 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Ad Hoc Teamwork: Definitions, Methods, and Open Problems
Feb 16, 2022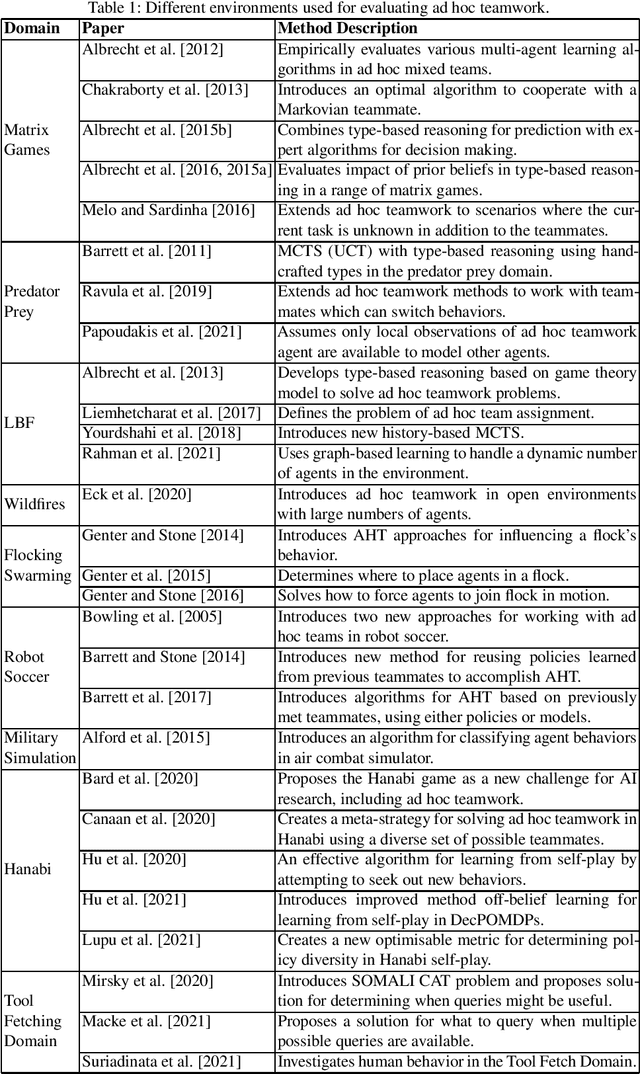
Ad hoc teamwork is the well-established research problem of designing agents that can collaborate with new teammates without prior coordination. This survey makes a two-fold contribution. First, it provides a structured description of the different facets of the ad hoc teamwork problem. Second, it discusses the progress that has been made in the field so far, and identifies the immediate and long-term open problems that need to be addressed in the field of ad hoc teamwork.
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation
Nov 29, 2021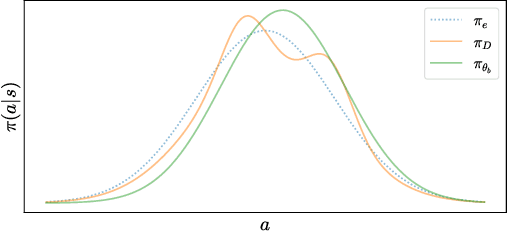

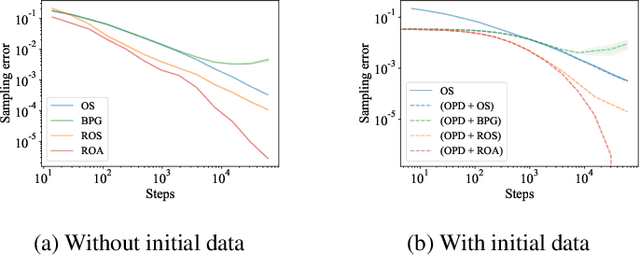
This paper considers how to complement offline reinforcement learning (RL) data with additional data collection for the task of policy evaluation. In policy evaluation, the task is to estimate the expected return of an evaluation policy on an environment of interest. Prior work on offline policy evaluation typically only considers a static dataset. We consider a setting where we can collect a small amount of additional data to combine with a potentially larger offline RL dataset. We show that simply running the evaluation policy -- on-policy data collection -- is sub-optimal for this setting. We then introduce two new data collection strategies for policy evaluation, both of which consider previously collected data when collecting future data so as to reduce distribution shift (or sampling error) in the entire dataset collected. Our empirical results show that compared to on-policy sampling, our strategies produce data with lower sampling error and generally lead to lower mean-squared error in policy evaluation for any total dataset size. We also show that these strategies can start from initial off-policy data, collect additional data, and then use both the initial and new data to produce low mean-squared error policy evaluation without using off-policy corrections.
