 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Methods in Computer Vision and Deep Learning
Jul 07, 2021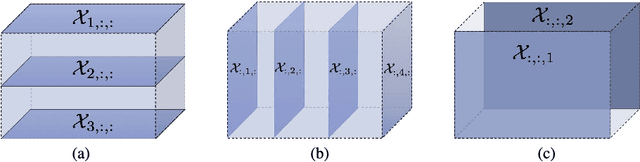
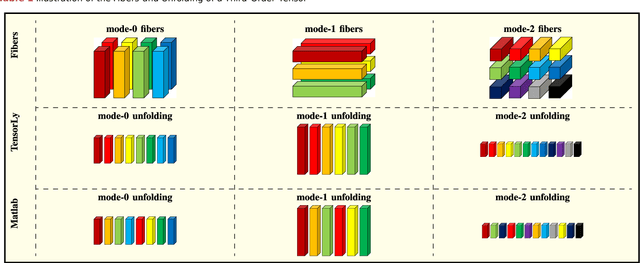
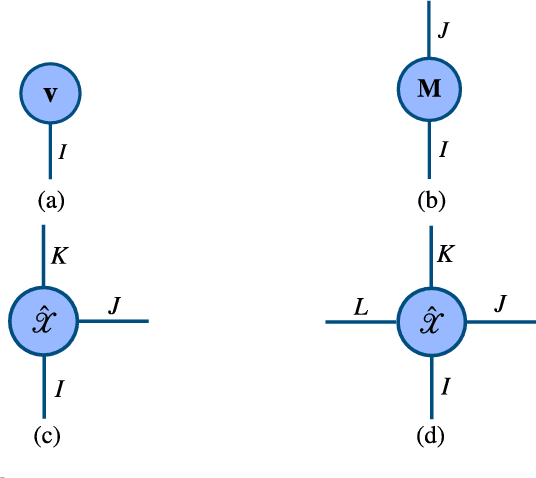
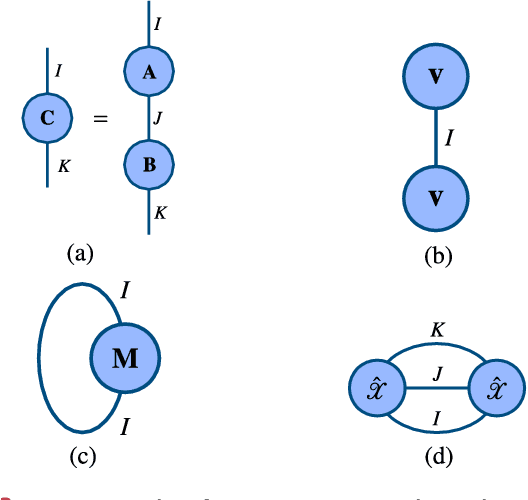
Tensors, or multidimensional arrays, are data structures that can naturally represent visual data of multiple dimensions. Inherently able to efficiently capture structured, latent semantic spaces and high-order interactions, tensors have a long history of applications in a wide span of computer vision problems. With the advent of the deep learning paradigm shift in computer vision, tensors have become even more fundamental. Indeed, essential ingredients in modern deep learning architectures, such as convolutions and attention mechanisms, can readily be considered as tensor mappings. In effect, tensor methods are increasingly finding significant applications in deep learning, including the design of memory and compute efficient network architectures, improving robustness to random noise and adversarial attacks, and aiding the theoretical understanding of deep networks. This article provides an in-depth and practical review of tensors and tensor methods in the context of representation learning and deep learning, with a particular focus on visual data analysis and computer vision applications. Concretely, besides fundamental work in tensor-based visual data analysis methods, we focus on recent developments that have brought on a gradual increase of tensor methods, especially in deep learning architectures, and their implications in computer vision applications. To further enable the newcomer to grasp such concepts quickly, we provide companion Python notebooks, covering key aspects of the paper and implementing them, step-by-step with TensorLy.
