 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Reservoir Management through Deep Reinforcement Learning
Dec 07, 2020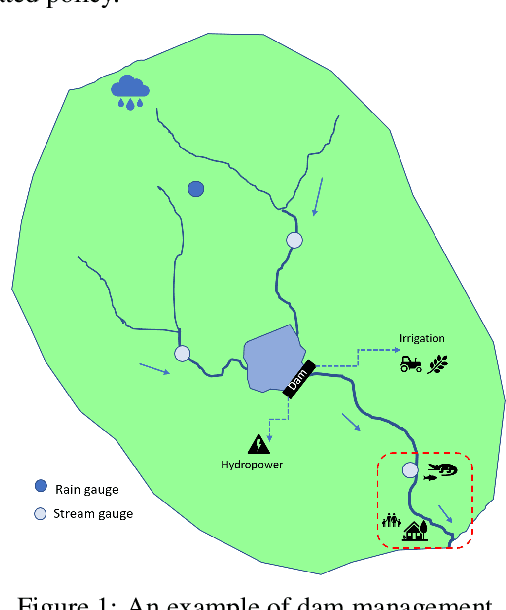

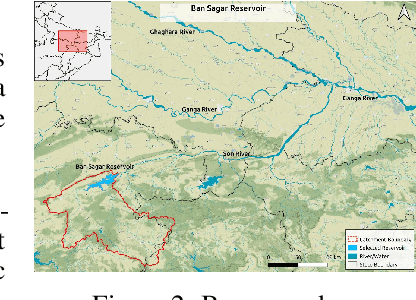
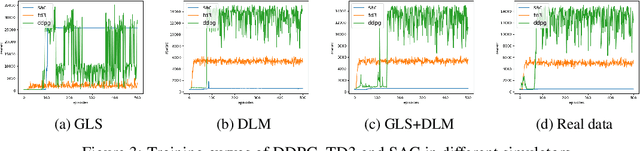
Dams impact downstream river dynamics through flow regulation and disruption of upstream-downstream linkages. However, current dam operation is far from satisfactory due to the inability to respond the complicated and uncertain dynamics of the upstream-downstream system and various usages of the reservoir. Even further, the unsatisfactory dam operation can cause floods in downstream areas. Therefore, we leverage reinforcement learning (RL) methods to compute efficient dam operation guidelines in this work. Specifically, we build offline simulators with real data and different mathematical models for the upstream inflow, i.e., generalized least square (GLS) and dynamic linear model (DLM), then use the simulator to train the state-of-the-art RL algorithms, including DDPG, TD3 and SAC. Experiments show that the simulator with DLM can efficiently model the inflow dynamics in the upstream and the dam operation policies trained by RL algorithms significantly outperform the human-generated policy.