Learning Temporally-Consistent Representations for Data-Efficient Reinforcement Learning
Oct 11, 2021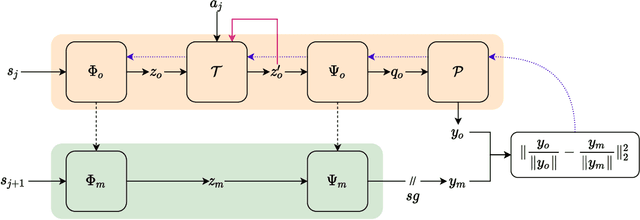
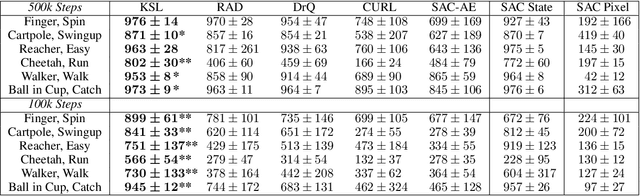
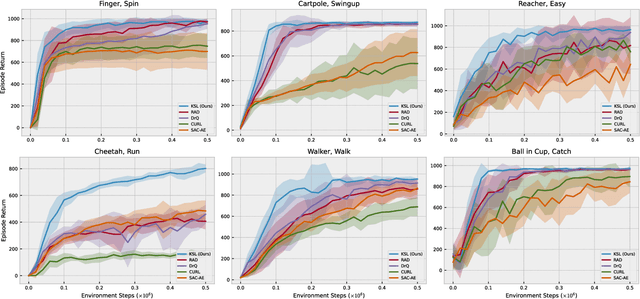
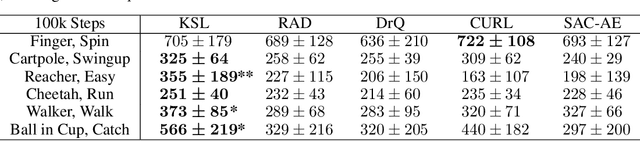
Deep reinforcement learning (RL) agents that exist in high-dimensional state spaces, such as those composed of images, have interconnected learning burdens. Agents must learn an action-selection policy that completes their given task, which requires them to learn a representation of the state space that discerns between useful and useless information. The reward function is the only supervised feedback that RL agents receive, which causes a representation learning bottleneck that can manifest in poor sample efficiency. We present $k$-Step Latent (KSL), a new representation learning method that enforces temporal consistency of representations via a self-supervised auxiliary task wherein agents learn to recurrently predict action-conditioned representations of the state space. The state encoder learned by KSL produces low-dimensional representations that make optimization of the RL task more sample efficient. Altogether, KSL produces state-of-the-art results in both data efficiency and asymptotic performance in the popular PlaNet benchmark suite. Our analyses show that KSL produces encoders that generalize better to new tasks unseen during training, and its representations are more strongly tied to reward, are more invariant to perturbations in the state space, and move more smoothly through the temporal axis of the RL problem than other methods such as DrQ, RAD, CURL, and SAC-AE.
