 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead2Head: Video-based Neural Head Synthesis
May 22, 2020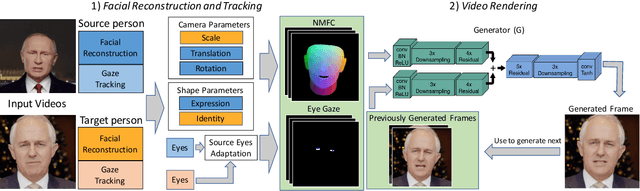

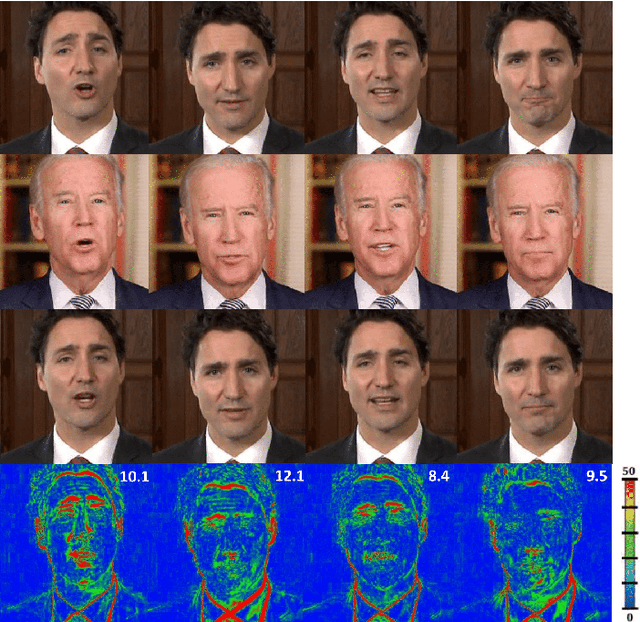

In this paper, we propose a novel machine learning architecture for facial reenactment. In particular, contrary to the model-based approaches or recent frame-based methods that use Deep Convolutional Neural Networks (DCNNs) to generate individual frames, we propose a novel method that (a) exploits the special structure of facial motion (paying particular attention to mouth motion) and (b) enforces temporal consistency. We demonstrate that the proposed method can transfer facial expressions, pose and gaze of a source actor to a target video in a photo-realistic fashion more accurately than state-of-the-art methods.
DeepFaceFlow: In-the-wild Dense 3D Facial Motion Estimation
May 14, 2020
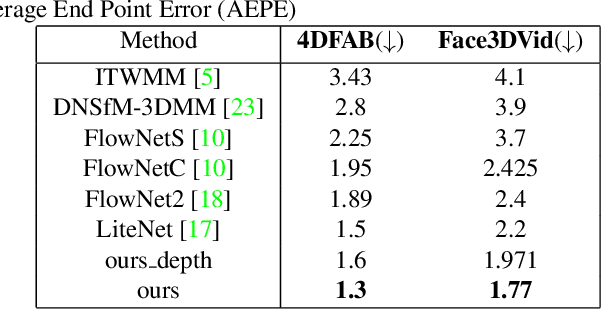
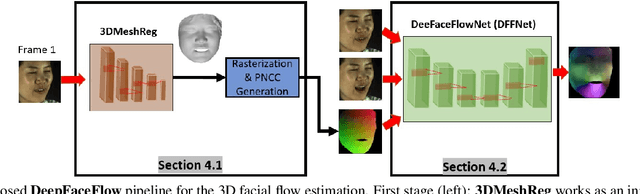
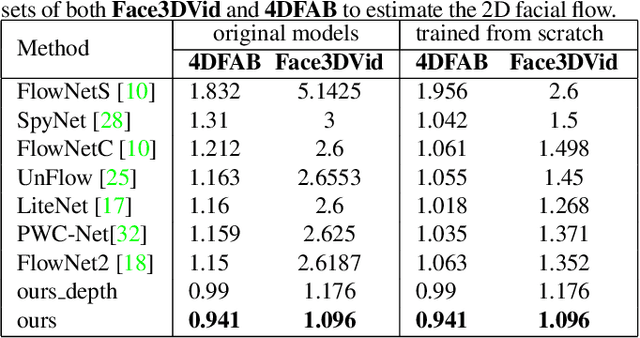
Dense 3D facial motion capture from only monocular in-the-wild pairs of RGB images is a highly challenging problem with numerous applications, ranging from facial expression recognition to facial reenactment. In this work, we propose DeepFaceFlow, a robust, fast, and highly-accurate framework for the dense estimation of 3D non-rigid facial flow between pairs of monocular images. Our DeepFaceFlow framework was trained and tested on two very large-scale facial video datasets, one of them of our own collection and annotation, with the aid of occlusion-aware and 3D-based loss function. We conduct comprehensive experiments probing different aspects of our approach and demonstrating its improved performance against state-of-the-art flow and 3D reconstruction methods. Furthermore, we incorporate our framework in a full-head state-of-the-art facial video synthesis method and demonstrate the ability of our method in better representing and capturing the facial dynamics, resulting in a highly-realistic facial video synthesis. Given registered pairs of images, our framework generates 3D flow maps at ~60 fps.
