 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
Oct 29, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities in answering questions, but they lack domain-specific knowledge and are prone to hallucinations. Retrieval Augmented Generation (RAG) is one approach to address these challenges, while multimodal models are emerging as promising AI assistants for processing both text and images. In this paper we describe a series of experiments aimed at determining how to best integrate multimodal models into RAG systems for the industrial domain. The purpose of the experiments is to determine whether including images alongside text from documents within the industrial domain increases RAG performance and to find the optimal configuration for such a multimodal RAG system. Our experiments include two approaches for image processing and retrieval, as well as two LLMs (GPT4-Vision and LLaVA) for answer synthesis. These image processing strategies involve the use of multimodal embeddings and the generation of textual summaries from images. We evaluate our experiments with an LLM-as-a-Judge approach. Our results reveal that multimodal RAG can outperform single-modality RAG settings, although image retrieval poses a greater challenge than text retrieval. Additionally, leveraging textual summaries from images presents a more promising approach compared to the use of multimodal embeddings, providing more opportunities for future advancements.
CEAR: Automatic construction of a knowledge graph of chemical entities and roles from scientific literature
Jul 31, 2024



Ontologies are formal representations of knowledge in specific domains that provide a structured framework for organizing and understanding complex information. Creating ontologies, however, is a complex and time-consuming endeavor. ChEBI is a well-known ontology in the field of chemistry, which provides a comprehensive resource for defining chemical entities and their properties. However, it covers only a small fraction of the rapidly growing knowledge in chemistry and does not provide references to the scientific literature. To address this, we propose a methodology that involves augmenting existing annotated text corpora with knowledge from Chebi and fine-tuning a large language model (LLM) to recognize chemical entities and their roles in scientific text. Our experiments demonstrate the effectiveness of our approach. By combining ontological knowledge and the language understanding capabilities of LLMs, we achieve high precision and recall rates in identifying both the chemical entities and roles in scientific literature. Furthermore, we extract them from a set of 8,000 ChemRxiv articles, and apply a second LLM to create a knowledge graph (KG) of chemical entities and roles (CEAR), which provides complementary information to ChEBI, and can help to extend it.
FhGenie: A Custom, Confidentiality-preserving Chat AI for Corporate and Scientific Use
Feb 29, 2024


Since OpenAI's release of ChatGPT, generative AI has received significant attention across various domains. These AI-based chat systems have the potential to enhance the productivity of knowledge workers in diverse tasks. However, the use of free public services poses a risk of data leakage, as service providers may exploit user input for additional training and optimization without clear boundaries. Even subscription-based alternatives sometimes lack transparency in handling user data. To address these concerns and enable Fraunhofer staff to leverage this technology while ensuring confidentiality, we have designed and developed a customized chat AI called FhGenie (genie being a reference to a helpful spirit). Within few days of its release, thousands of Fraunhofer employees started using this service. As pioneers in implementing such a system, many other organizations have followed suit. Our solution builds upon commercial large language models (LLMs), which we have carefully integrated into our system to meet our specific requirements and compliance constraints, including confidentiality and GDPR. In this paper, we share detailed insights into the architectural considerations, design, implementation, and subsequent updates of FhGenie. Additionally, we discuss challenges, observations, and the core lessons learned from its productive usage.
