 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge7th ABAW Competition: Multi-Task Learning and Compound Expression Recognition
Jul 04, 2024



This paper describes the 7th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with ECCV 2024. The 7th ABAW Competition addresses novel challenges in understanding human expressions and behaviors, crucial for the development of human-centered technologies. The Competition comprises of two sub-challenges: i) Multi-Task Learning (the goal is to learn at the same time, in a multi-task learning setting, to estimate two continuous affect dimensions, valence and arousal, to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), and to detect 12 Action Units); and ii) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes). s-Aff-Wild2, which is a static version of the A/V Aff-Wild2 database and contains annotations for valence-arousal, expressions and Action Units, is utilized for the purposes of the Multi-Task Learning Challenge; a part of C-EXPR-DB, which is an A/V in-the-wild database with compound expression annotations, is utilized for the purposes of the Compound Expression Recognition Challenge. In this paper, we introduce the two challenges, detailing their datasets and the protocols followed for each. We also outline the evaluation metrics, and highlight the baseline systems and their results. Additional information about the competition can be found at \url{https://affective-behavior-analysis-in-the-wild.github.io/7th}.
ID-to-3D: Expressive ID-guided 3D Heads via Score Distillation Sampling
May 28, 2024We propose ID-to-3D, a method to generate identity- and text-guided 3D human heads with disentangled expressions, starting from even a single casually captured in-the-wild image of a subject. The foundation of our approach is anchored in compositionality, alongside the use of task-specific 2D diffusion models as priors for optimization. First, we extend a foundational model with a lightweight expression-aware and ID-aware architecture, and create 2D priors for geometry and texture generation, via fine-tuning only 0.2% of its available training parameters. Then, we jointly leverage a neural parametric representation for the expressions of each subject and a multi-stage generation of highly detailed geometry and albedo texture. This combination of strong face identity embeddings and our neural representation enables accurate reconstruction of not only facial features but also accessories and hair and can be meshed to provide render-ready assets for gaming and telepresence. Our results achieve an unprecedented level of identity-consistent and high-quality texture and geometry generation, generalizing to a ``world'' of unseen 3D identities, without relying on large 3D captured datasets of human assets.
Improving face generation quality and prompt following with synthetic captions
May 17, 2024



Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
SAGS: Structure-Aware 3D Gaussian Splatting
Apr 29, 2024



Following the advent of NeRFs, 3D Gaussian Splatting (3D-GS) has paved the way to real-time neural rendering overcoming the computational burden of volumetric methods. Following the pioneering work of 3D-GS, several methods have attempted to achieve compressible and high-fidelity performance alternatives. However, by employing a geometry-agnostic optimization scheme, these methods neglect the inherent 3D structure of the scene, thereby restricting the expressivity and the quality of the representation, resulting in various floating points and artifacts. In this work, we propose a structure-aware Gaussian Splatting method (SAGS) that implicitly encodes the geometry of the scene, which reflects to state-of-the-art rendering performance and reduced storage requirements on benchmark novel-view synthesis datasets. SAGS is founded on a local-global graph representation that facilitates the learning of complex scenes and enforces meaningful point displacements that preserve the scene's geometry. Additionally, we introduce a lightweight version of SAGS, using a simple yet effective mid-point interpolation scheme, which showcases a compact representation of the scene with up to 24$\times$ size reduction without the reliance on any compression strategies. Extensive experiments across multiple benchmark datasets demonstrate the superiority of SAGS compared to state-of-the-art 3D-GS methods under both rendering quality and model size. Besides, we demonstrate that our structure-aware method can effectively mitigate floating artifacts and irregular distortions of previous methods while obtaining precise depth maps. Project page https://eververas.github.io/SAGS/.
ShapeFusion: A 3D diffusion model for localized shape editing
Apr 04, 2024