Geometrically Principled Connections in Graph Neural Networks
Apr 06, 2020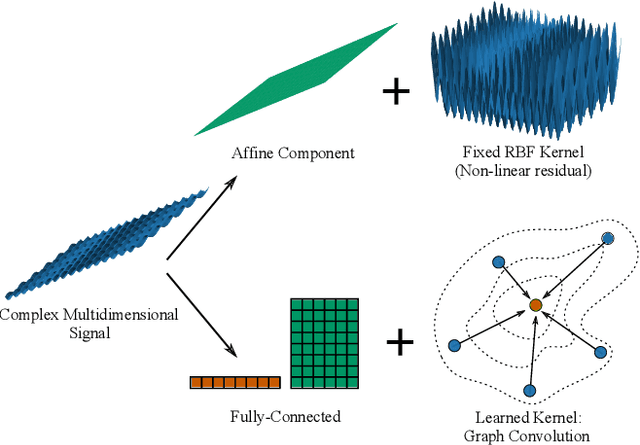
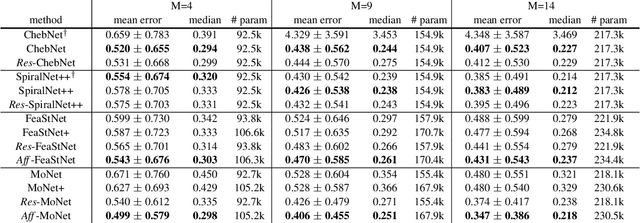
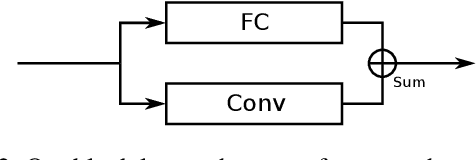
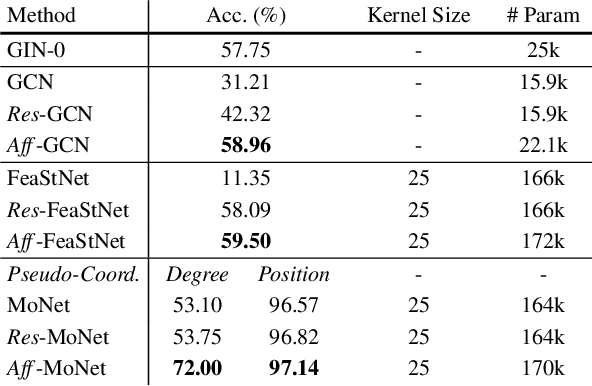
Graph convolution operators bring the advantages of deep learning to a variety of graph and mesh processing tasks previously deemed out of reach. With their continued success comes the desire to design more powerful architectures, often by adapting existing deep learning techniques to non-Euclidean data. In this paper, we argue geometry should remain the primary driving force behind innovation in the emerging field of geometric deep learning. We relate graph neural networks to widely successful computer graphics and data approximation models: radial basis functions (RBFs). We conjecture that, like RBFs, graph convolution layers would benefit from the addition of simple functions to the powerful convolution kernels. We introduce affine skip connections, a novel building block formed by combining a fully connected layer with any graph convolution operator. We experimentally demonstrate the effectiveness of our technique and show the improved performance is the consequence of more than the increased number of parameters. Operators equipped with the affine skip connection markedly outperform their base performance on every task we evaluated, i.e., shape reconstruction, dense shape correspondence, and graph classification. We hope our simple and effective approach will serve as a solid baseline and help ease future research in graph neural networks.