Poly-NL: Linear Complexity Non-local Layers with Polynomials
Jul 06, 2021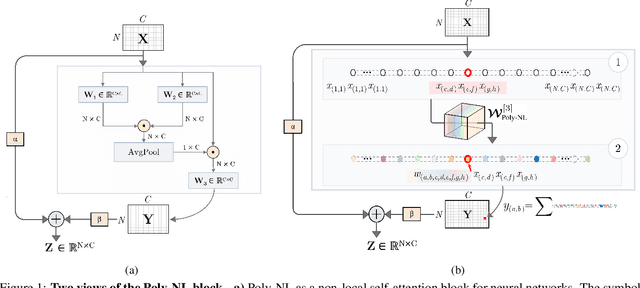
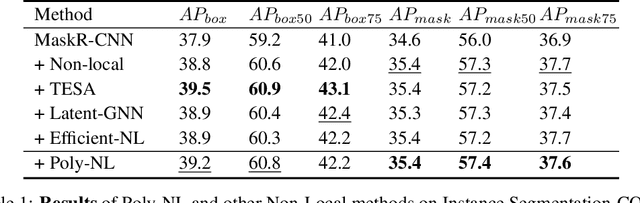
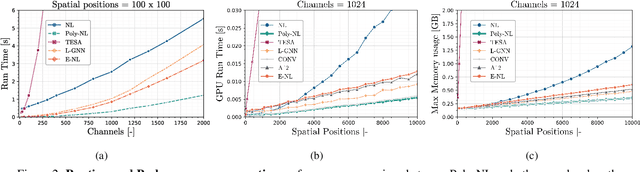
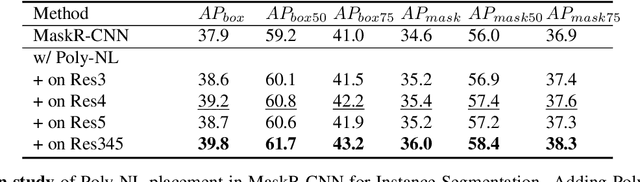
Spatial self-attention layers, in the form of Non-Local blocks, introduce long-range dependencies in Convolutional Neural Networks by computing pairwise similarities among all possible positions. Such pairwise functions underpin the effectiveness of non-local layers, but also determine a complexity that scales quadratically with respect to the input size both in space and time. This is a severely limiting factor that practically hinders the applicability of non-local blocks to even moderately sized inputs. Previous works focused on reducing the complexity by modifying the underlying matrix operations, however in this work we aim to retain full expressiveness of non-local layers while keeping complexity linear. We overcome the efficiency limitation of non-local blocks by framing them as special cases of 3rd order polynomial functions. This fact enables us to formulate novel fast Non-Local blocks, capable of reducing the complexity from quadratic to linear with no loss in performance, by replacing any direct computation of pairwise similarities with element-wise multiplications. The proposed method, which we dub as "Poly-NL", is competitive with state-of-the-art performance across image recognition, instance segmentation, and face detection tasks, while having considerably less computational overhead.
Analysing Affective Behavior in the second ABAW2 Competition
Jul 03, 2021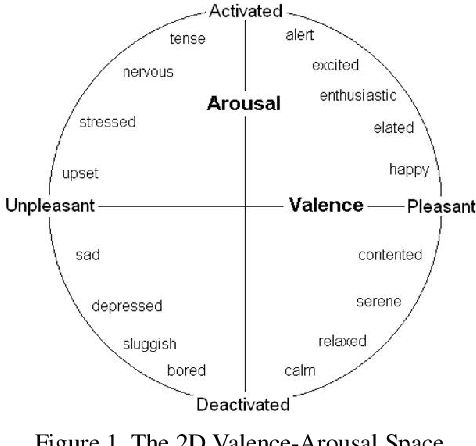
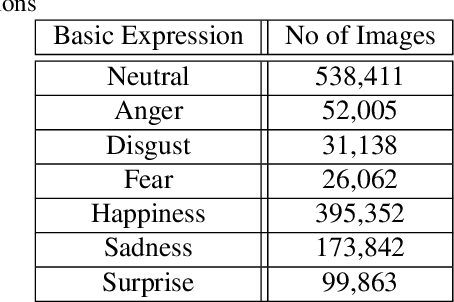
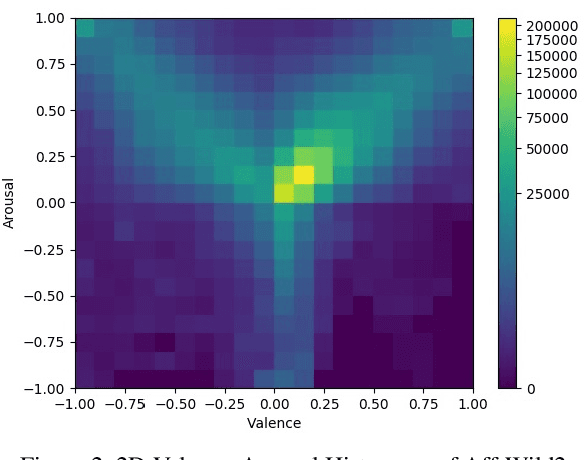
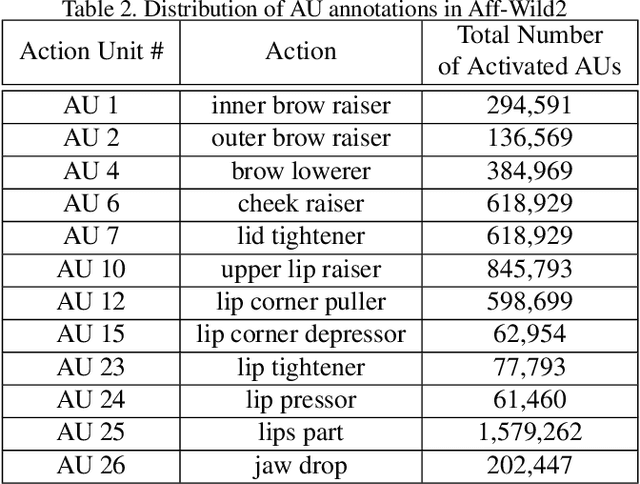
The Affective Behavior Analysis in-the-wild (ABAW2) 2021 Competition is the second -- following the first very successful ABAW Competition held in conjunction with IEEE FG 2020- Competition that aims at automatically analyzing affect. ABAW2 is split into three Challenges, each one addressing one of the three main behavior tasks of valence-arousal estimation, basic expression classification and