 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Adversarial Robustness of Mixture of Experts
Oct 19, 2022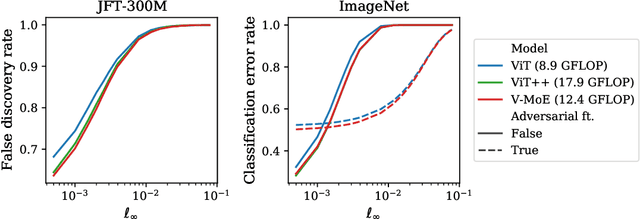
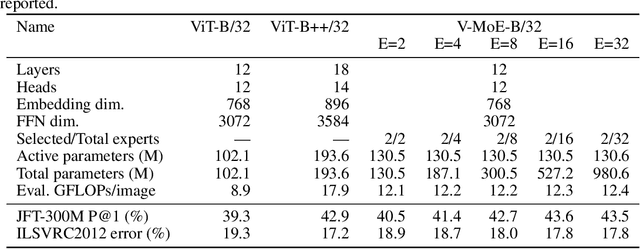
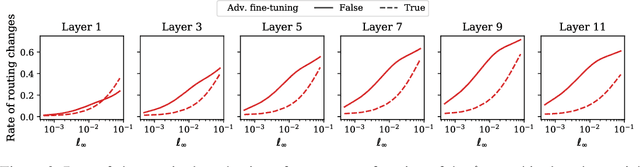
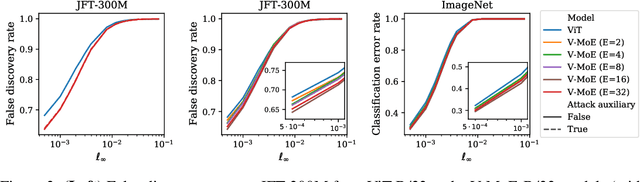
Adversarial robustness is a key desirable property of neural networks. It has been empirically shown to be affected by their sizes, with larger networks being typically more robust. Recently, Bubeck and Sellke proved a lower bound on the Lipschitz constant of functions that fit the training data in terms of their number of parameters. This raises an interesting open question, do -- and can -- functions with more parameters, but not necessarily more computational cost, have better robustness? We study this question for sparse Mixture of Expert models (MoEs), that make it possible to scale up the model size for a roughly constant computational cost. We theoretically show that under certain conditions on the routing and the structure of the data, MoEs can have significantly smaller Lipschitz constants than their dense counterparts. The robustness of MoEs can suffer when the highest weighted experts for an input implement sufficiently different functions. We next empirically evaluate the robustness of MoEs on ImageNet using adversarial attacks and show they are indeed more robust than dense models with the same computational cost. We make key observations showing the robustness of MoEs to the choice of experts, highlighting the redundancy of experts in models trained in practice.
Large Models are Parsimonious Learners: Activation Sparsity in Trained Transformers
Oct 12, 2022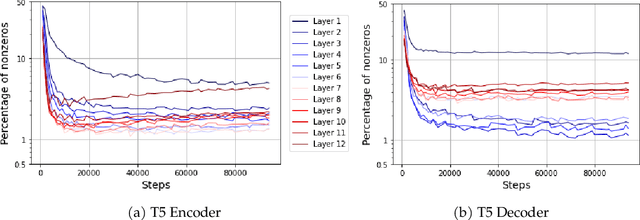

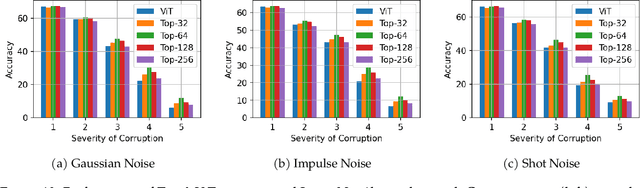
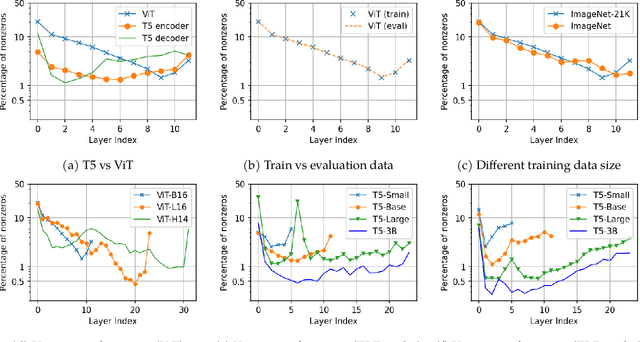
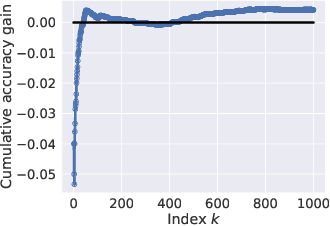
This paper studies the curious phenomenon for machine learning models with Transformer architectures that their activation maps are sparse. By activation map we refer to the intermediate output of the multi-layer perceptrons (MLPs) after a ReLU activation function, and by "sparse" we mean that on average very few entries (e.g., 3.0% for T5-Base and 6.3% for ViT-B16) are nonzero for each input to MLP. Moreover, larger Transformers with more layers and wider MLP hidden dimensions are sparser as measured by the percentage of nonzero entries. Through extensive experiments we demonstrate that the emergence of sparsity is a prevalent phenomenon that occurs for both natural language processing and vision tasks, on