundamental limit of how much a data source can be compressed subject to a fidelity criterion, by any compression algorithm. As researchers push for ever-improving compression performance, establishing the R-D function of a given data source is not only of scientific interest, but also sheds light on the possible room for improving compression algorithms. Previous work on this problem relied on distributional assumptions on the data source (Gibson, 2017) or only applied to discrete data. By contrast, this paper makes the first attempt at an algorithm for sandwiching the R-D function of a general (not necessarily discrete) source requiring only i.i.d. data samples. We estimate R-D sandwich bounds on Gaussian and high-dimension banana-shaped sources, as well as GAN-generated images. Our R-D upper bound on natural images indicates room for improving the performance of state-of-the-art image compression methods by 1 dB in PSNR at various bitrates.
Lossless Compression with Probabilistic Circuits
Nov 23, 2021
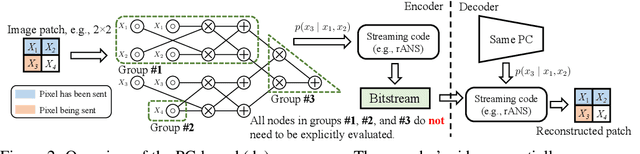
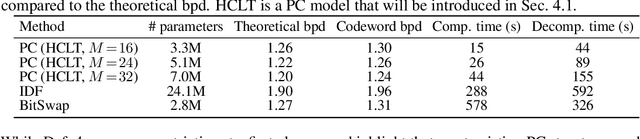
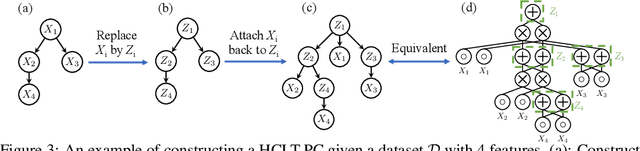
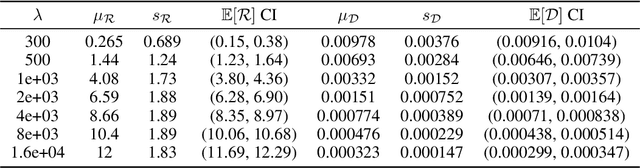
Despite extensive progress on image generation, deep generative models are suboptimal when applied to lossless compression. For example, models such as VAEs suffer from a compression cost overhead due to their latent variables that can only be partially eliminated with elaborated schemes such as bits-back coding, resulting in oftentimes poor single-sample compression rates. To overcome such problems, we establish a new class of tractable lossless compression models that permit efficient encoding and decoding: Probabilistic Circuits (PCs). These are a class of neural networks involving $|p|$ computational units that support efficient marginalization over arbitrary subsets of the $D$ feature dimensions, enabling efficient arithmetic coding. We derive efficient encoding and decoding schemes that both have time complexity $\mathcal{O} (\log(D) \cdot |p|)$, where a naive scheme would have linear costs in $D$ and $|p|$, making the approach highly scalable. Empirically, our PC-based (de)compression algorithm runs 5-20x faster than neural compression algorithms that achieve similar bitrates. By scaling up the traditional PC structure learning pipeline, we achieved state-of-the-art results on image datasets such as MNIST. Furthermore, PCs can be naturally integrated with existing neural compression algorithms to improve the performance of these base models on natural image datasets. Our results highlight the potential impact that non-standard learning architectures may have on neural data compression.
Supervised Compression for Resource-constrained Edge Computing Systems
Aug 21, 2021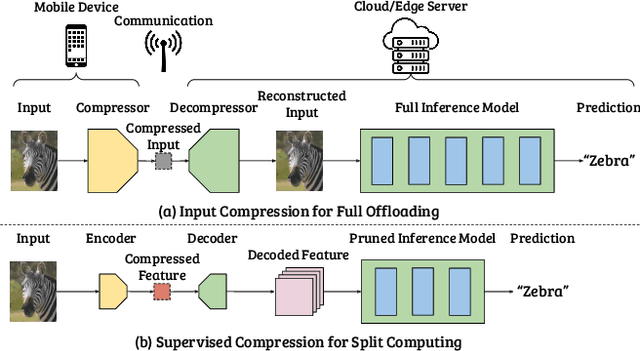
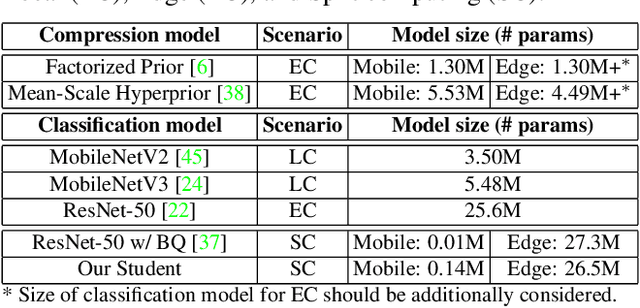
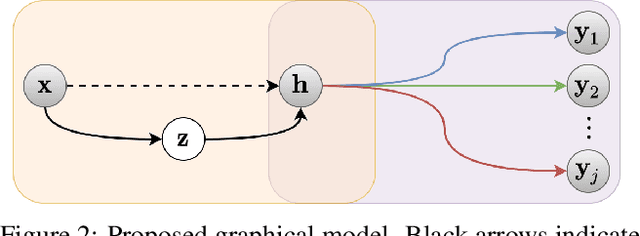
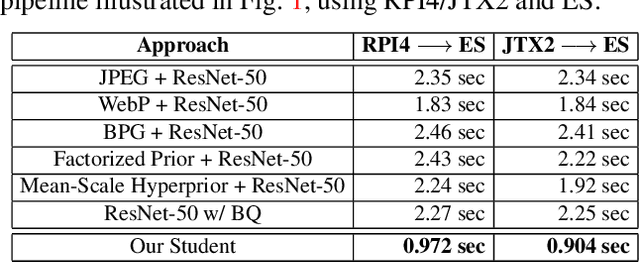
There has been much interest in deploying deep learning algorithms on low-powered devices, including smartphones, drones, and medical sensors. However, full-scale deep neural networks are often too resource-intensive in terms of energy and storage. As a result, the bulk part of the machine learning operation is therefore often carried out on an edge server, where the data is compressed and transmitted. However, compressing data (such as images) leads to transmitting information irrelevant to the supervised task. Another popular approach is to split the deep network between the device and the server while compressing intermediate features. To date, however, such split computing strategies have barely outperformed the aforementioned naive data compression baselines due to their inefficient approaches to feature compression. This paper adopts ideas from knowledge distillation and neural image compression to compress intermediate feature representations more efficiently. Our supervised compression approach uses a teacher model and a student model with a stochastic bottleneck and learnable prior for entropy coding. We compare our approach to various neural image and feature compression baselines in three vision tasks and found that it achieves better supervised rate-distortion performance while also maintaining smaller end-to-end latency. We furthermore show that the learned feature representations can be tuned to serve multiple downstream tasks.