action unit detection. All three Challenges are based on a common benchmark database, Aff-Wild2, which is a large scale in-the-wild database and the first one to be annotated for all these three tasks. In this paper, we describe this Competition, to be held in conjunction with ICCV 2021. We present the three Challenges, with the utilized Competition corpora. We outline the evaluation metrics and present the baseline system with its results. More information regarding the Competition is provided in the Competition site: https://ibug.doc.ic.ac.uk/resources/iccv-2021-2nd-abaw.
3D human tongue reconstruction from single "in-the-wild" images
Jun 23, 2021

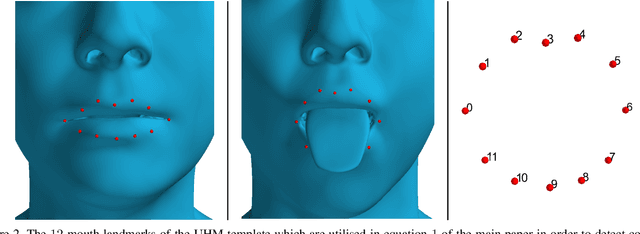

3D face reconstruction from a single image is a task that has garnered increased interest in the Computer Vision community, especially due to its broad use in a number of applications such as realistic 3D avatar creation, pose invariant face recognition and face hallucination. Since the introduction of the 3D Morphable Model in the late 90's, we witnessed an explosion of research aiming at particularly tackling this task. Nevertheless, despite the increasing level of detail in the 3D face reconstructions from single images mainly attributed to deep learning advances, finer and highly deformable components of the face such as the tongue are still absent from all 3D face models in the literature, although being very important for the realness of the 3D avatar representations. In this work we present the first, to the best of our knowledge, end-to-end trainable pipeline that accurately reconstructs the 3D face together with the tongue. Moreover, we make this pipeline robust in "in-the-wild" images by introducing a novel GAN method tailored for 3D tongue surface generation. Finally, we make publicly available to the community the first diverse tongue dataset, consisting of 1,800 raw scans of 700 individuals varying in gender, age, and ethnicity backgrounds. As we demonstrate in an extensive series of quantitative as well as qualitative experiments, our model proves to be robust and realistically captures the 3D tongue structure, even in adverse "in-the-wild" conditions.
Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction
May 16, 2021
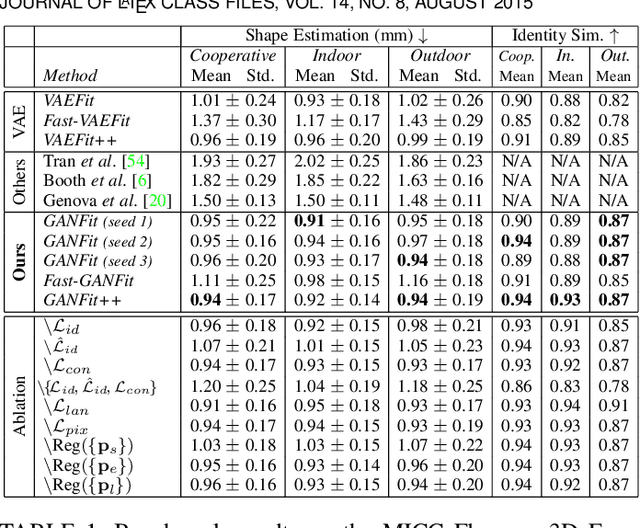
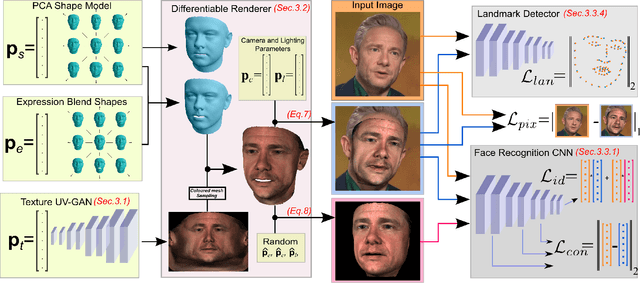
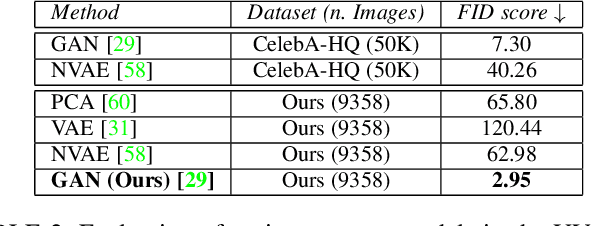
A lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the recent works, the texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction is still not capable of modeling facial texture with high-frequency details. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful facial texture prior \edit{from a large-scale 3D texture dataset}. Then, we revisit the original 3D Morphable Models (3DMMs) fitting making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. In order to be robust towards initialisation and expedite the fitting process, we propose a novel self-supervised regression based approach. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
Sample and Computation Redistribution for Efficient Face Detection
May 10, 2021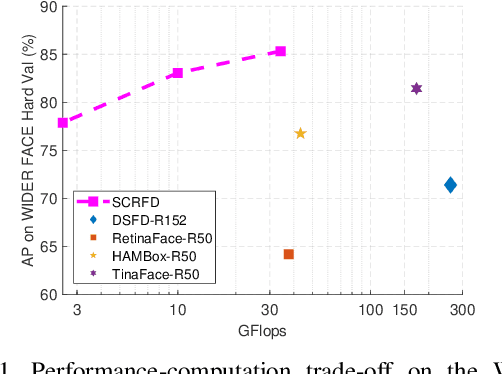
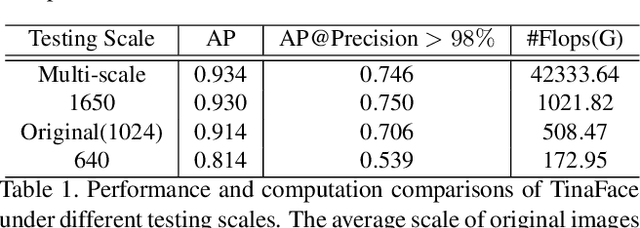

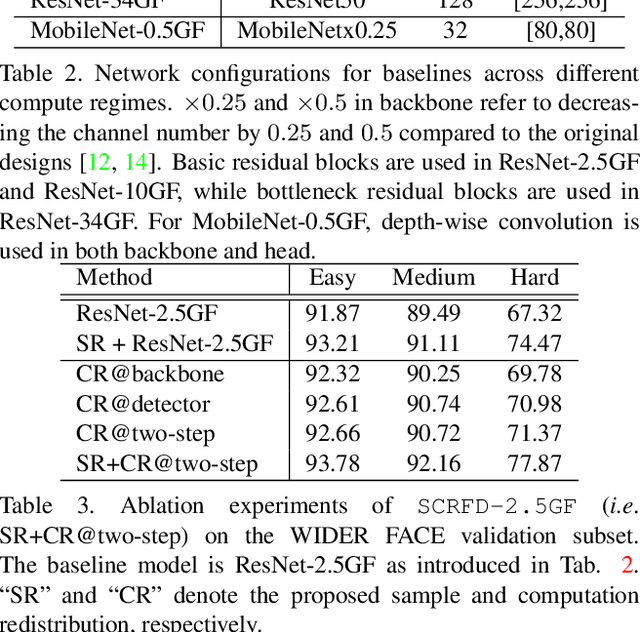
Although tremendous strides have been made in uncontrolled face detection, efficient face detection with a low computation cost as well as high precision remains an open challenge. In this paper, we point out that training data sampling and computation distribution strategies are the keys to efficient and accurate face detection. Motivated by these observations, we introduce two simple but effective methods (1) Sample Redistribution (SR), which augments training samples for the most needed stages, based on the statistics of benchmark datasets; and (2) Computation Redistribution (CR), which reallocates the computation between the backbone, neck and head of the model, based on a meticulously defined search methodology. Extensive experiments conducted on WIDER FACE demonstrate the state-of-the-art efficiency-accuracy trade-off for the proposed \scrfd family across a wide range of compute regimes. In particular, \scrfdf{34} outperforms the best competitor, TinaFace, by $3.86\%$ (AP at hard set) while being more than \emph{3$\times$ faster} on GPUs with VGA-resolution images. We also release our code to facilitate future research.