Weakly-Supervised Mesh-Convolutional Hand Reconstruction in the Wild
Apr 04, 2020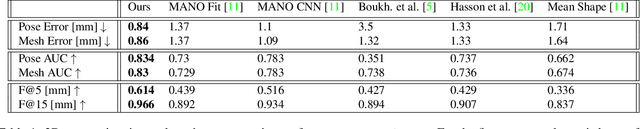
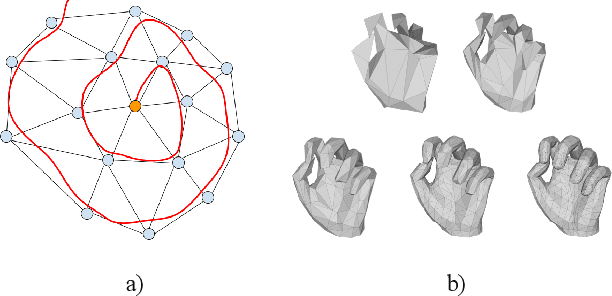
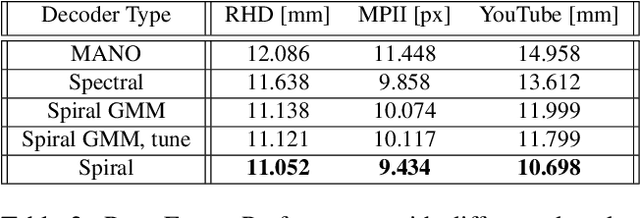

We introduce a simple and effective network architecture for monocular 3D hand pose estimation consisting of an image encoder followed by a mesh convolutional decoder that is trained through a direct 3D hand mesh reconstruction loss. We train our network by gathering a large-scale dataset of hand action in YouTube videos and use it as a source of weak supervision. Our weakly-supervised mesh convolutions-based system largely outperforms state-of-the-art methods, even halving the errors on the in the wild benchmark. The dataset and additional resources are available at https://arielai.com/mesh_hands.
AvatarMe: Realistically Renderable 3D Facial Reconstruction "in-the-wild"
Mar 30, 2020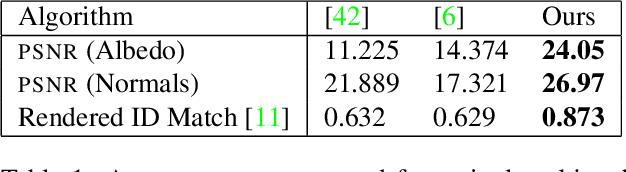


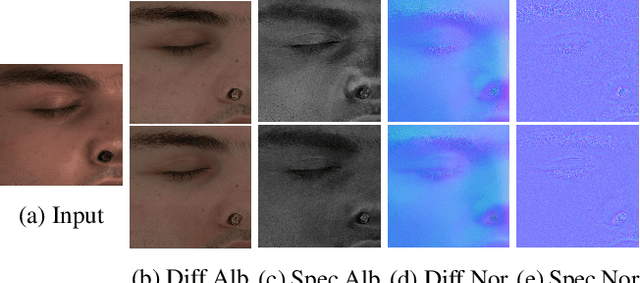
Over the last years, with the advent of Generative Adversarial Networks (GANs), many face analysis tasks have accomplished astounding performance, with applications including, but not limited to, face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce high-resolution photorealistic 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this paper, we introduce AvatarMe, the first method that