Insights from Generative Modeling for Neural Video Compression
Jul 28, 2021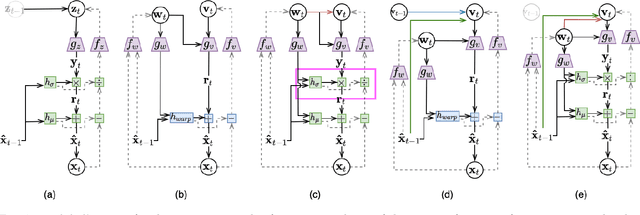



While recent machine learning research has revealed connections between deep generative models such as VAEs and rate-distortion losses used in learned compression, most of this work has focused on images. In a similar spirit, we view recently proposed neural video coding algorithms through the lens of deep autoregressive and latent variable modeling. We present recent neural video codecs as instances of a generalized stochastic temporal autoregressive transform, and propose new avenues for further improvements inspired by normalizing flows and structured priors. We propose several architectures that yield state-of-the-art video compression performance on full-resolution video and discuss their tradeoffs and ablations. In particular, we propose (i) improved temporal autoregressive transforms, (ii) improved entropy models with structured and temporal dependencies, and (iii) variable bitrate versions of our algorithms. Since our improvements are compatible with a large class of existing models, we provide further evidence that the generative modeling viewpoint can advance the neural video coding field.
Structured Stochastic Gradient MCMC
Jul 19, 2021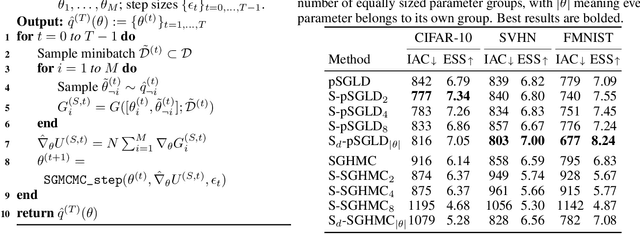
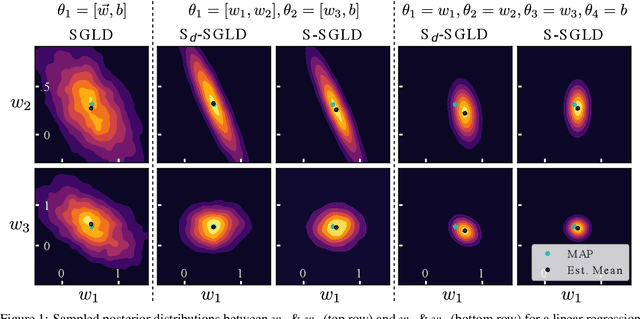

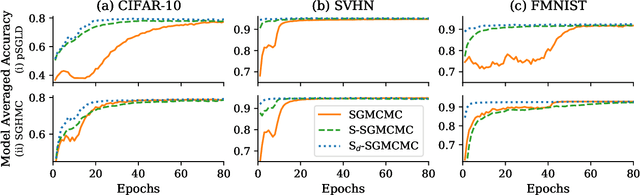
Stochastic gradient Markov chain Monte Carlo (SGMCMC) is considered the gold standard for Bayesian inference in large-scale models, such as Bayesian neural networks. Since practitioners face speed versus accuracy tradeoffs in these models, variational inference (VI) is often the preferable option. Unfortunately, VI makes strong assumptions on both the factorization and functional form of the posterior. In this work, we propose a new non-parametric variational approximation that makes no assumptions about the approximate posterior's functional form and allows practitioners to specify the exact dependencies the algorithm should respect or break. The approach relies on a new Langevin-type algorithm that operates on a modified energy function, where parts of the latent variables are averaged over samples from earlier iterations of the Markov chain. This way, statistical dependencies can be broken in a controlled way, allowing the chain to mix faster. This scheme can be further modified in a ''dropout'' manner, leading to even more scalability. By implementing the scheme on a ResNet-20 architecture, we obtain better predictive likelihoods and larger effective sample sizes than full SGMCMC.