 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Similarity-based Framework for Classification Task
Mar 05, 2022
Similarity-based method gives rise to a new class of methods for multi-label learning and also achieves promising performance. In this paper, we generalize this method, resulting in a new framework for classification task. Specifically, we unite similarity-based learning and generalized linear models to achieve the best of both worlds. This allows us to capture interdependencies between classes and prevent from impairing performance of noisy classes. Each learned parameter of the model can reveal the contribution of one class to another, providing interpretability to some extent. Experiment results show the effectiveness of the proposed approach on multi-class and multi-label datasets
Can Adversarial Training Be Manipulated By Non-Robust Features?
Jan 31, 2022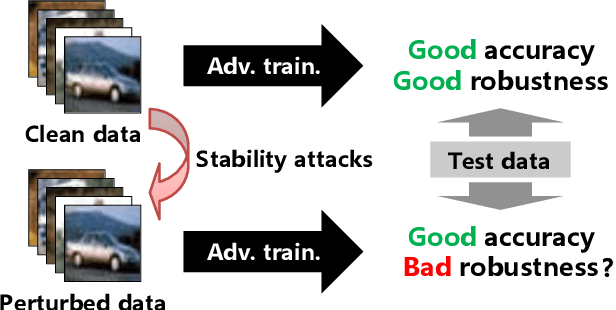
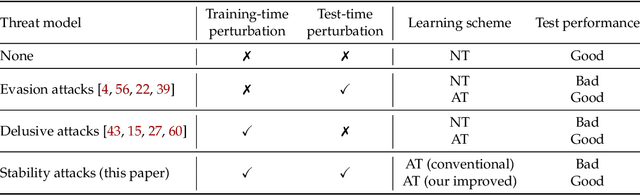
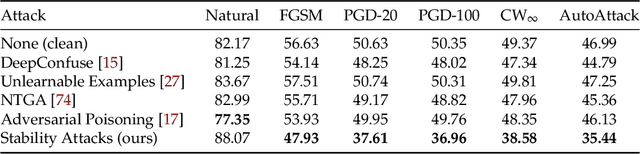
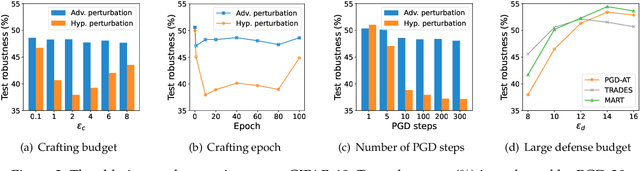
Adversarial training, originally designed to resist test-time adversarial examples, has shown to be promising in mitigating training-time availability attacks. This defense ability, however, is challenged in this paper. We identify a novel threat model named stability attacks, which aims to hinder robust availability by slightly perturbing the training data. Under this threat, we find that adversarial training using a conventional defense budget $\epsilon$ provably fails to provide test robustness in a simple statistical setting when the non-robust features of the training data are reinforced by $\epsilon$-bounded perturbation. Further, we analyze the necessity of enlarging the defense budget to counter stability attacks. Finally, comprehensive experiments demonstrate that stability attacks are harmful on benchmark datasets, and thus the adaptive defense is necessary to maintain robustness.
Learning Multi-Tasks with Inconsistent Labels by using Auxiliary Big Task
Jan 07, 2022



Multi-task learning is to improve the performance of the model by transferring and exploiting common knowledge among tasks. Existing MTL works mainly focus on the scenario where label sets among multiple tasks (MTs) are usually the same, thus they can be utilized for learning across the tasks. While almost rare works explore the scenario where each task only has a small amount of training samples, and their label sets are just partially overlapped or even not. Learning such MTs is more challenging because of less correlation information available among these tasks. For this, we propose a framework to learn these tasks by jointly leveraging both abundant information from a learnt auxiliary big task with sufficiently many classes to cover those of all these tasks and the information shared among those partially-overlapped tasks. In our implementation of using the same neural network architecture of the learnt auxiliary task to learn individual tasks, the key idea is to utilize available label information to adaptively prune the hidden layer neurons of the auxiliary network to construct corresponding network for each task, while accompanying a joint learning across individual tasks. Our experimental results demonstrate its effectiveness in comparison with the state-of-the-art approaches.