Distribution Matching for Heterogeneous Multi-Task Learning: a Large-scale Face Study
May 08, 2021
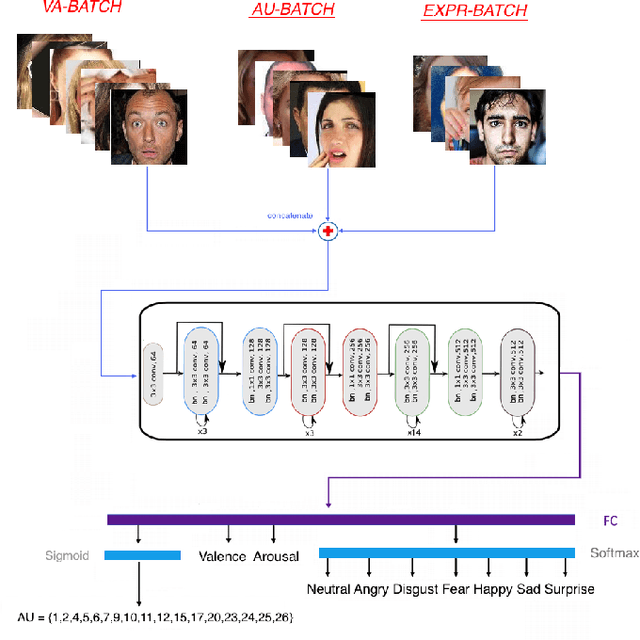

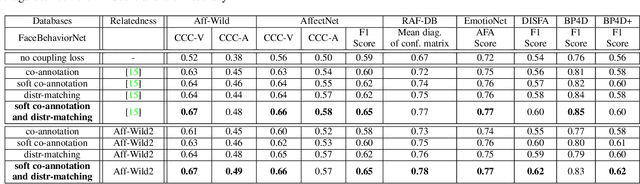
Multi-Task Learning has emerged as a methodology in which multiple tasks are jointly learned by a shared learning algorithm, such as a DNN. MTL is based on the assumption that the tasks under consideration are related; therefore it exploits shared knowledge for improving performance on each individual task. Tasks are generally considered to be homogeneous, i.e., to refer to the same type of problem. Moreover, MTL is usually based on ground truth annotations with full, or partial overlap across tasks. In this work, we deal with heterogeneous MTL, simultaneously addressing detection, classification & regression problems. We explore task-relatedness as a means for co-training, in a weakly-supervised way, tasks that contain little, or even non-overlapping annotations. Task-relatedness is introduced in MTL, either explicitly through prior expert knowledge, or through data-driven studies. We propose a novel distribution matching approach, in which knowledge exchange is enabled between tasks, via matching of their predictions' distributions. Based on this approach, we build FaceBehaviorNet, the first framework for large-scale face analysis, by jointly learning all facial behavior tasks. We develop case studies for: i) continuous affect estimation, action unit detection, basic emotion recognition; ii) attribute detection, face identification. We illustrate that co-training via task relatedness alleviates negative transfer. Since FaceBehaviorNet learns features that encapsulate all aspects of facial behavior, we conduct zero-/few-shot learning to perform tasks beyond the ones that it has been trained for, such as compound emotion recognition. By conducting a very large experimental study, utilizing 10 databases, we illustrate that our approach outperforms, by large margins, the state-of-the-art in all tasks and in all databases, even in these which have not been used in its training.