Interpretable Goal Recognition in the Presence of Occluded Factors for Autonomous Vehicles
Aug 05, 2021
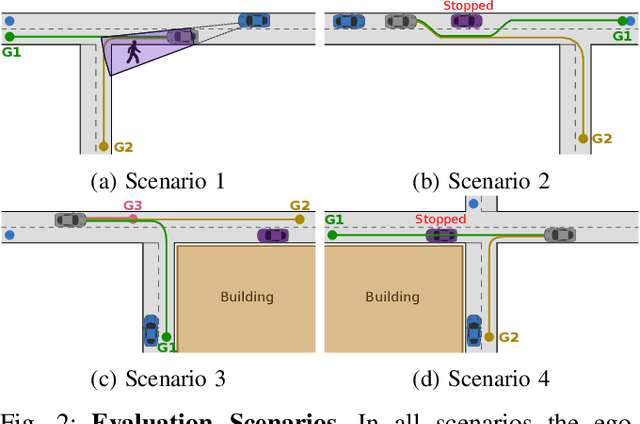
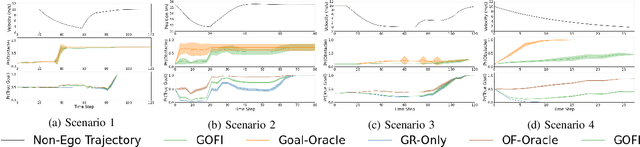
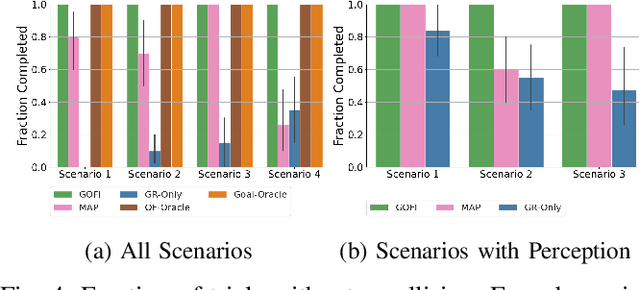
Recognising the goals or intentions of observed vehicles is a key step towards predicting the long-term future behaviour of other agents in an autonomous driving scenario. When there are unseen obstacles or occluded vehicles in a scenario, goal recognition may be confounded by the effects of these unseen entities on the behaviour of observed vehicles. Existing prediction algorithms that assume rational behaviour with respect to inferred goals may fail to make accurate long-horizon predictions because they ignore the possibility that the behaviour is influenced by such unseen entities. We introduce the Goal and Occluded Factor Inference (GOFI) algorithm which bases inference on inverse-planning to jointly infer a probabilistic belief over goals and potential occluded factors. We then show how these beliefs can be integrated into Monte Carlo Tree Search (MCTS). We demonstrate that jointly inferring goals and occluded factors leads to more accurate beliefs with respect to the true world state and allows an agent to safely navigate several scenarios where other baselines take unsafe actions leading to collisions.
Decoupling Exploration and Exploitation in Reinforcement Learning
Jul 22, 2021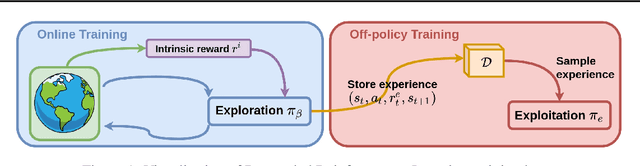
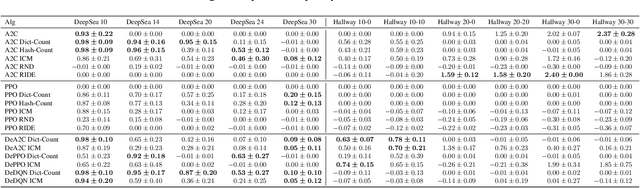

Intrinsic rewards are commonly applied to improve exploration in reinforcement learning. However, these approaches suffer from instability caused by non-stationary reward shaping and strong dependency on hyperparameters. In this work, we propose Decoupled RL (DeRL) which trains separate policies for exploration and exploitation. DeRL can be applied with on-policy and off-policy RL algorithms. We evaluate DeRL algorithms in two sparse-reward environments with multiple types of intrinsic rewards. We show that DeRL is more robust to scaling and speed of decay of intrinsic rewards and converges to the same evaluation returns than intrinsically motivated baselines in fewer interactions.