In the realm of 3D computer vision, parametric models have emerged as a ground-breaking methodology for the creation of realistic and expressive 3D avatars. Traditionally, they rely on Principal Component Analysis (PCA), given its ability to decompose data to an orthonormal space that maximally captures shape variations. However, due to the orthogonality constraints and the global nature of PCA's decomposition, these models struggle to perform localized and disentangled editing of 3D shapes, which severely affects their use in applications requiring fine control such as face sculpting. In this paper, we leverage diffusion models to enable diverse and fully localized edits on 3D meshes, while completely preserving the un-edited regions. We propose an effective diffusion masking training strategy that, by design, facilitates localized manipulation of any shape region, without being limited to predefined regions or to sparse sets of predefined control vertices. Following our framework, a user can explicitly set their manipulation region of choice and define an arbitrary set of vertices as handles to edit a 3D mesh. Compared to the current state-of-the-art our method leads to more interpretable shape manipulations than methods relying on latent code state, greater localization and generation diversity while offering faster inference than optimization based approaches. Project page: https://rolpotamias.github.io/Shapefusion/
Design2Cloth: 3D Cloth Generation from 2D Masks
Apr 03, 2024



In recent years, there has been a significant shift in the field of digital avatar research, towards modeling, animating and reconstructing clothed human representations, as a key step towards creating realistic avatars. However, current 3D cloth generation methods are garment specific or trained completely on synthetic data, hence lacking fine details and realism. In this work, we make a step towards automatic realistic garment design and propose Design2Cloth, a high fidelity 3D generative model trained on a real world dataset from more than 2000 subject scans. To provide vital contribution to the fashion industry, we developed a user-friendly adversarial model capable of generating diverse and detailed clothes simply by drawing a 2D cloth mask. Under a series of both qualitative and quantitative experiments, we showcase that Design2Cloth outperforms current state-of-the-art cloth generative models by a large margin. In addition to the generative properties of our network, we showcase that the proposed method can be used to achieve high quality reconstructions from single in-the-wild images and 3D scans. Dataset, code and pre-trained model will become publicly available.
AnimateMe: 4D Facial Expressions via Diffusion Models
Mar 25, 2024