is able to reconstruct photorealistic 3D faces from a single "in-the-wild" image with an increasing level of detail. To achieve this, we capture a large dataset of facial shape and reflectance and build on a state-of-the-art 3D texture and shape reconstruction method and successively refine its results, while generating the per-pixel diffuse and specular components that are required for realistic rendering. As we demonstrate in a series of qualitative and quantitative experiments, AvatarMe outperforms the existing arts by a significant margin and reconstructs authentic, 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
$Π-$nets: Deep Polynomial Neural Networks
Mar 26, 2020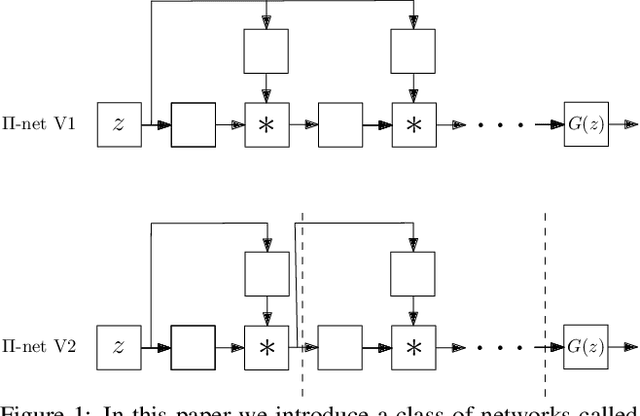
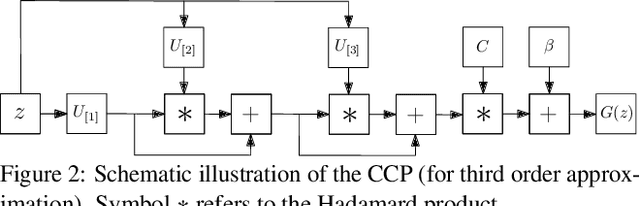
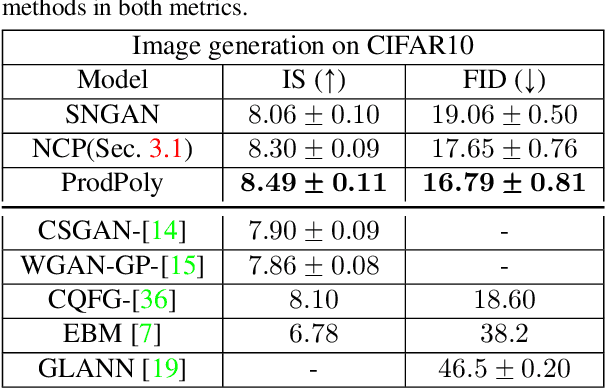
Deep Convolutional Neural Networks (DCNNs) is currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. $\Pi$-Nets can be implemented using special kind of skip connections and their parameters can be represented via high-order tensors. We empirically demonstrate that $\Pi$-Nets have better representation power than standard DCNNs and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in challenging tasks, such as image generation. Lastly, our framework elucidates why recent generative models, such as StyleGAN, improve upon their predecessors, e.g., ProGAN.
