 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning vs. Human Graders for Classifying Severity Levels of Diabetic Retinopathy in a Real-World Nationwide Screening Program
Oct 18, 2018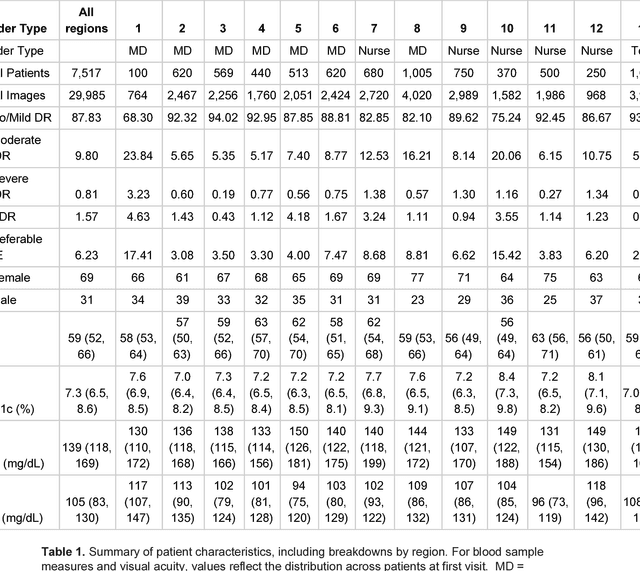
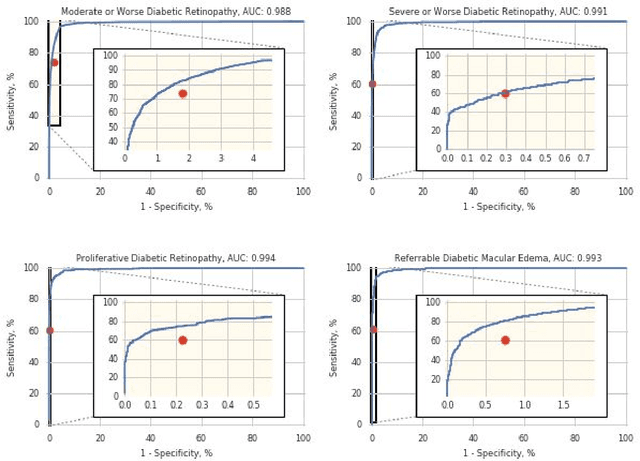
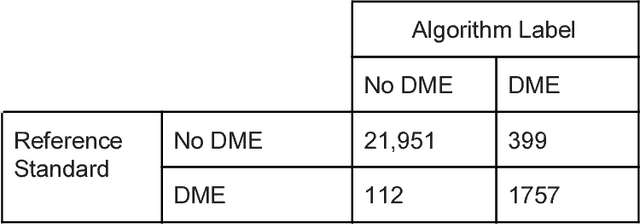
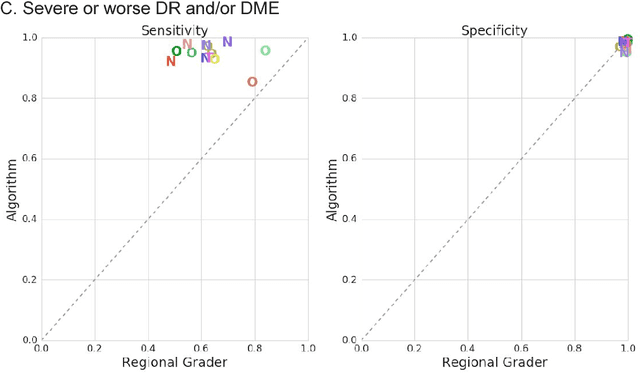
Deep learning algorithms have been used to detect diabetic retinopathy (DR) with specialist-level accuracy. This study aims to validate one such algorithm on a large-scale clinical population, and compare the algorithm performance with that of human graders. 25,326 gradable retinal images of patients with diabetes from the community-based, nation-wide screening program of DR in Thailand were analyzed for DR severity and referable diabetic macular edema (DME). Grades adjudicated by a panel of international retinal specialists served as the reference standard. Across different severity levels of DR for determining referable disease, deep learning significantly reduced the false negative rate (by 23%) at the cost of slightly higher false positive rates (2%). Deep learning algorithms may serve as a valuable tool for DR screening.
