 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Determinantal Point Processes
Aug 09, 2020Determinantal point processes (DPPs) are popular probabilistic models of diversity. In this paper, we investigate DPPs from a new perspective: property testing of distributions. Given sample access to an unknown distribution $q$ over the subsets of a ground set, we aim to distinguish whether $q$ is a DPP distribution, or $\epsilon$-far from all DPP distributions in $\ell_1$-distance. In this work, we propose the first algorithm for testing DPPs. Furthermore, we establish a matching lower bound on the sample complexity of DPP testing. This lower bound also extends to showing a new hardness result for the problem of testing the more general class of log-submodular distributions.
Estimating Generalization under Distribution Shifts via Domain-Invariant Representations
Jul 06, 2020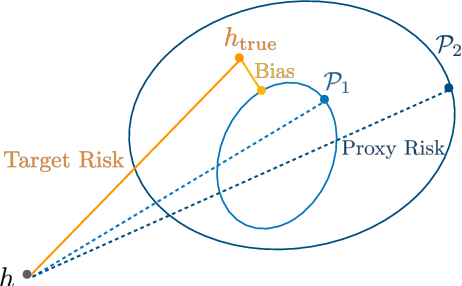
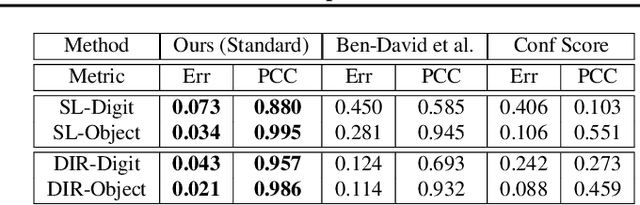
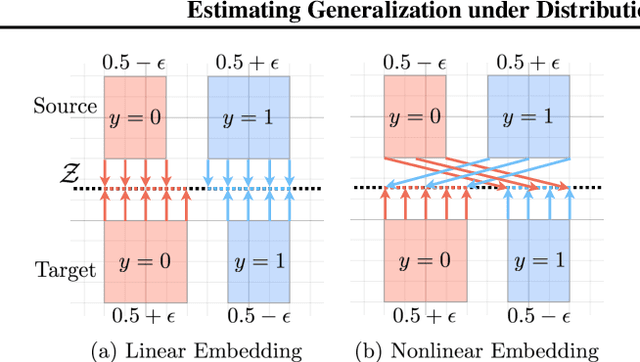
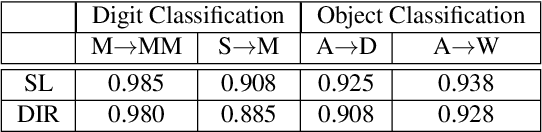
When machine learning models are deployed on a test distribution different from the training distribution, they can perform poorly, but overestimate their performance. In this work, we aim to better estimate a model's performance under distribution shift, without supervision. To do so, we use a set of domain-invariant predictors as a proxy for the unknown, true target labels. Since the error of the resulting risk estimate depends on the target risk of the proxy model, we study generalization of domain-invariant representations and show that the complexity of the latent representation has a significant influence on the target risk. Empirically, our approach (1) enables self-tuning of domain adaptation models, and (2) accurately estimates the target error of given models under distribution shift. Other applications include model selection, deciding early stopping and error detection.
* arXiv admin note: text overlap with arXiv:1910.05804
Debiased Contrastive Learning
Jul 05, 2020
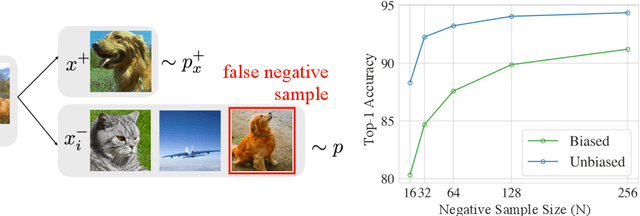
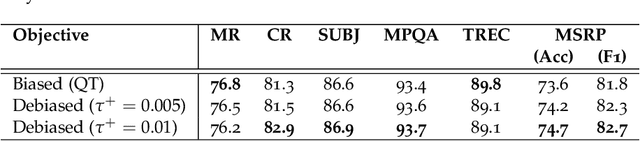

A prominent technique for self-supervised representation learning has been to contrast semantically similar and dissimilar pairs of samples. Without access to labels, dissimilar (negative) points are typically taken to be randomly sampled datapoints, implicitly accepting that these points may, in reality, actually have the same label. Perhaps unsurprisingly, we observe that sampling negative examples from truly different labels improves performance, in a synthetic setting where labels are available. Motivated by this observation, we develop a debiased contrastive objective that corrects for the sampling of same-label datapoints, even without knowledge of the true labels. Empirically, the proposed objective consistently outperforms the state-of-the-art for representation learning in vision, language, and reinforcement learning benchmarks. Theoretically, we establish generalization bounds for the downstream classification task.