Reconstructing the Noise Manifold for Image Denoising
Mar 07, 2020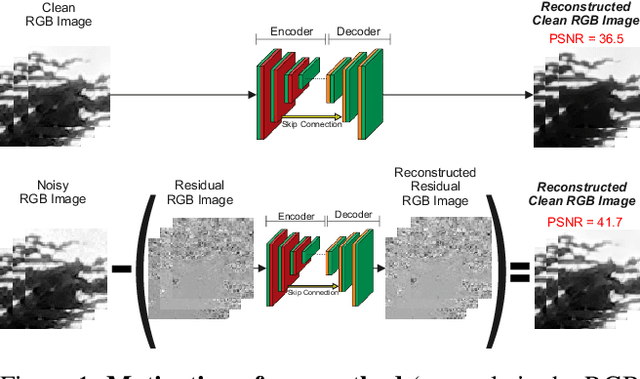
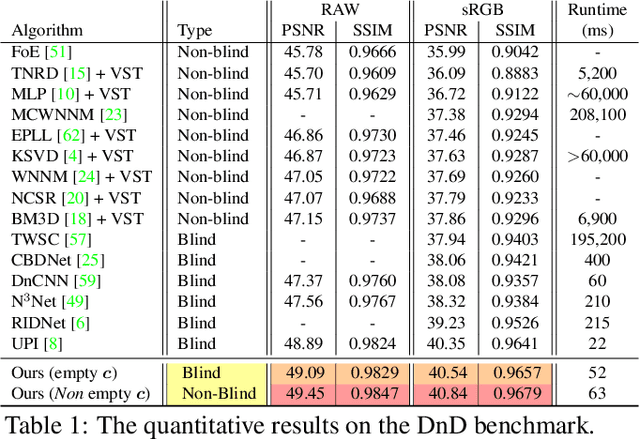
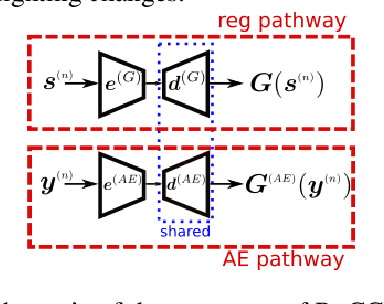
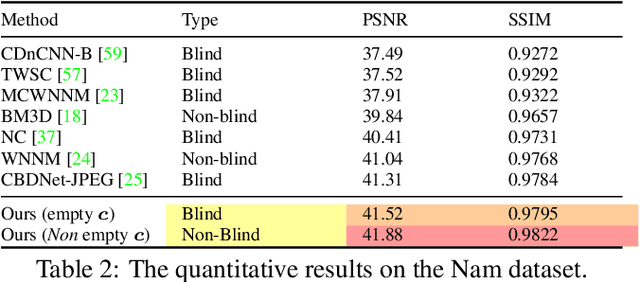
Deep Convolutional Neural Networks (CNNs) have been successfully used in many low-level vision problems like image denoising. Although the conditional image generation techniques have led to large improvements in this task, there has been little effort in providing conditional generative adversarial networks (cGAN)[42] with an explicit way of understanding the image noise for object-independent denoising reliable for real-world applications. The task of leveraging structures in the target space is unstable due to the complexity of patterns in natural scenes, so the presence of unnatural artifacts or over-smoothed image areas cannot be avoided. To fill the gap, in this work we introduce the idea of a cGAN which explicitly leverages structure in the image noise space. By learning directly a low dimensional manifold of the image noise, the generator promotes the removal from the noisy image only that information which spans this manifold. This idea brings many advantages while it can be appended at the end of any denoiser to significantly improve its performance. Based on our experiments, our model substantially outperforms existing state-of-the-art architectures, resulting in denoised images with less oversmoothing and better detail.
Analysing Affective Behavior in the First ABAW 2020 Competition
Jan 30, 2020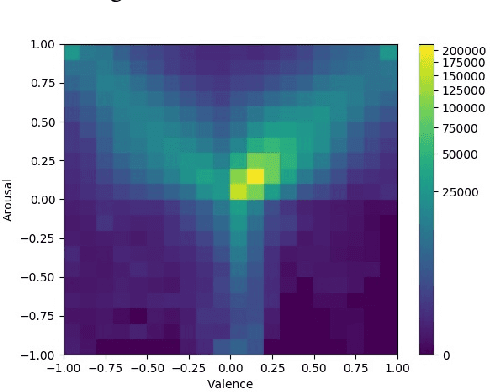
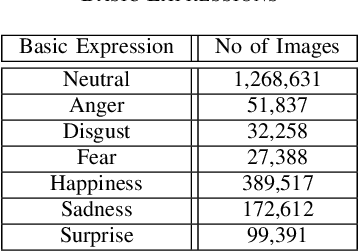
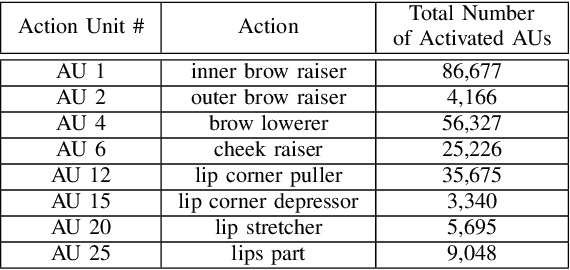
The Affective Behavior Analysis in-the-wild (ABAW) 2020 Competition is the first Competition aiming at automatic analysis of the three main behavior tasks of valence-arousal estimation, basic expression recognition and action unit detection. It is split into three Challenges, each one addressing a respective behavior task. For the Challenges, we provide a common benchmark database, Aff-Wild2, which is a large scale in-the-wild database and the first one annotated