 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Improving Medical Annotation Quality to Decrease Labeling Burden Using Stratified Noisy Cross-Validation
Sep 22, 2020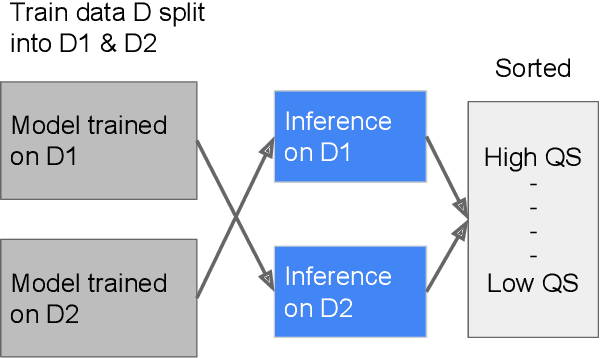

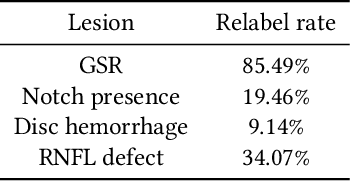
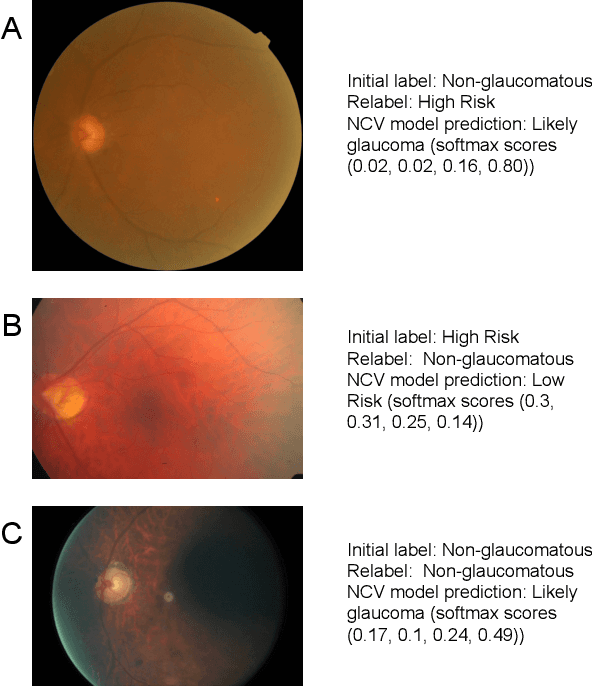
As machine learning has become increasingly applied to medical imaging data, noise in training labels has emerged as an important challenge. Variability in diagnosis of medical images is well established; in addition, variability in training and attention to task among medical labelers may exacerbate this issue. Methods for identifying and mitigating the impact of low quality labels have been studied, but are not well characterized in medical imaging tasks. For instance, Noisy Cross-Validation splits the training data into halves, and has been shown to identify low-quality labels in computer vision tasks; but it has not been applied to medical imaging tasks specifically. In this work we introduce Stratified Noisy Cross-Validation (SNCV), an extension of noisy cross validation. SNCV can provide estimates of confidence in model predictions by assigning a quality score to each example; stratify labels to handle class imbalance; and identify likely low-quality labels to analyze the causes. We assess performance of SNCV on diagnosis of glaucoma suspect risk from retinal fundus photographs, a clinically important yet nuanced labeling task. Using training data from a previously-published deep learning model, we compute a continuous quality score (QS) for each training example. We relabel 1,277 low-QS examples using a trained glaucoma specialist; the new labels agree with the SNCV prediction over the initial label >85% of the time, indicating that low-QS examples mostly reflect labeler errors. We then quantify the impact of training with only high-QS labels, showing that strong model performance may be obtained with many fewer examples. By applying the method to randomly sub-sampled training dataset, we show that our method can reduce labelling burden by approximately 50% while achieving model performance non-inferior to using the full dataset on multiple held-out test sets.