Expressivity of Emergent Language is a Trade-off between Contextual Complexity and Unpredictability
Jun 07, 2021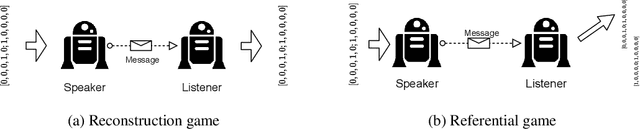

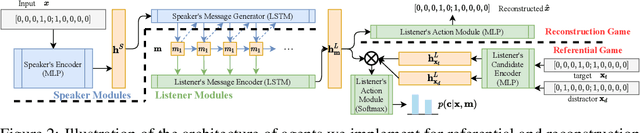
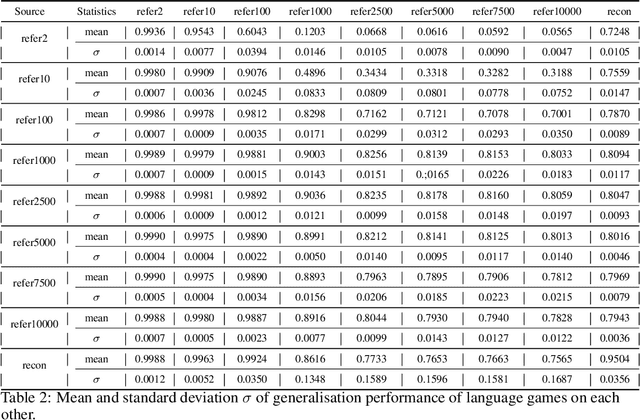
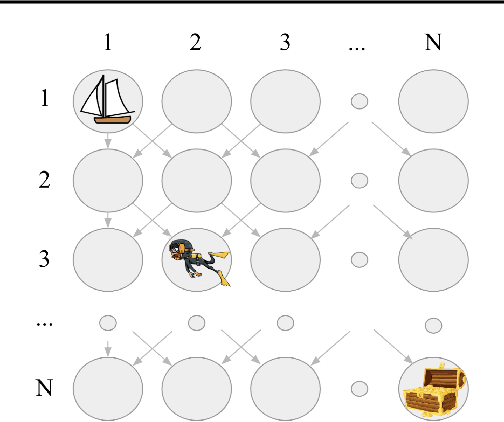
Researchers are now using deep learning models to explore the emergence of language in various language games, where simulated agents interact and develop an emergent language to solve a task. Although it is quite intuitive that different types of language games posing different communicative challenges might require emergent languages which encode different levels of information, there is no existing work exploring the expressivity of the emergent languages. In this work, we propose a definition of partial order between expressivity based on the generalisation performance across different language games. We also validate the hypothesis that expressivity of emergent languages is a trade-off between the complexity and unpredictability of the context those languages are used in. Our second novel contribution is introducing contrastive loss into the implementation of referential games. We show that using our contrastive loss alleviates the collapse of message types seen using standard referential loss functions.
GRIT: Verifiable Goal Recognition for Autonomous Driving using Decision Trees
Mar 10, 2021
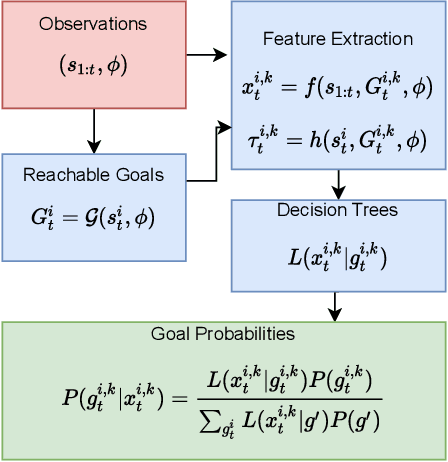
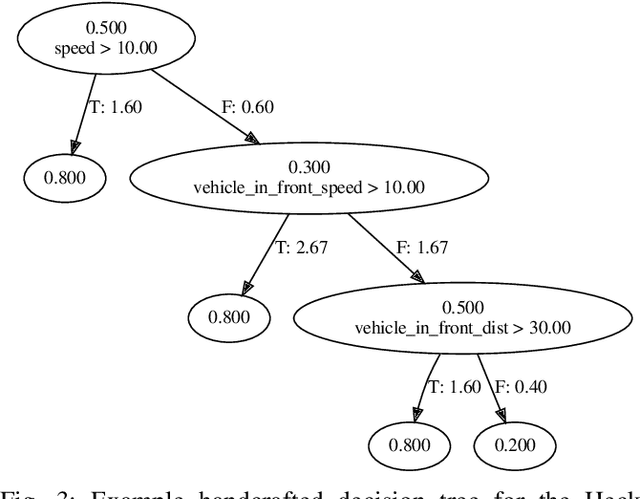
It is useful for autonomous vehicles to have the ability to infer the goals of other vehicles (goal recognition), in order to safely interact with other vehicles and predict their future trajectories. Goal recognition methods must be fast to run in real time and make accurate inferences. As autonomous driving is safety-critical, it is important to have methods which are human interpretable and for which safety can be formally verified. Existing goal recognition methods for autonomous vehicles fail to satisfy all four objectives of being fast, accurate, interpretable and verifiable. We propose Goal Recognition with Interpretable Trees (GRIT), a goal recognition system for autonomous vehicles which achieves these objectives. GRIT makes use of decision trees trained on vehicle trajectory data. Evaluation on two vehicle trajectory datasets demonstrates the inference speed and accuracy of GRIT compared to an ablation and two deep learning baselines. We show that the learned trees are human interpretable and demonstrate how properties of GRIT can be formally verified using an SMT solver.