IDEAL: Inexact DEcentralized Accelerated Augmented Lagrangian Method
Jun 11, 2020
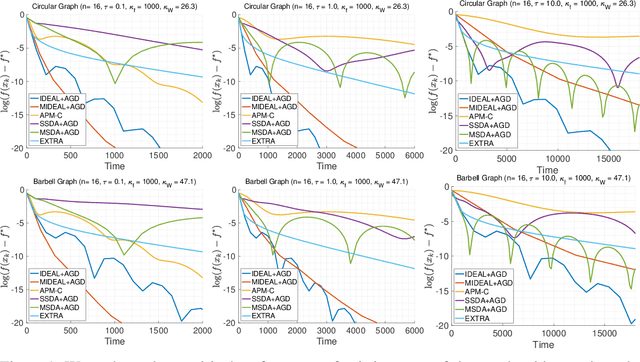

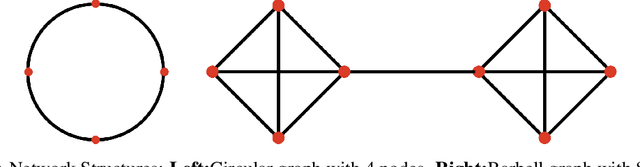
We introduce a framework for designing primal methods under the decentralized optimization setting where local functions are smooth and strongly convex. Our approach consists of approximately solving a sequence of sub-problems induced by the accelerated augmented Lagrangian method, thereby providing a systematic way for deriving several well-known decentralized algorithms including EXTRA arXiv:1404.6264 and SSDA arXiv:1702.08704. When coupled with accelerated gradient descent, our framework yields a novel primal algorithm whose convergence rate is optimal and matched by recently derived lower bounds. We provide experimental results that demonstrate the effectiveness of the proposed algorithm on highly ill-conditioned problems.
Distributionally Robust Bayesian Optimization
Mar 22, 2020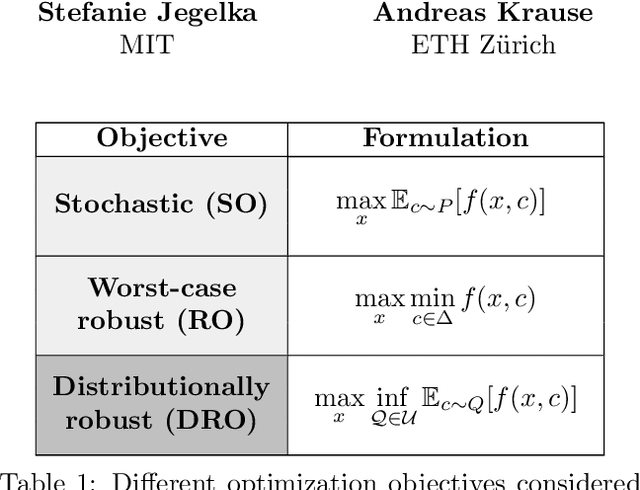
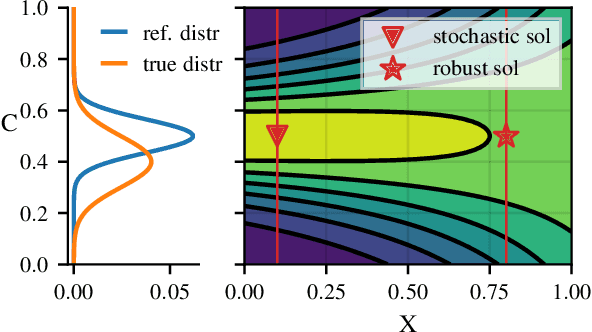
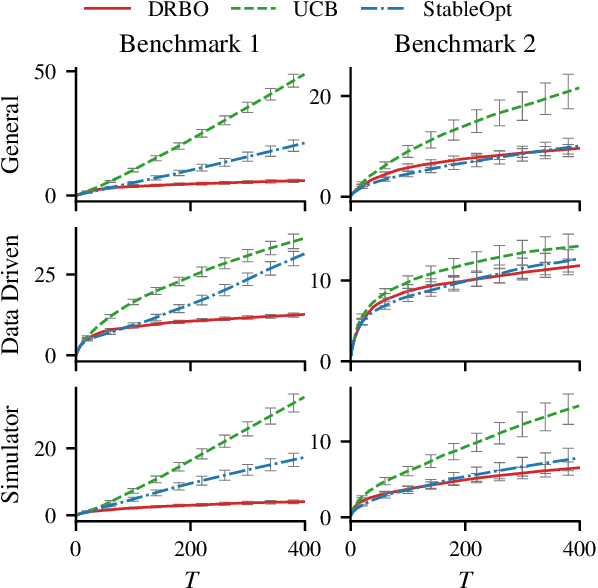
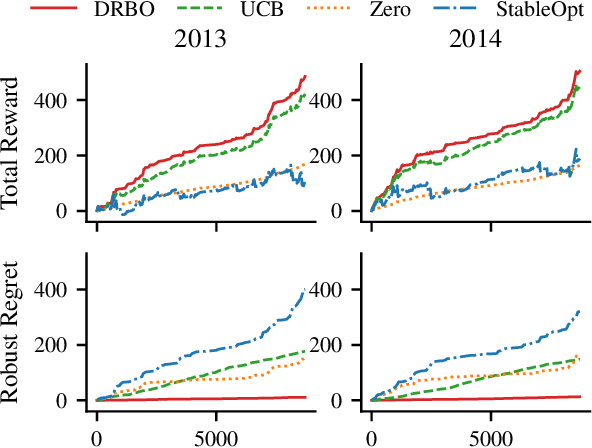
Robustness to distributional shift is one of the key challenges of contemporary machine learning. Attaining such robustness is the goal of distributionally robust optimization, which seeks a solution to an optimization problem that is worst-case robust under a specified distributional shift of an uncontrolled covariate. In this paper, we study such a problem when the distributional