Grader variability and the importance of reference standards for evaluating machine learning models for diabetic retinopathy
Jul 03, 2018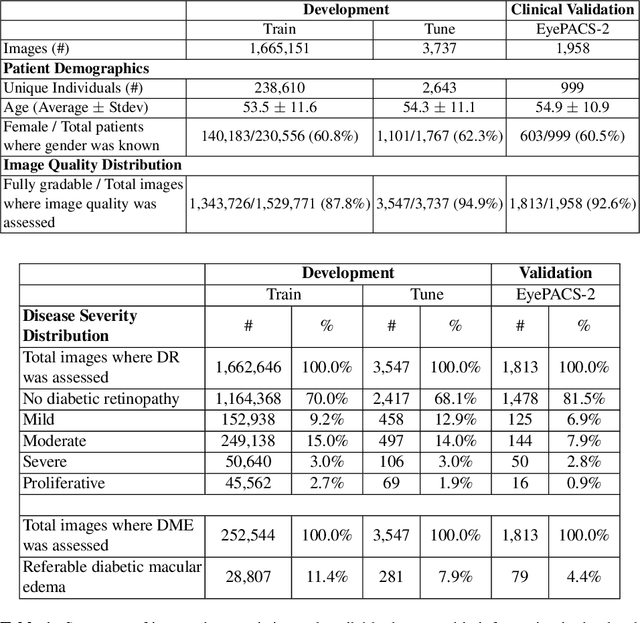
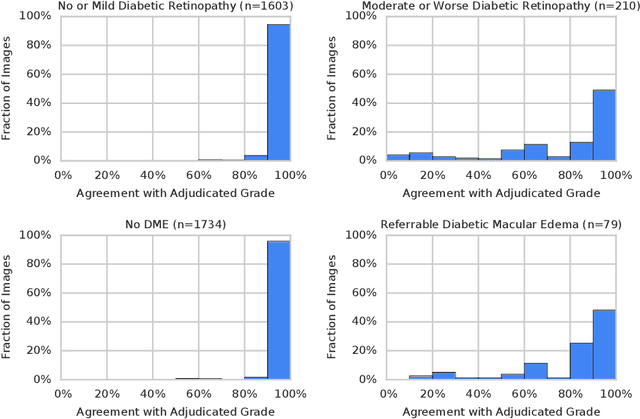
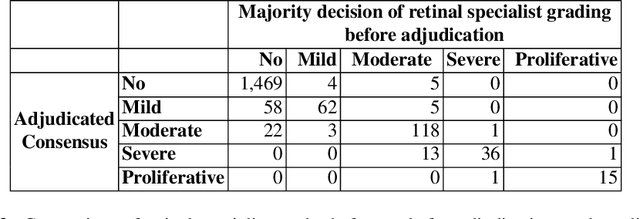
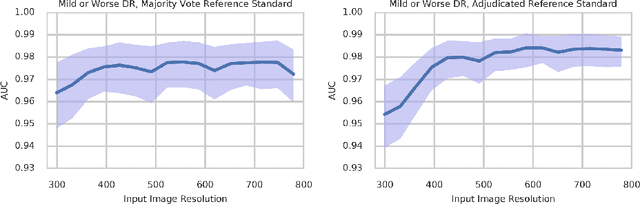
Diabetic retinopathy (DR) and diabetic macular edema are common complications of diabetes which can lead to vision loss. The grading of DR is a fairly complex process that requires the detection of fine features such as microaneurysms, intraretinal hemorrhages, and intraretinal microvascular abnormalities. Because of this, there can be a fair amount of grader variability. There are different methods of obtaining the reference standard and resolving disagreements between graders, and while it is usually accepted that adjudication until full consensus will yield the best reference standard, the difference between various methods of resolving disagreements has not been examined extensively. In this study, we examine the variability in different methods of grading, definitions of reference standards, and their effects on building deep learning models for the detection of diabetic eye disease. We find that a small set of adjudicated DR grades allows substantial improvements in algorithm performance. The resulting algorithm's performance was on par with that of individual U.S. board-certified ophthalmologists and retinal specialists.