Domain Adaptive Pretraining for Multilingual Acronym Extraction
Jun 30, 2022

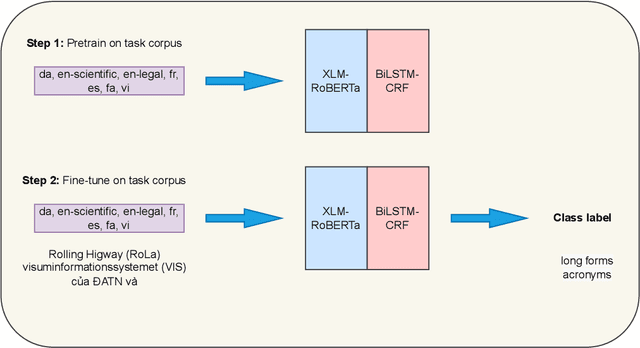
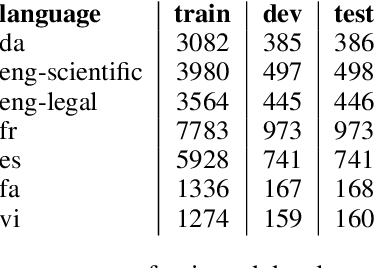
This paper presents our findings from participating in the multilingual acronym extraction shared task SDU@AAAI-22. The task consists of acronym extraction from documents in 6 languages within scientific and legal domains. To address multilingual acronym extraction we employed BiLSTM-CRF with multilingual XLM-RoBERTa embeddings. We pretrained the XLM-RoBERTa model on the shared task corpus to further adapt XLM-RoBERTa embeddings to the shared task domain(s). Our system (team: SMR-NLP) achieved competitive performance for acronym extraction across all the languages.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Data Augmentation for Low-Resource Named Entity Recognition Using Backtranslation
Aug 26, 2021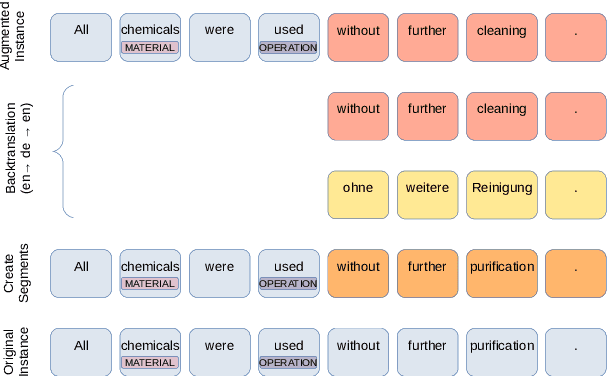
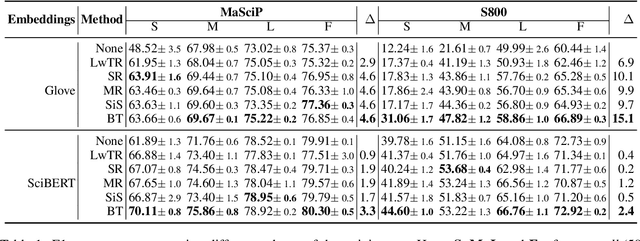
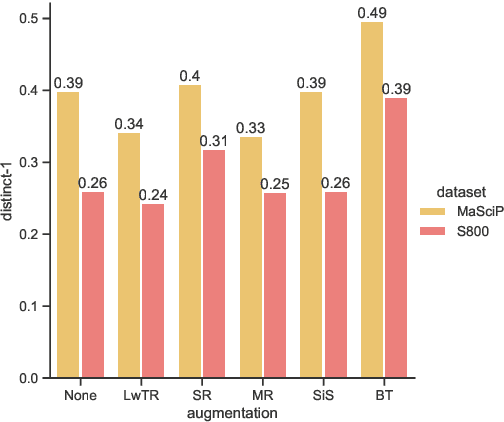
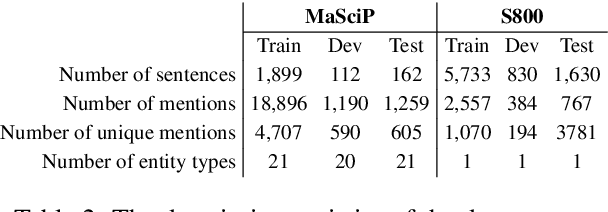
The state of art natural language processing systems relies on sizable training datasets to achieve high performance. Lack of such datasets in the specialized low resource domains lead to suboptimal performance. In this work, we adapt backtranslation to generate high quality and linguistically diverse synthetic data for low-resource named entity recognition. We perform experiments on two datasets from the materials science (MaSciP) and biomedical domains (S800). The empirical results demonstrate the effectiveness of our proposed augmentation strategy, particularly in the low-resource scenario.