shift is measured via the maximum mean discrepancy (MMD). For the setting of zeroth-order, noisy optimization, we present a novel distributionally robust Bayesian optimization algorithm (DRBO). Our algorithm provably obtains sub-linear robust regret in various settings that differ in how the uncertain covariate is observed. We demonstrate the robust performance of our method on both synthetic and real-world benchmarks.
Strength from Weakness: Fast Learning Using Weak Supervision
Feb 19, 2020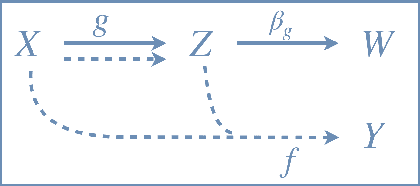
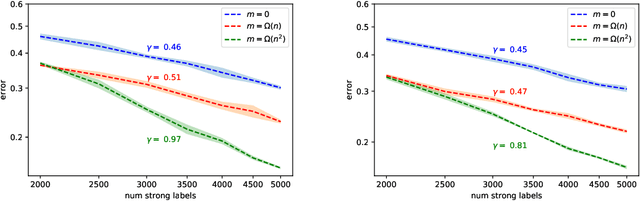
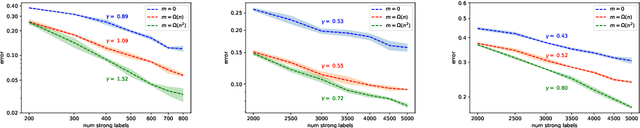
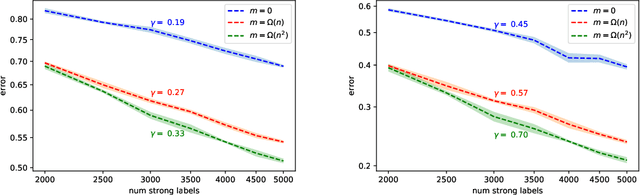
We study generalization properties of weakly supervised learning. That is, learning where only a few "strong" labels (the actual target of our prediction) are present but many more "weak" labels are available. In particular, we show that having access to weak labels can significantly accelerate the learning rate for the strong task to the fast rate of $\mathcal{O}(\nicefrac1n)$, where $n$ denotes the number of strongly labeled data points. This acceleration can happen even if by itself the strongly labeled data admits only the slower $\mathcal{O}(\nicefrac{1}{\sqrt{n}})$ rate. The actual acceleration depends continuously on the number of weak labels available, and on the relation between the two tasks. Our theoretical results are reflected empirically across a range of tasks and illustrate how weak labels speed up learning on the strong task.