Deep Learning to Assess Glaucoma Risk and Associated Features in Fundus Images
Dec 21, 2018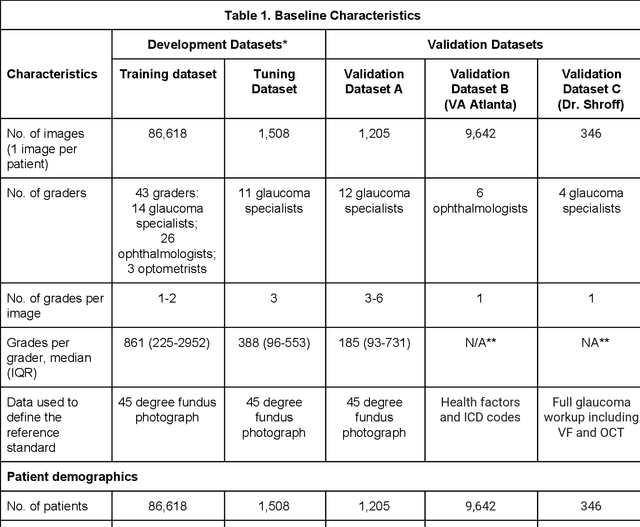
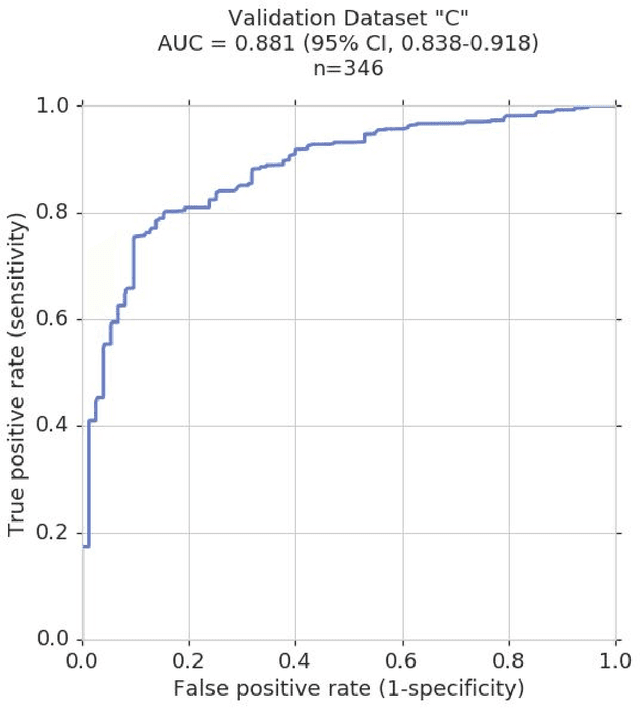
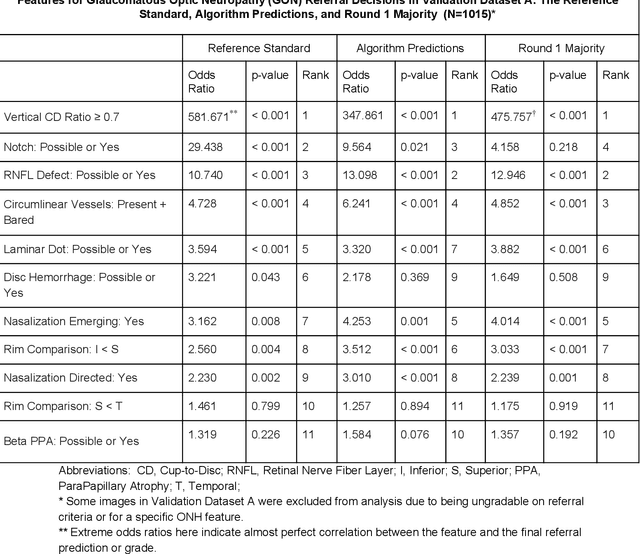
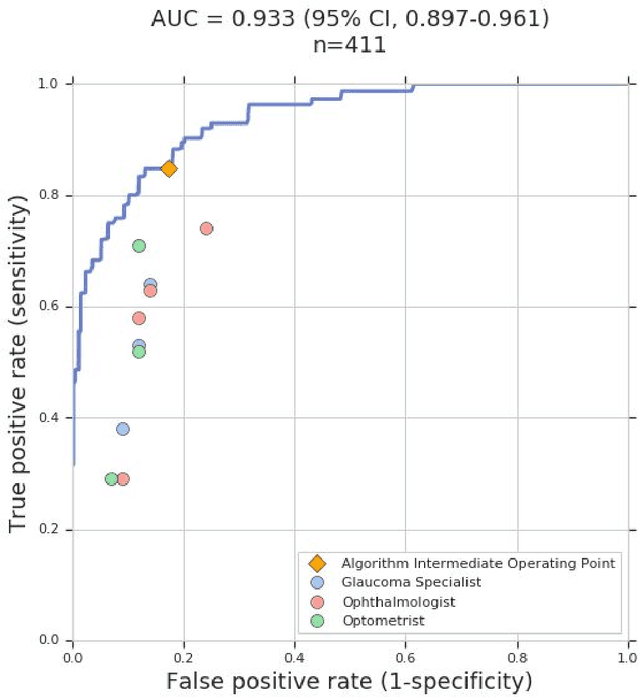
Glaucoma is the leading cause of preventable, irreversible blindness world-wide. The disease can remain asymptomatic until severe, and an estimated 50%-90% of people with glaucoma remain undiagnosed. Thus, glaucoma screening is recommended for early detection and treatment. A cost-effective tool to detect glaucoma could expand healthcare access to a much larger patient population, but such a tool is currently unavailable. We trained a deep learning (DL) algorithm using a retrospective dataset of 58,033 images, assessed for gradability, glaucomatous optic nerve head (ONH) features, and referable glaucoma risk. The resultant algorithm was validated using 2 separate datasets. For referable glaucoma risk, the algorithm had an AUC of 0.940 (95%CI, 0.922-0.955) in validation dataset "A" (1,205 images, 1 image/patient; 19% referable where images were adjudicated by panels of fellowship-trained glaucoma specialists) and 0.858 (95% CI, 0.836-0.878) in validation dataset "B" (17,593 images from 9,643 patients; 9.2% referable where images were from the Atlanta Veterans Affairs Eye Clinic diabetic teleretinal screening program using clinical referral decisions as the reference standard). Additionally, we found that the presence of vertical cup-to-disc ratio >= 0.7, neuroretinal rim notching, retinal nerve fiber layer defect, and bared circumlinear vessels contributed most to referable glaucoma risk assessment by both glaucoma specialists and the algorithm. Algorithm AUCs ranged between 0.608-0.977 for glaucomatous ONH features. The DL algorithm was significantly more sensitive than 6 of 10 graders, including 2 of 3 glaucoma specialists, with comparable or higher specificity relative to all graders. A DL algorithm trained on fundus images alone can detect referable glaucoma risk with higher sensitivity and comparable specificity to eye care providers.