The field of photorealistic 3D avatar reconstruction and generation has garnered significant attention in recent years; however, animating such avatars remains challenging. Recent advances in diffusion models have notably enhanced the capabilities of generative models in 2D animation. In this work, we directly utilize these models within the 3D domain to achieve controllable and high-fidelity 4D facial animation. By integrating the strengths of diffusion processes and geometric deep learning, we employ Graph Neural Networks (GNNs) as denoising diffusion models in a novel approach, formulating the diffusion process directly on the mesh space and enabling the generation of 3D facial expressions. This facilitates the generation of facial deformations through a mesh-diffusion-based model. Additionally, to ensure temporal coherence in our animations, we propose a consistent noise sampling method. Under a series of both quantitative and qualitative experiments, we showcase that the proposed method outperforms prior work in 4D expression synthesis by generating high-fidelity extreme expressions. Furthermore, we applied our method to textured 4D facial expression generation, implementing a straightforward extension that involves training on a large-scale textured 4D facial expression database.
Arc2Face: A Foundation Model of Human Faces
Mar 18, 2024This paper presents Arc2Face, an identity-conditioned face foundation model, which, given the ArcFace embedding of a person, can generate diverse photo-realistic images with an unparalleled degree of face similarity than existing models. Despite previous attempts to decode face recognition features into detailed images, we find that common high-resolution datasets (e.g. FFHQ) lack sufficient identities to reconstruct any subject. To that end, we meticulously upsample a significant portion of the WebFace42M database, the largest public dataset for face recognition (FR). Arc2Face builds upon a pretrained Stable Diffusion model, yet adapts it to the task of ID-to-face generation, conditioned solely on ID vectors. Deviating from recent works that combine ID with text embeddings for zero-shot personalization of text-to-image models, we emphasize on the compactness of FR features, which can fully capture the essence of the human face, as opposed to hand-crafted prompts. Crucially, text-augmented models struggle to decouple identity and text, usually necessitating some description of the given face to achieve satisfactory similarity. Arc2Face, however, only needs the discriminative features of ArcFace to guide the generation, offering a robust prior for a plethora of tasks where ID consistency is of paramount importance. As an example, we train a FR model on synthetic images from our model and achieve superior performance to existing synthetic datasets.
The 6th Affective Behavior Analysis in-the-wild Competition
Mar 12, 2024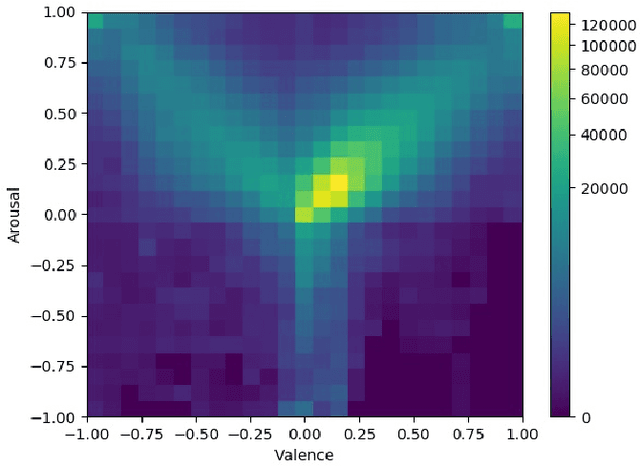
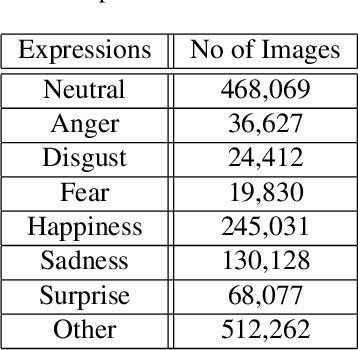
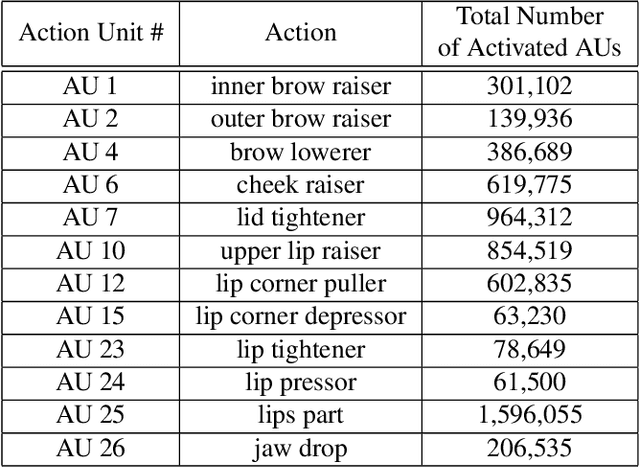
This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: https://affective-behavior-analysis-in-the-wild.github.io/6th.
Spatio-temporal Prompting Network for Robust Video Feature Extraction
Feb 04, 2024Frame quality deterioration is one of the main challenges in the field of video understanding. To compensate for the information loss caused by deteriorated frames, recent approaches exploit transformer-based integration modules to obtain spatio-temporal information. However, these integration modules are heavy and complex. Furthermore, each integration module is specifically tailored for its target task, making it difficult to generalise to multiple tasks. In this paper, we present a neat and unified framework, called Spatio-Temporal Prompting Network (STPN). It can efficiently extract robust and accurate video features by dynamically adjusting the input features in the backbone network. Specifically, STPN predicts several video prompts containing spatio-temporal information of neighbour frames. Then, these video prompts are prepended to the patch embeddings of the current frame as the updated input for video feature extraction. Moreover, STPN is easy to generalise to various video tasks because it does not contain task-specific modules. Without bells and whistles, STPN achieves state-of-the-art performance on three widely-used datasets for different video understanding tasks, i.e., ImageNetVID for video object detection, YouTubeVIS for video instance segmentation, and GOT-10k for visual object tracking. Code is available at https://github.com/guanxiongsun/vfe.pytorch.