DeepSatData: Building large scale datasets of satellite images for training machine learning models
May 06, 2021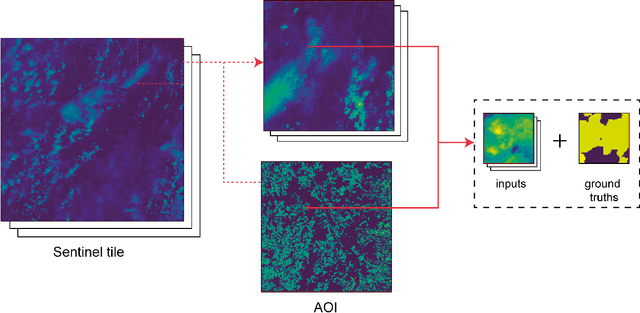
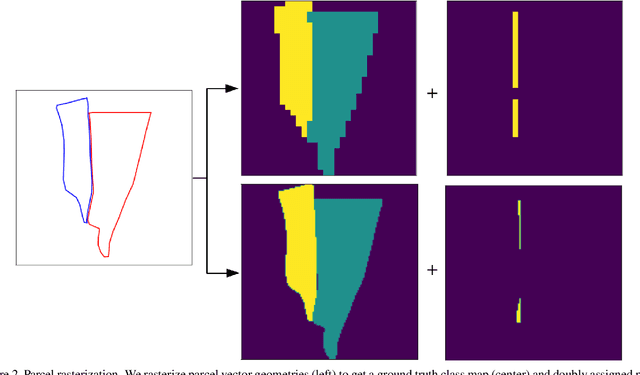
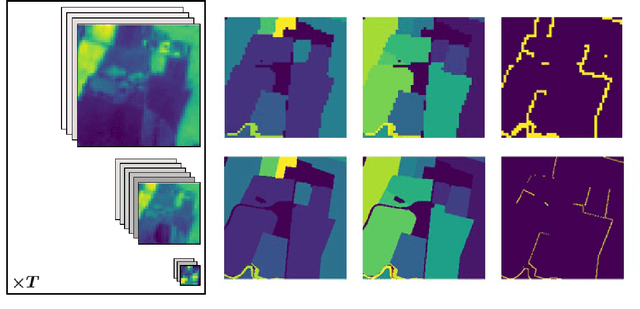
This report presents design considerations for automatically generating satellite imagery datasets for training machine learning models with emphasis placed on dense classification tasks, e.g. semantic segmentation. The implementation presented makes use of freely available Sentinel-2 data which allows generation of large scale datasets required for training deep neural networks. We discuss issues faced from the point of view of deep neural network training and evaluation such as checking the quality of ground truth data and comment on the scalability of the approach. Accompanying code is provided in https://github.com/michaeltrs/DeepSatData.