both training and evaluation data, for Transformers of various configurations, at layers of all depth levels, as well as for other architectures including MLP-mixers and 2-layer MLPs. We show that sparsity also emerges using training datasets with random labels, or with random inputs, or with infinite amount of data, demonstrating that sparsity is not a result of a specific family of datasets. We discuss how sparsity immediately implies a way to significantly reduce the FLOP count and improve efficiency for Transformers. Moreover, we demonstrate perhaps surprisingly that enforcing an even sparser activation via Top-k thresholding with a small value of k brings a collection of desired but missing properties for Transformers, namely less sensitivity to noisy training data, more robustness to input corruptions, and better calibration for their prediction confidence.
Treeformer: Dense Gradient Trees for Efficient Attention Computation
Aug 18, 2022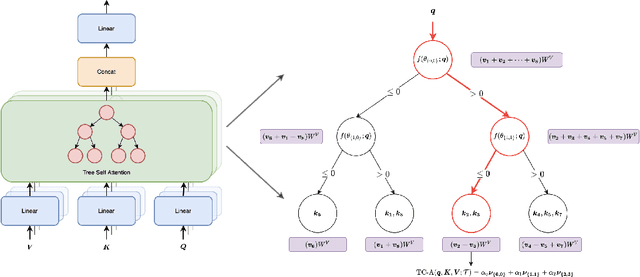
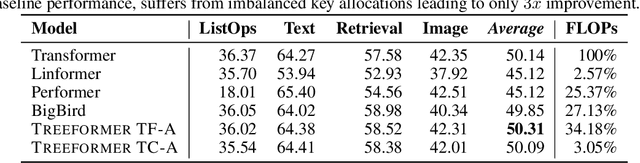
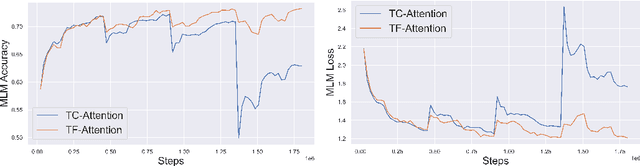
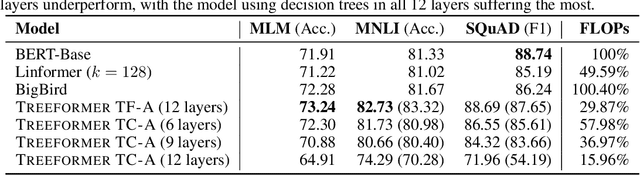
Standard inference and training with transformer based architectures scale quadratically with input sequence length. This is prohibitively large for a variety of applications especially in web-page translation, query-answering etc. Consequently, several approaches have been developed recently to speedup attention computation by enforcing different attention structures such as sparsity, low-rank, approximating attention using kernels. In this work, we view attention computation as that of nearest neighbor retrieval, and use decision tree based hierarchical navigation to reduce the retrieval cost per query token from linear in sequence length to nearly logarithmic. Based on such hierarchical navigation, we design Treeformer which can use one of two efficient attention layers -- TF-Attention and TC-Attention. TF-Attention computes the attention in a fine-grained style, while TC-Attention is a coarse attention layer which also ensures that the gradients are "dense". To optimize such challenging discrete layers, we propose a two-level bootstrapped training method. Using extensive experiments on standard NLP benchmarks, especially for long-sequences, we demonstrate that our Treeformer architecture can be almost as accurate as baseline Transformer while using 30x lesser FLOPs in the attention layer. Compared to Linformer, the accuracy can be as much as 12% higher while using similar FLOPs in the attention layer.