Scaling Multi-Agent Reinforcement Learning with Selective Parameter Sharing
Feb 15, 2021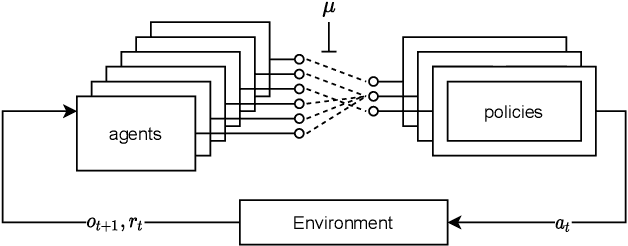
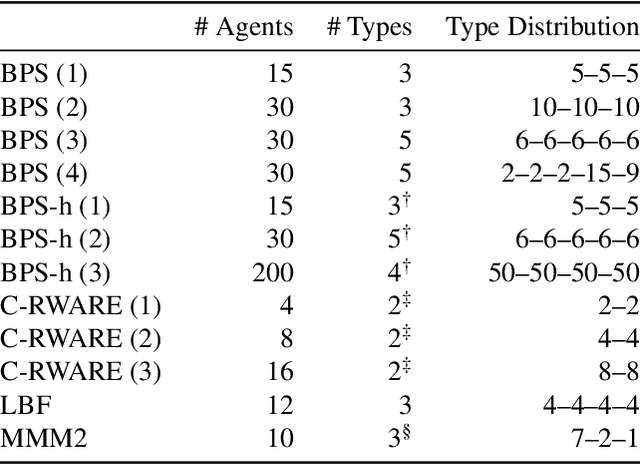
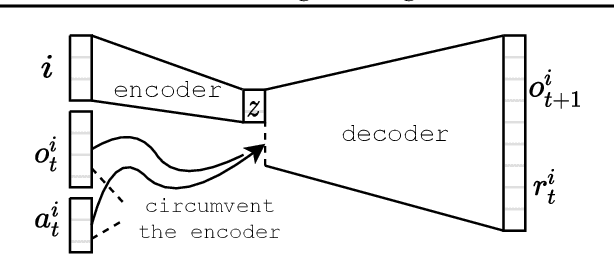
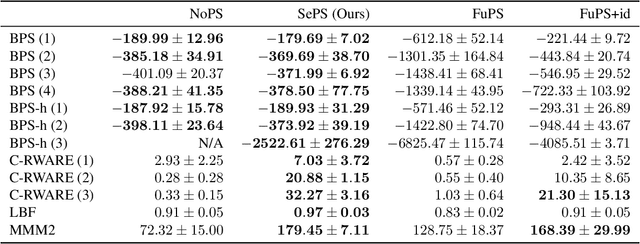
Sharing parameters in multi-agent deep reinforcement learning has played an essential role in allowing algorithms to scale to a large number of agents. Parameter sharing between agents significantly decreases the number of trainable parameters, shortening training times to tractable levels, and has been linked to more efficient learning. However, having all agents share the same parameters can also have a detrimental effect on learning. We demonstrate the impact of parameter sharing methods on training speed and converged returns, establishing that when applied indiscriminately, their effectiveness is highly dependent on the environment. Therefore, we propose a novel method to automatically identify agents which may benefit from sharing parameters by partitioning them based on their abilities and goals. Our approach combines the increased sample efficiency of parameter sharing with the representational capacity of multiple independent networks to reduce training time and increase final returns.