Neural Text Classification and Stacked Heterogeneous Embeddings for Named Entity Recognition in SMM4H 2021
Jun 11, 2021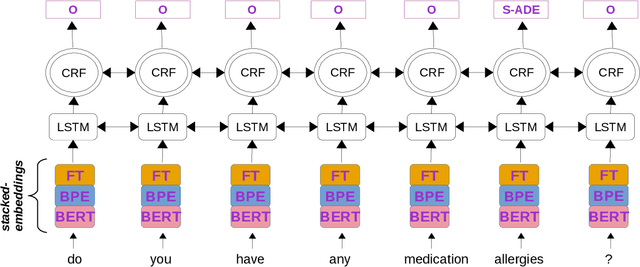

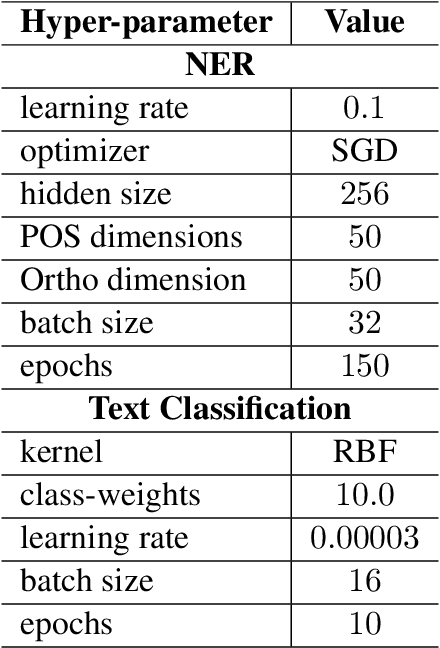
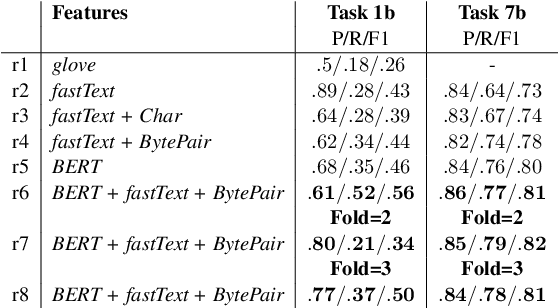
This paper presents our findings from participating in the SMM4H Shared Task 2021. We addressed Named Entity Recognition (NER) and Text Classification. To address NER we explored BiLSTM-CRF with Stacked Heterogeneous Embeddings and linguistic features. We investigated various machine learning algorithms (logistic regression, Support Vector Machine (SVM) and Neural Networks) to address text classification. Our proposed approaches can be generalized to different languages and we have shown its effectiveness for English and Spanish. Our text classification submissions (team:MIC-NLP) have achieved competitive performance with F1-score of $0.46$ and $0.90$ on ADE Classification (Task 1a) and Profession Classification (Task 7a) respectively. In the case of NER, our submissions scored F1-score of $0.50$ and $0.82$ on ADE Span Detection (Task 1b) and Profession Span detection (Task 7b) respectively.