Robust Training of Neural Networks using Scale Invariant Architectures
Feb 02, 2022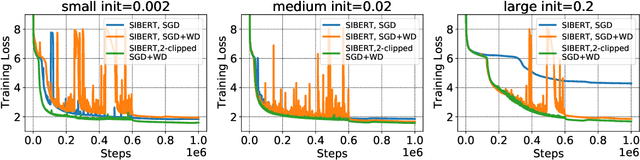
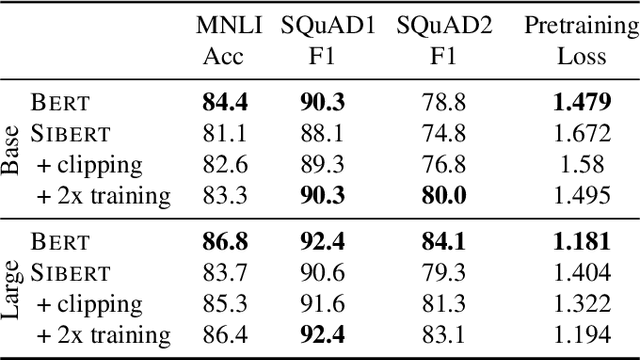
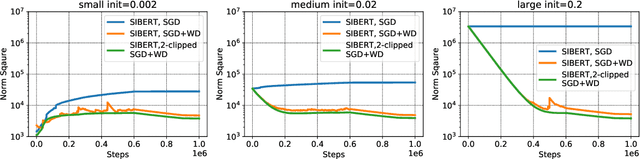

In contrast to SGD, adaptive gradient methods like Adam allow robust training of modern deep networks, especially large language models. However, the use of adaptivity not only comes at the cost of extra memory but also raises the fundamental question: can non-adaptive methods like SGD enjoy similar benefits? In this paper, we provide an affirmative answer to this question by proposing to achieve both robust and memory-efficient training via the following general recipe: (1) modify the architecture and make it scale invariant, i.e. the scale of parameter doesn't affect the output of the network, (2) train with SGD and weight decay, and optionally (3) clip the global gradient norm proportional to weight norm multiplied by $\sqrt{\tfrac{2\lambda}{\eta}}$, where $\eta$ is learning rate and $\lambda$ is weight decay. We show that this general approach is robust to rescaling of parameter and loss by proving that its convergence only depends logarithmically on the scale of initialization and loss, whereas the standard SGD might not even converge for many initializations. Following our recipe, we design a scale invariant version of BERT, called SIBERT, which when trained simply by vanilla SGD achieves performance comparable to BERT trained by adaptive methods like Adam on downstream tasks.
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021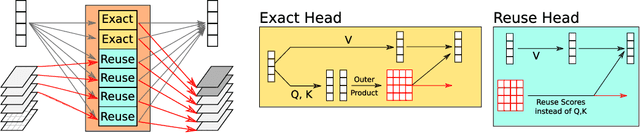
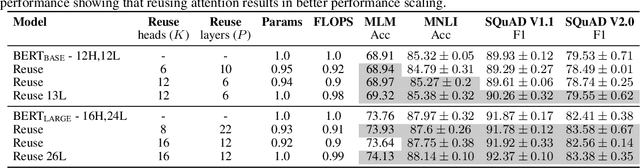
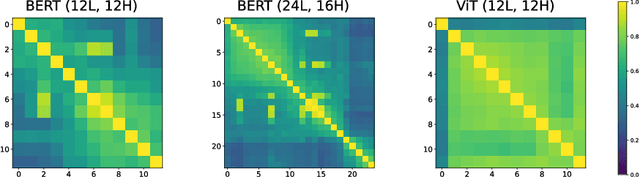
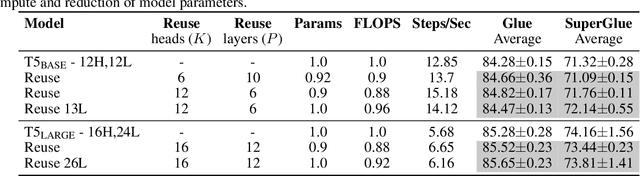
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Teacher's pet: understanding and mitigating biases in distillation
Jul 08, 2021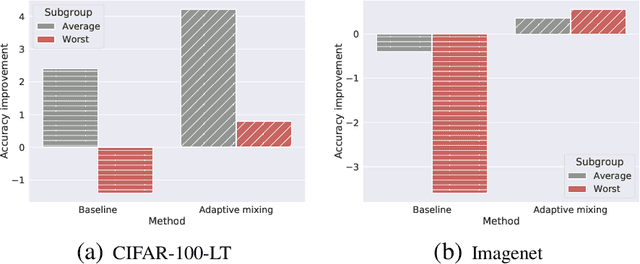

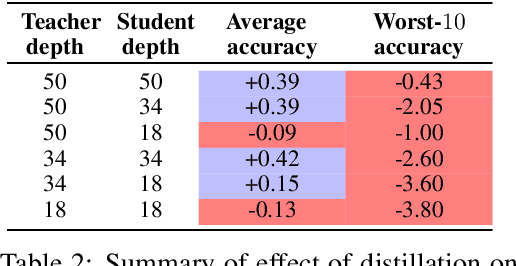