On Complexity of Finding Stationary Points of Nonsmooth Nonconvex Functions
Feb 16, 2020
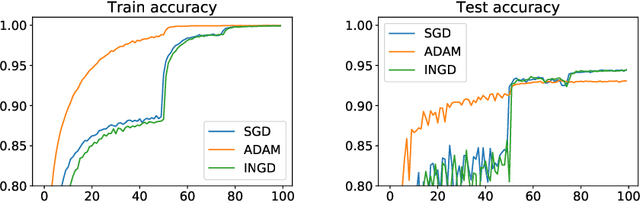
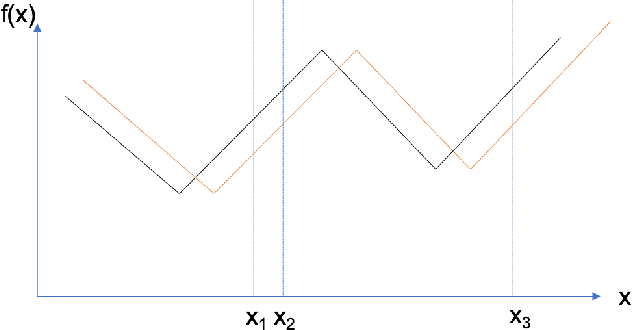
We provide the first \emph{non-asymptotic} analysis for finding stationary points of nonsmooth, nonconvex functions. In particular, we study the class of Hadamard semi-differentiable functions, perhaps the largest class of nonsmooth functions for which the chain rule of calculus holds. This class contains important examples such as ReLU neural networks and others with non-differentiable activation functions. First, we show that finding an $\epsilon$-stationary point with first-order methods is impossible in finite time. Therefore, we introduce the notion of \emph{$(\delta, \epsilon)$-stationarity}, a generalization that allows for a point to be within distance $\delta$ of an $\epsilon$-stationary point and reduces to $\epsilon$-stationarity for smooth functions. We propose a series of randomized first-order methods and analyze their complexity of finding a $(\delta, \epsilon)$-stationary point. Furthermore, we provide a lower bound and show that our stochastic algorithm has min-max optimal dependence on $\delta$. Empirically, our methods perform well for training ReLU neural networks.
Generalization and Representational Limits of Graph Neural Networks
Feb 14, 2020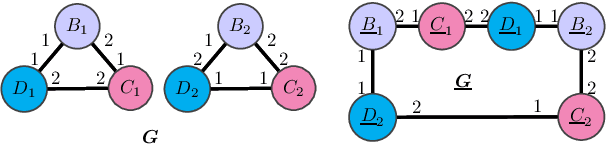
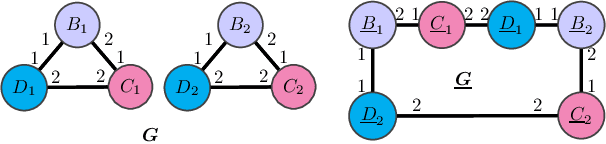

We address two fundamental questions about graph neural networks (GNNs). First, we prove that several important graph properties cannot be computed by GNNs that rely entirely on local information. Such GNNs include the standard message passing models, and more powerful spatial variants that exploit local graph structure (e.g., via relative orientation of messages, or local port ordering) to distinguish neighbors of each node. Our treatment includes a novel graph-theoretic formalism. Second, we provide the first data dependent generalization bounds for message passing GNNs. This analysis explicitly accounts for the local permutation invariance of GNNs. Our bounds are much tighter than existing VC-dimension based guarantees for GNNs, and are comparable to Rademacher bounds for recurrent neural networks.