Difficulty Classification of Mountainbike Downhill Trails utilizing Deep Neural Networks
Aug 05, 2019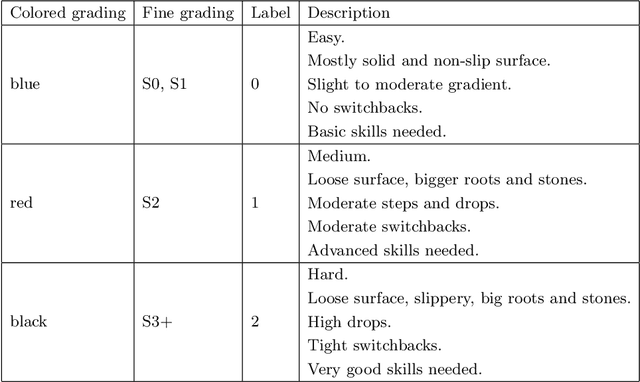


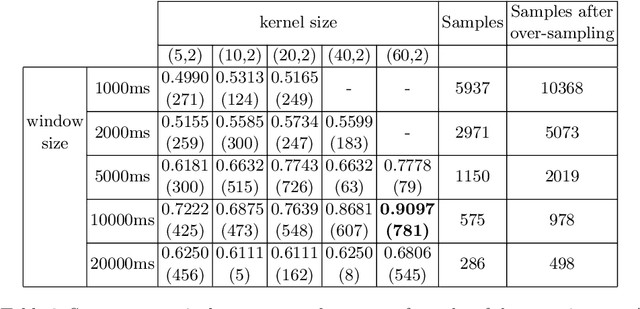
The difficulty of mountainbike downhill trails is a subjective perception. However, sports-associations and mountainbike park operators attempt to group trails into different levels of difficulty with scales like the Singletrail-Skala (S0-S5) or colored scales (blue, red, black, ...) as proposed by The International Mountain Bicycling Association. Inconsistencies in difficulty grading occur due to the various scales, different people grading the trails, differences in topography, and more. We propose an end-to-end deep learning approach to classify trails into three difficulties easy, medium, and hard by using sensor data. With mbientlab Meta Motion r0.2 sensor units, we record accelerometer- and gyroscope data of one rider on multiple trail segments. A 2D convolutional neural network is trained with a stacked and concatenated representation of the aforementioned data as its input. We run experiments with five different sample- and five different kernel sizes and achieve a maximum Sparse Categorical Accuracy of 0.9097. To the best of our knowledge, this is the first work targeting computational difficulty classification of mountainbike downhill trails.
Soccer Team Vectors
Jul 30, 2019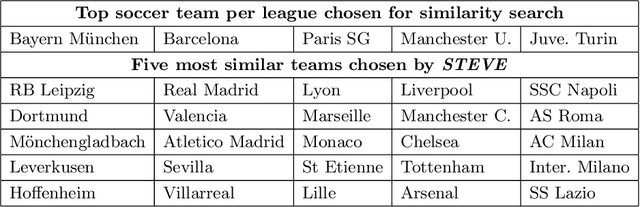

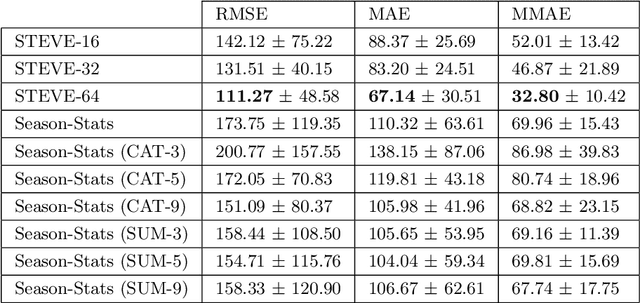
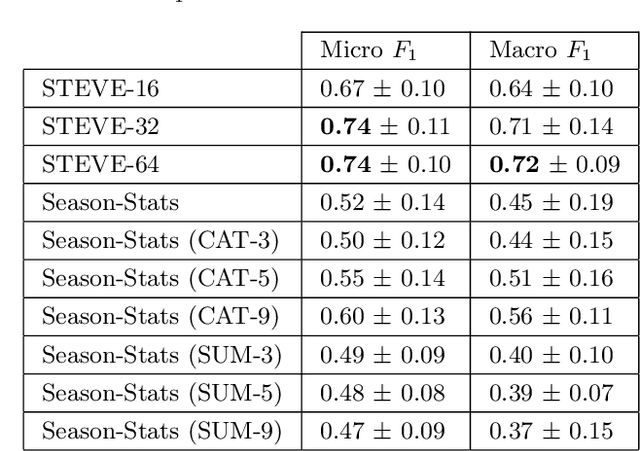
In this work we present STEVE - Soccer TEam VEctors, a principled approach for learning real valued vectors for soccer teams where similar teams are close to each other in the resulting vector space. STEVE only relies on freely available information about the matches teams played in the past. These vectors can serve as input to various machine learning tasks. Evaluating on the task of team market value estimation, STEVE outperforms all its competitors. Moreover, we use STEVE for similarity search and to rank soccer teams.