Knowledge distillation is widely used as a means of improving the performance of a relatively simple student model using the predictions from a complex teacher model. Several works have shown that distillation significantly boosts the student's overall performance; however, are these gains uniform across all data subgroups? In this paper, we show that distillation can harm performance on certain subgroups, e.g., classes with few associated samples. We trace this behaviour to errors made by the teacher distribution being transferred to and amplified by the student model. To mitigate this problem, we present techniques which soften the teacher influence for subgroups where it is less reliable. Experiments on several image classification benchmarks show that these modifications of distillation maintain boost in overall accuracy, while additionally ensuring improvement in subgroup performance.
Eigen Analysis of Self-Attention and its Reconstruction from Partial Computation
Jun 16, 2021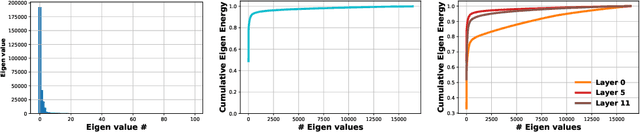
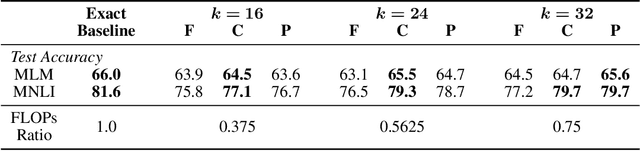
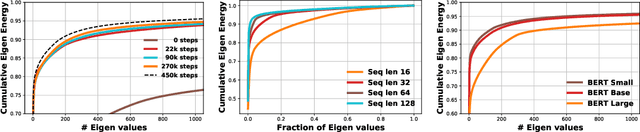
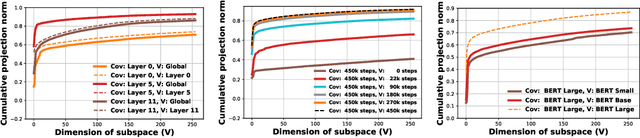
State-of-the-art transformer models use pairwise dot-product based self-attention, which comes at a computational cost quadratic in the input sequence length. In this paper, we investigate the global structure of attention scores computed using this dot product mechanism on a typical distribution of inputs, and study the principal components of their variation. Through eigen analysis of full attention score matrices, as well as of their individual rows, we find that most of the variation among attention scores lie in a low-dimensional eigenspace. Moreover, we find significant overlap between these eigenspaces for different layers and even different transformer models. Based on this, we propose to compute scores only for a partial subset of token pairs, and use them to estimate scores for the remaining pairs. Beyond investigating the accuracy of reconstructing attention scores themselves, we investigate training transformer models that employ these approximations, and analyze the effect on overall accuracy. Our analysis and the proposed method provide insights into how to balance the benefits of exact pair-wise attention and its significant computational expense.