for all these three tasks. In this paper, we describe this Competition, to be held in conjunction with the IEEE Conference on Face and Gesture Recognition, May 2020, in Buenos Aires, Argentina. We present the three Challenges, with the utilized Competition corpora. We outline the evaluation metrics and present the baseline methodologies and the obtained results when these are applied to each Challenge. More information regarding the Competition and details for how to access the utilized database, are provided in the Competition site: http://ibug.doc.ic.ac.uk/resources/fg-2020-competition-affective-behavior-analysis.
Using Fully Convolutional Neural Networks to detect manipulated images in videos
Nov 29, 2019
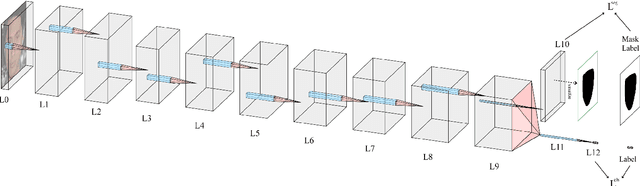

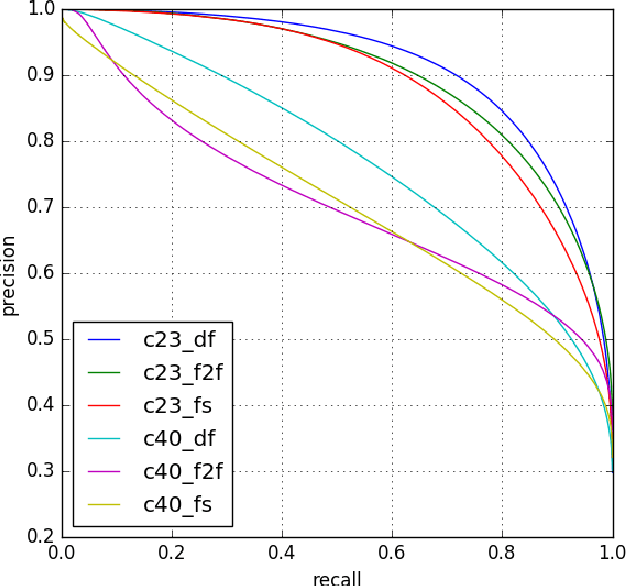
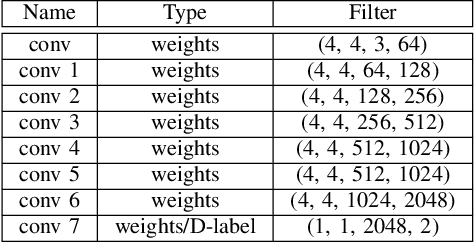
We propose a compact architecture based on fully convolutional neural networks (FCN) to detect manipulated images of human faces. In contrast to existing FCN architectures for classification, here the final layer feature map exhibits large spatial dimensions with non-global receptive field. The final layer features are spatially averaged using global average pooling (GAP) to provide more robust features. We leverage the structure of the FCN to derive a straightforward way for joint classification and forgery localization training and show that the network's classification performance improves significantly by the addition of a pixelwise classification loss. The trained networks achieve state of the art results in binary classification in the {\it FaceForensics++} dataset and competitive performance in other tasks using a significantly reduced number of parameters and small resolution input images. Additionally, we examine how well the proposed architecture can detect fully generated images using faces from the recently proposed PGAN and StyleGAN methods. We show that this task is easier to learn than detecting manipulated images and that for both cases there is only a small drop of performance when the network is trained using more than one manipulation technique in the training data.