Deep Neural Baselines for Computational Paralinguistics
Jul 05, 2019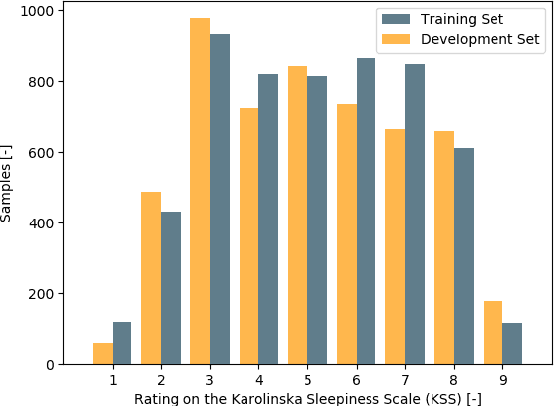
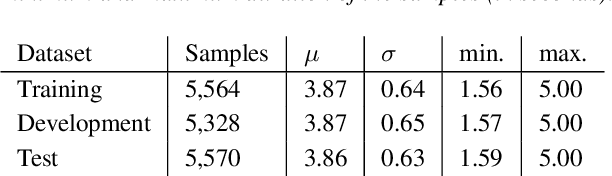
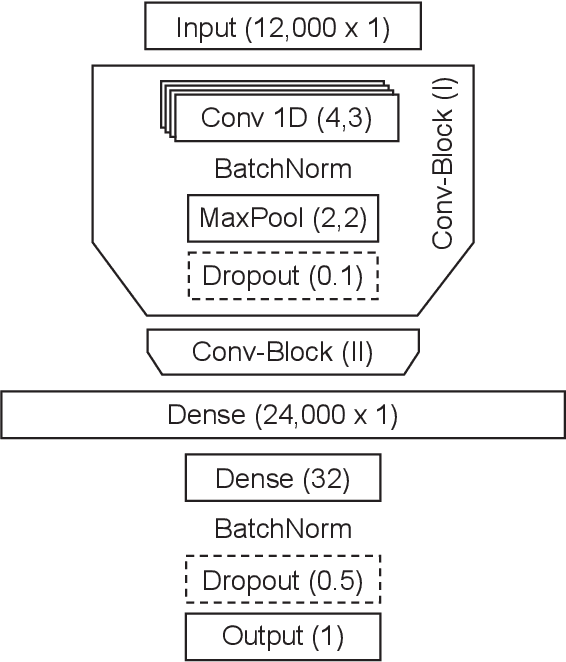
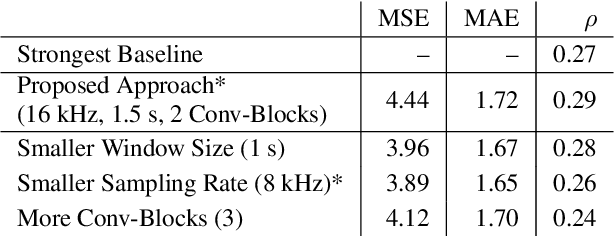
Detecting sleepiness from spoken language is an ambitious task, which is addressed by the Interspeech 2019 Computational Paralinguistics Challenge (ComParE). We propose an end-to-end deep learning approach to detect and classify patterns reflecting sleepiness in the human voice. Our approach is based solely on a moderately complex deep neural network architecture. It may be applied directly on the audio data without requiring any specific feature engineering, thus remaining transferable to other audio classification tasks. Nevertheless, our approach performs similar to state-of-the-art machine learning models.