Partial Domain Adaptation without Domain Alignment
Aug 29, 2021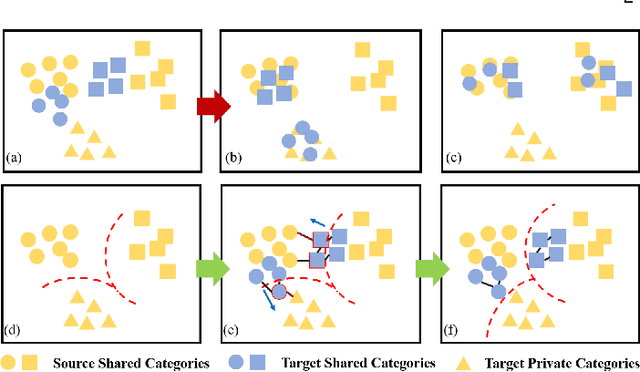
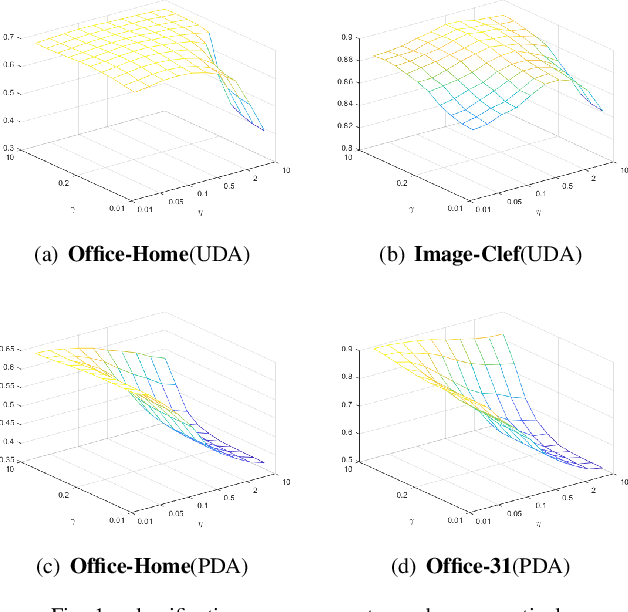
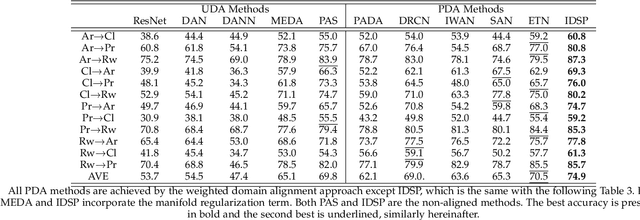
Unsupervised domain adaptation (UDA) aims to transfer knowledge from a well-labeled source domain to a different but related unlabeled target domain with identical label space. Currently, the main workhorse for solving UDA is domain alignment, which has proven successful. However, it is often difficult to find an appropriate source domain with identical label space. A more practical scenario is so-called partial domain adaptation (PDA) in which the source label set or space subsumes the target one. Unfortunately, in PDA, due to the existence of the irrelevant categories in the source domain, it is quite hard to obtain a perfect alignment, thus resulting in mode collapse and negative transfer. Although several efforts have been made by down-weighting the irrelevant source categories, the strategies used tend to be burdensome and risky since exactly which irrelevant categories are unknown. These challenges motivate us to find a relatively simpler alternative to solve PDA. To achieve this, we first provide a thorough theoretical analysis, which illustrates that the target risk is bounded by both model smoothness and between-domain discrepancy. Considering the difficulty of perfect alignment in solving PDA, we turn to focus on the model smoothness while discard the riskier domain alignment to enhance the adaptability of the model. Specifically, we instantiate the model smoothness as a quite simple intra-domain structure preserving (IDSP). To our best knowledge, this is the first naive attempt to address the PDA without domain alignment. Finally, our empirical results on multiple benchmark datasets demonstrate that IDSP is not only superior to the PDA SOTAs by a significant margin on some benchmarks (e.g., +10% on Cl->Rw and +8% on Ar->Rw ), but also complementary to domain alignment in the standard UDA
Improving Model Robustness by Adaptively Correcting Perturbation Levels with Active Queries
Mar 27, 2021
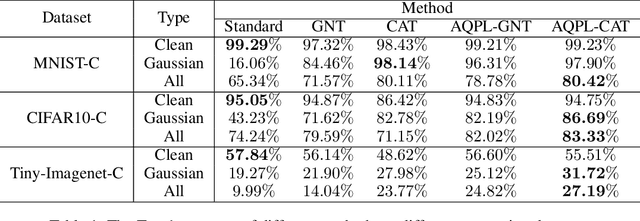
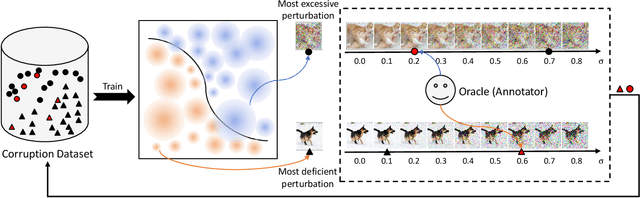
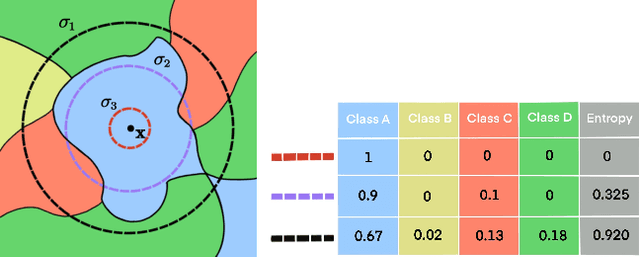
In addition to high accuracy, robustness is becoming increasingly important for machine learning models in various applications. Recently, much research has been devoted to improving the model robustness by training with noise perturbations. Most existing studies assume a fixed perturbation level for all training examples, which however hardly holds in real tasks. In fact, excessive perturbations may destroy the discriminative content of an example, while deficient perturbations may fail to provide helpful information for improving the robustness. Motivated by this observation, we propose to adaptively adjust the perturbation levels for each example in the training process. Specifically, a novel active learning framework is proposed to allow the model to interactively query the correct perturbation level from human experts. By designing a cost-effective sampling strategy along with a new query type, the robustness can be significantly improved with a few queries. Both theoretical analysis and experimental studies validate the effectiveness of the proposed approach.