Quantum-Secure Authentication via Abstract Multi-Agent Interaction
Jul 18, 2020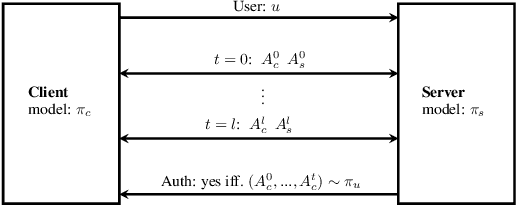
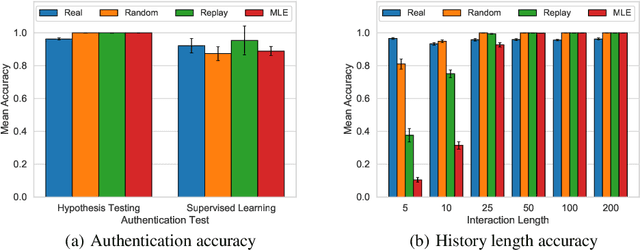
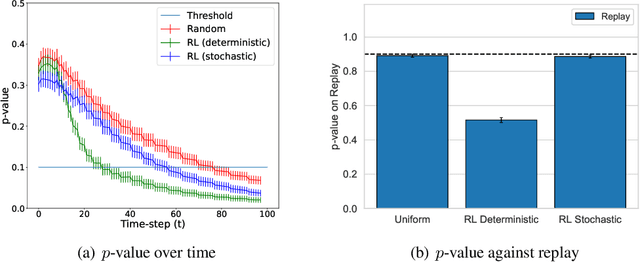
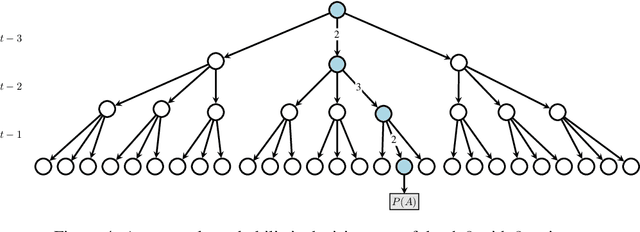
Current methods for authentication based on public-key cryptography are vulnerable to quantum computing. We propose a novel approach to authentication in which communicating parties are viewed as autonomous agents which interact repeatedly using their private decision models. The security of this approach rests upon the difficulty of learning the model parameters of interacting agents, a problem which we conjecture is also hard for quantum computing. We develop methods which enable a server agent to classify a client agent as either legitimate or adversarial based on their past interactions. Moreover, we use reinforcement learning techniques to train server policies which effectively probe the client's decisions to achieve more sample-efficient authentication, while making modelling attacks as difficult as possible via entropy-maximization principles. We empirically validate our methods for authenticating legitimate users while detecting different types of adversarial attacks.
Open Ad Hoc Teamwork using Graph-based Policy Learning
Jun 18, 2020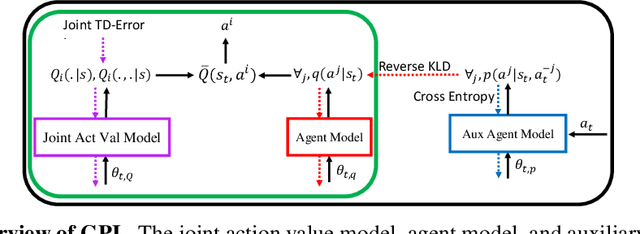

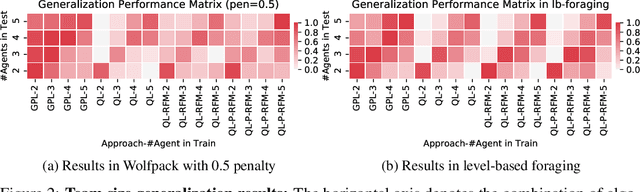

Ad hoc teamwork is the challenging problem of designing an autonomous agent which can adapt quickly to collaborate with previously unknown teammates. Prior work in this area has focused on closed teams in which the number of agents is fixed. In this work, we consider open teams by allowing agents of varying types to enter and leave the team without prior notification. Our proposed solution builds on graph neural networks to learn scalable agent models and value decompositions under varying team sizes, which can be jointly trained with a reinforcement learning agent using discounted returns objectives. We demonstrate empirically that our approach results in agent policies which can robustly adapt to dynamic team composition, and is able to effectively generalize to larger teams than were seen during training.