Context-self contrastive pretraining for crop type semantic segmentation
Apr 09, 2021
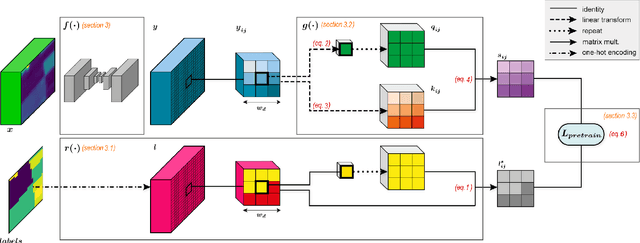
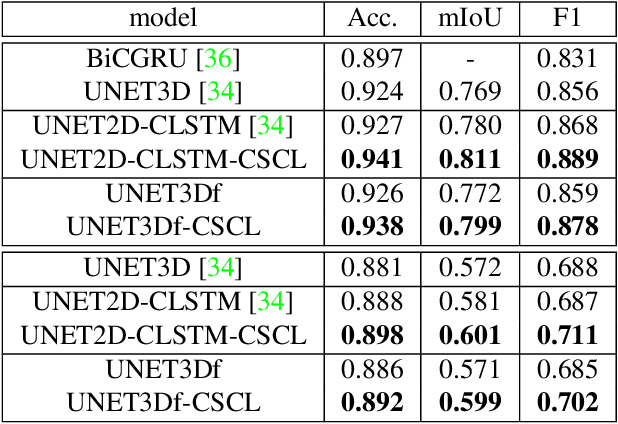
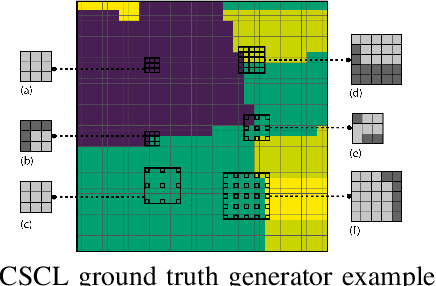
In this paper we propose a fully-supervised pretraining scheme based on contrastive learning particularly tailored to dense classification tasks. The proposed Context-Self Contrastive Loss (CSCL) learns an embedding space that makes semantic boundaries pop-up by use of a similarity metric between every location in an training sample and its local context. For crop type semantic segmentation from satellite images we find performance at parcel boundaries to be a critical bottleneck and explain how CSCL tackles the underlying cause of that problem, improving the state-of-the-art performance in this task. Additionally, using images from the Sentinel-2 (S2) satellite missions we compile the largest, to our knowledge, dataset of satellite image timeseries densely annotated by crop type and parcel identities, which we make publicly available together with the data generation pipeline. Using that data we find CSCL, even with minimal pretraining, to improve all respective baselines and present a process for semantic segmentation at super-resolution for obtaining crop classes at a more granular level. The proposed method is further validated on the task of semantic segmentation on 2D and 3D volumetric images showing consistent performance improvements upon competitive baselines.
Head2HeadFS: Video-based Head Reenactment with Few-shot Learning
Mar 30, 2021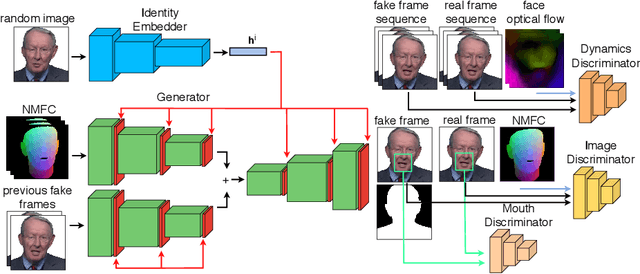
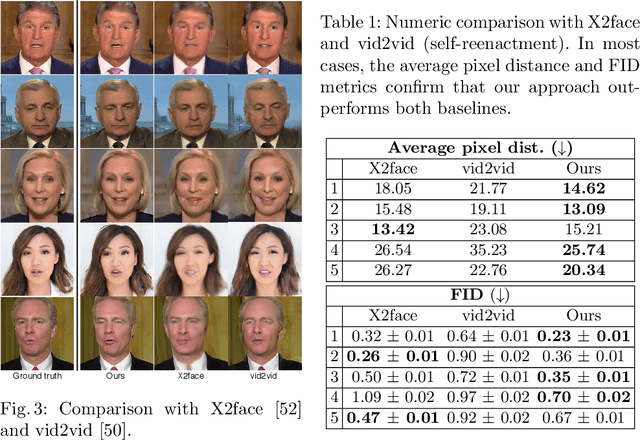


Over the past years, a substantial amount of work has been done on the problem of facial reenactment, with the solutions coming mainly from the graphics community. Head reenactment is an even more challenging task, which aims at transferring not only the facial expression, but also the entire head pose from a source person to a target. Current approaches either train person-specific systems, or use facial landmarks to model human heads, a representation that might transfer unwanted identity attributes from the source to the target. We propose head2headFS, a novel easily adaptable pipeline for head reenactment. We condition synthesis of the target person on dense 3D face shape information from the source, which enables high quality expression and pose transfer. Our video-based rendering network is fine-tuned under a few-shot learning strategy, using only a few samples. This allows for fast adaptation of a generic generator trained on a multiple-person dataset, into a person-specific one.