On the Complexity of Minimizing Convex Finite Sums Without Using the Indices of the Individual Functions
Feb 09, 2020Recent advances in randomized incremental methods for minimizing $L$-smooth $\mu$-strongly convex finite sums have culminated in tight complexity of $\tilde{O}((n+\sqrt{n L/\mu})\log(1/\epsilon))$ and $O(n+\sqrt{nL/\epsilon})$, where $\mu>0$ and $\mu=0$, respectively, and $n$ denotes the number of individual functions. Unlike incremental methods, stochastic methods for finite sums do not rely on an explicit knowledge of which individual function is being addressed at each iteration, and as such, must perform at least $\Omega(n^2)$ iterations to obtain $O(1/n^2)$-optimal solutions. In this work, we exploit the finite noise structure of finite sums to derive a matching $O(n^2)$-upper bound under the global oracle model, showing that this lower bound is indeed tight. Following a similar approach, we propose a novel adaptation of SVRG which is both \emph{compatible with stochastic oracles}, and achieves complexity bounds of $\tilde{O}((n^2+n\sqrt{L/\mu})\log(1/\epsilon))$ and $O(n\sqrt{L/\epsilon})$, for $\mu>0$ and $\mu=0$, respectively. Our bounds hold w.h.p. and match in part existing lower bounds of $\tilde{\Omega}(n^2+\sqrt{nL/\mu}\log(1/\epsilon))$ and $\tilde{\Omega}(n^2+\sqrt{nL/\epsilon})$, for $\mu>0$ and $\mu=0$, respectively.
Adaptive Sampling for Stochastic Risk-Averse Learning
Oct 28, 2019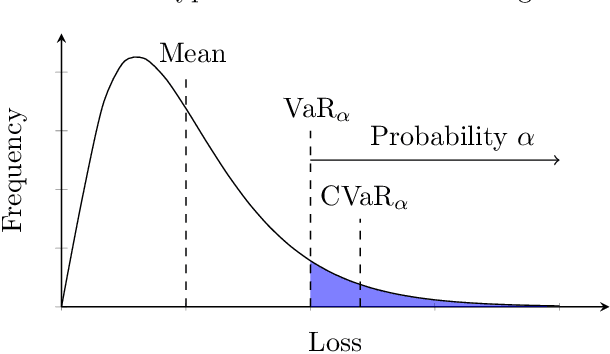
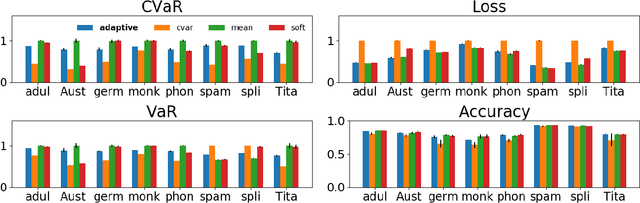

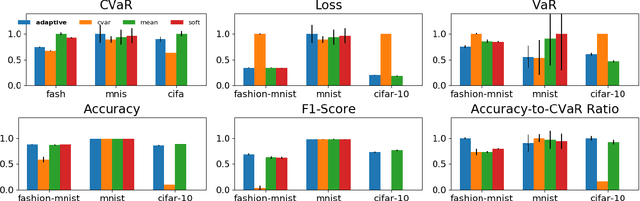
We consider the problem of training machine learning models in a risk-averse manner. In particular, we propose an adaptive sampling algorithm for stochastically optimizing the Conditional Value-at-Risk (CVaR) of a loss distribution. We use a distributionally robust formulation of the CVaR to phrase the problem as a zero-sum game between two players. Our approach solves the game using an efficient no-regret algorithm for each player. Critically, we can apply these algorithms to large-scale settings because the implementation relies on sampling from Determinantal Point Processes. Finally, we empirically demonstrate its effectiveness on large-scale convex and non-convex learning tasks.