Deep Learning vs. Human Graders for Classifying Severity Levels of Diabetic Retinopathy in a Real-World Nationwide Screening Program
Oct 18, 2018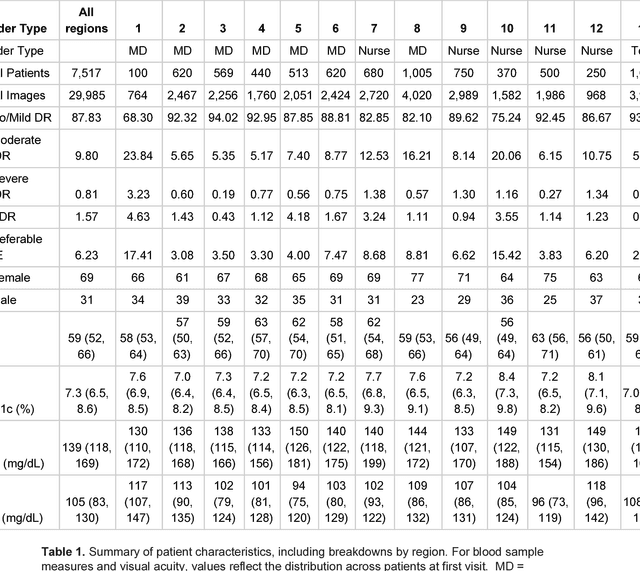
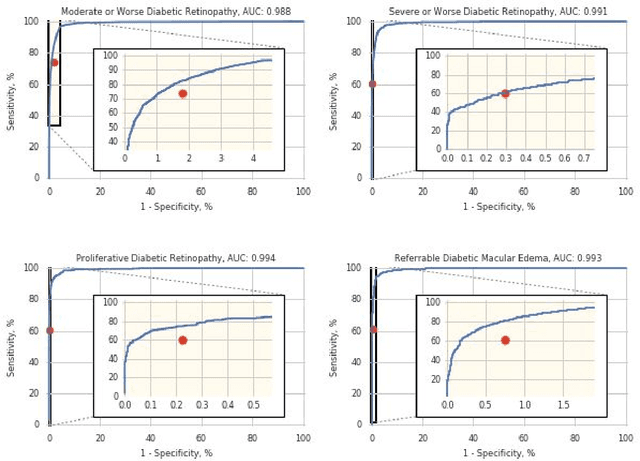
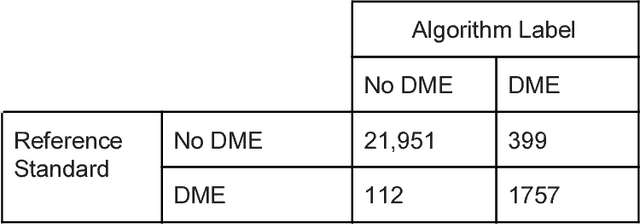
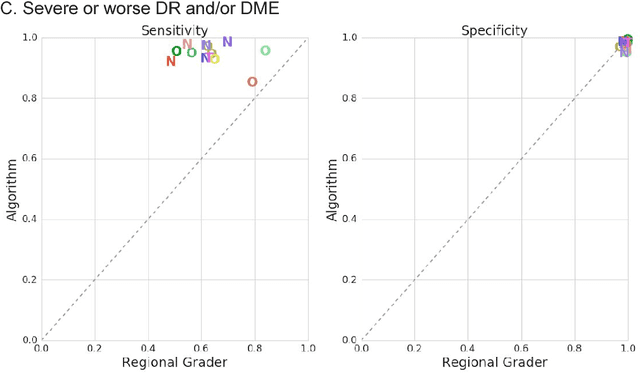
Deep learning algorithms have been used to detect diabetic retinopathy (DR) with specialist-level accuracy. This study aims to validate one such algorithm on a large-scale clinical population, and compare the algorithm performance with that of human graders. 25,326 gradable retinal images of patients with diabetes from the community-based, nation-wide screening program of DR in Thailand were analyzed for DR severity and referable diabetic macular edema (DME). Grades adjudicated by a panel of international retinal specialists served as the reference standard. Across different severity levels of DR for determining referable disease, deep learning significantly reduced the false negative rate (by 23%) at the cost of slightly higher false positive rates (2%). Deep learning algorithms may serve as a valuable tool for DR screening.