Demystifying the Better Performance of Position Encoding Variants for Transformer
Apr 18, 2021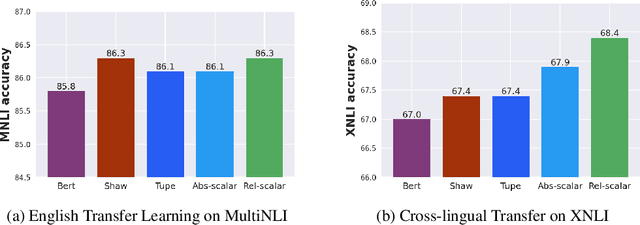

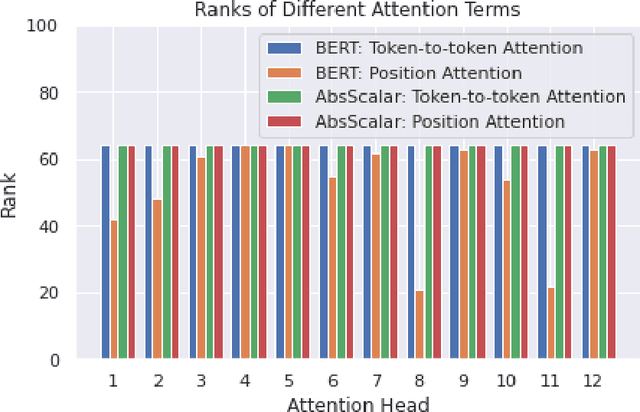

Transformers are state of the art models in NLP that map a given input sequence of vectors to an output sequence of vectors. However these models are permutation equivariant, and additive position embeddings to the input are used to supply the information about the order of the input tokens. Further, for some tasks, additional additive segment embeddings are used to denote different types of input sentences. Recent works proposed variations of positional encodings with relative position encodings achieving better performance. In this work, we do a systematic study comparing different position encodings and understanding the reasons for differences in their performance. We demonstrate a simple yet effective way to encode position and segment into the Transformer models. The proposed method performs on par with SOTA on GLUE, XTREME and WMT benchmarks while saving computation costs.
Understanding Robustness of Transformers for Image Classification
Mar 26, 2021
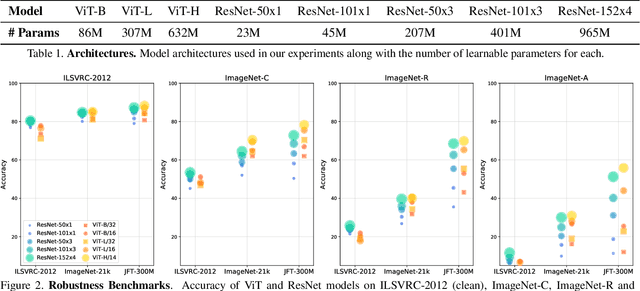
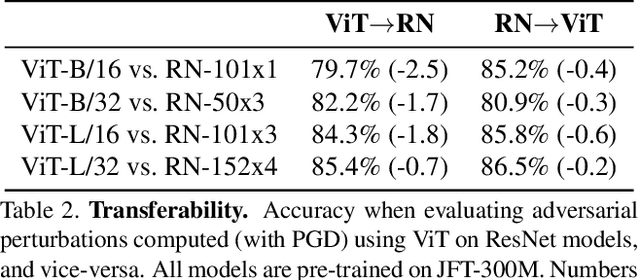

Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture -- such as the use of non-overlapping patches -- lead one to wonder whether these networks are as robust. In this paper, we perform an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. We investigate robustness to input perturbations as well as robustness to model perturbations. We find that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. We also find that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
On the Reproducibility of Neural Network Predictions
Feb 05, 2021

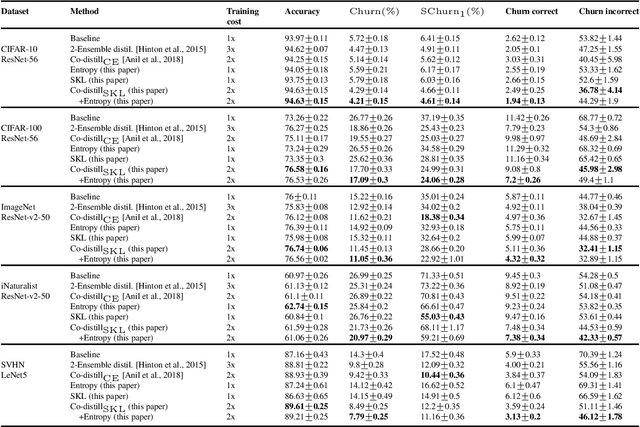
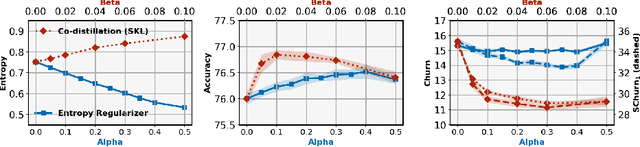
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.