Pixel Adaptive Filtering Units
Nov 24, 2019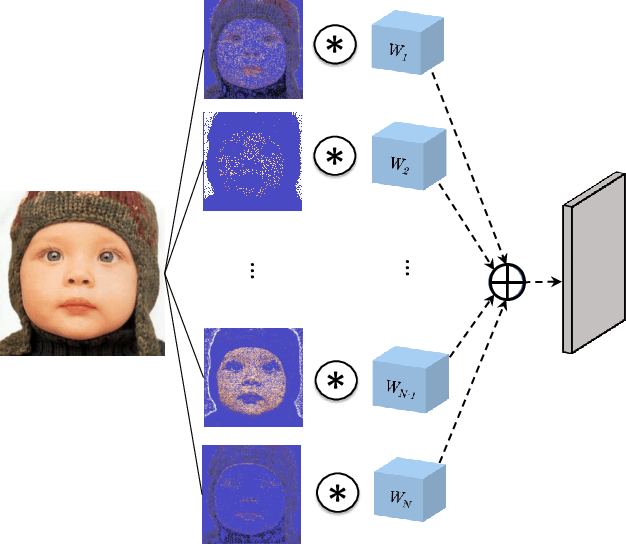
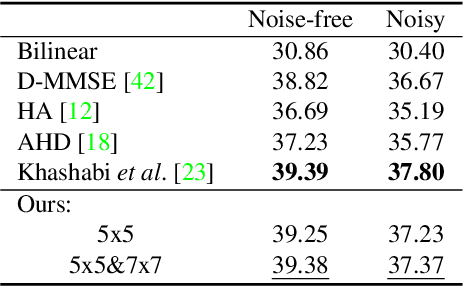
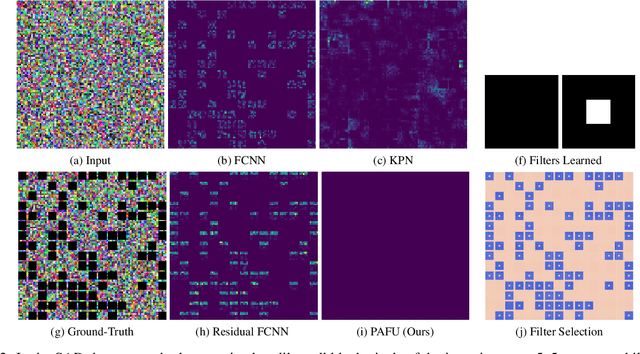
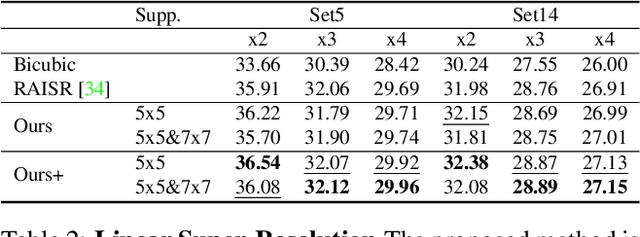
State-of-the-art methods for computer vision rely heavily on the translation equivariance and spatial sharing properties of convolutional layers without explicitly taking into consideration the input content. Modern techniques employ deep sophisticated architectures in order to circumvent this issue. In this work, we propose a Pixel Adaptive Filtering Unit (PAFU) which introduces a differentiable kernel selection mechanism paired with a discrete, learnable and decorrelated group of kernels to allow for content-based spatial adaptation. First, we demonstrate the applicability of the technique in applications where runtime is of importance. Next, we employ PAFU in deep neural networks as a replacement of standard convolutional layers to enhance the original architectures with spatially varying computations to achieve considerable performance improvements. Finally, diverse and extensive experimentation provides strong empirical evidence in favor of the proposed content-adaptive processing scheme across different image processing and high-level computer vision tasks.