 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark3R: Learning Structure from Motion in the Dark
Mar 05, 2026We introduce Dark3R, a framework for structure from motion in the dark that operates directly on raw images with signal-to-noise ratios (SNRs) below $-4$ dB -- a regime where conventional feature- and learning-based methods break down. Our key insight is to adapt large-scale 3D foundation models to extreme low-light conditions through a teacher--student distillation process, enabling robust feature matching and camera pose estimation in low light. Dark3R requires no 3D supervision; it is trained solely on noisy--clean raw image pairs, which can be either captured directly or synthesized using a simple Poisson--Gaussian noise model applied to well-exposed raw images. To train and evaluate our approach, we introduce a new, exposure-bracketed dataset that includes $\sim$42,000 multi-view raw images with ground-truth 3D annotations, and we demonstrate that Dark3R achieves state-of-the-art structure from motion in the low-SNR regime. Further, we demonstrate state-of-the-art novel view synthesis in the dark using Dark3R's predicted poses and a coarse-to-fine radiance field optimization procedure.
Transient Neural Radiance Fields for Lidar View Synthesis and 3D Reconstruction
Jul 14, 2023Neural radiance fields (NeRFs) have become a ubiquitous tool for modeling scene appearance and geometry from multiview imagery. Recent work has also begun to explore how to use additional supervision from lidar or depth sensor measurements in the NeRF framework. However, previous lidar-supervised NeRFs focus on rendering conventional camera imagery and use lidar-derived point cloud data as auxiliary supervision; thus, they fail to incorporate the underlying image formation model of the lidar. Here, we propose a novel method for rendering transient NeRFs that take as input the raw, time-resolved photon count histograms measured by a single-photon lidar system, and we seek to render such histograms from novel views. Different from conventional NeRFs, the approach relies on a time-resolved version of the volume rendering equation to render the lidar measurements and capture transient light transport phenomena at picosecond timescales. We evaluate our method on a first-of-its-kind dataset of simulated and captured transient multiview scans from a prototype single-photon lidar. Overall, our work brings NeRFs to a new dimension of imaging at transient timescales, newly enabling rendering of transient imagery from novel views. Additionally, we show that our approach recovers improved geometry and conventional appearance compared to point cloud-based supervision when training on few input viewpoints. Transient NeRFs may be especially useful for applications which seek to simulate raw lidar measurements for downstream tasks in autonomous driving, robotics, and remote sensing.
Part-to-whole Registration of Histology and MRI using Shape Elements
Aug 27, 2017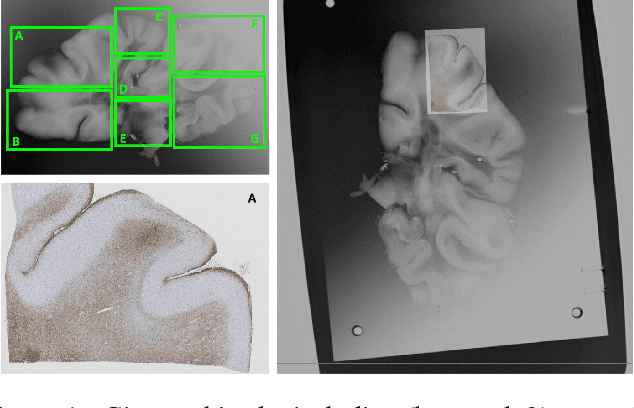

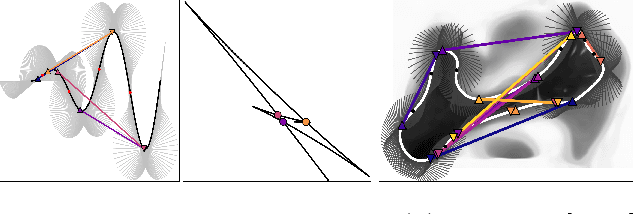
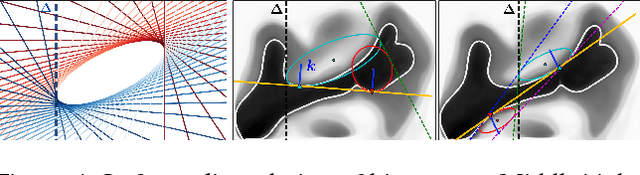
Image registration between histology and magnetic resonance imaging (MRI) is a challenging task due to differences in structural content and contrast. Too thick and wide specimens cannot be processed all at once and must be cut into smaller pieces. This dramatically increases the complexity of the problem, since each piece should be individually and manually pre-aligned. To the best of our knowledge, no automatic method can reliably locate such piece of tissue within its respective whole in the MRI slice, and align it without any prior information. We propose here a novel automatic approach to the joint problem of multimodal registration between histology and MRI, when only a fraction of tissue is available from histology. The approach relies on the representation of images using their level lines so as to reach contrast invariance. Shape elements obtained via the extraction of bitangents are encoded in a projective-invariant manner, which permits the identification of common pieces of curves between two images. We evaluated the approach on human brain histology and compared resulting alignments against manually annotated ground truths. Considering the complexity of the brain folding patterns, preliminary results are promising and suggest the use of characteristic and meaningful shape elements for improved robustness and efficiency.