Provable Defense Against Delusive Poisoning
Feb 09, 2021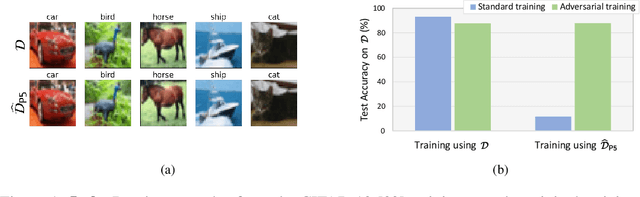
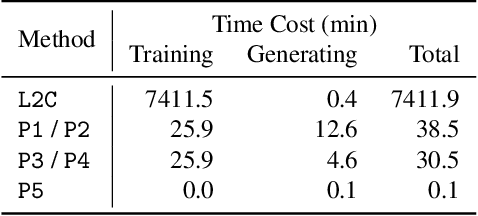
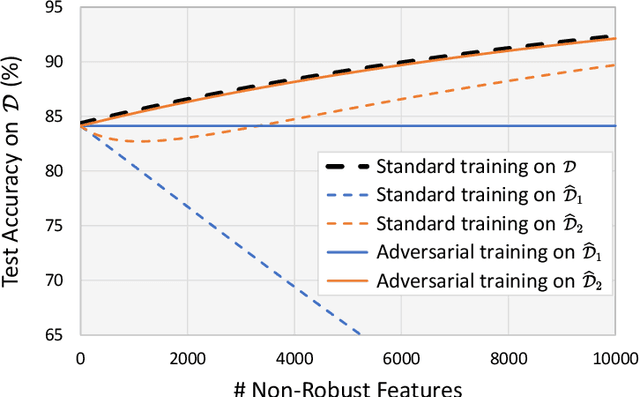
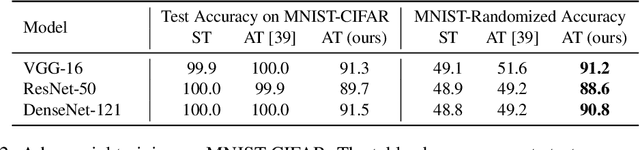
Delusive poisoning is a special kind of attack to obstruct learning, where the learning performance could be significantly deteriorated by only manipulating (even slightly) the features of correctly labeled training examples. By formalizing this malicious attack as finding the worst-case distribution shift at training time within a specific $\infty$-Wasserstein ball, we show that minimizing adversarial risk on the poison data is equivalent to optimizing an upper bound of natural risk on the original data. This implies that adversarial training can be a principled defense method against delusive poisoning. To further understand the internal mechanism of the defense, we disclose that adversarial training can resist the training distribution shift by preventing the learner from overly relying on non-robust features in a natural setting. Finally, we complement our theoretical findings with a set of experiments on popular benchmark datasets, which shows that the defense withstands six different practical attacks. Both theoretical and empirical results vote for adversarial training when confronted with delusive poisoning.
Learning Twofold Heterogeneous Multi-Task by Sharing Similar Convolution Kernel Pairs
Jan 29, 2021



Heterogeneous multi-task learning (HMTL) is an important topic in multi-task learning (MTL). Most existing HMTL methods usually solve either scenario where all tasks reside in the same input (feature) space yet unnecessarily the consistent output (label) space or scenario where their input (feature) spaces are heterogeneous while the output (label) space is consistent. However, to the best of our knowledge, there is limited study on twofold heterogeneous MTL (THMTL) scenario where the input and the output spaces are both inconsistent or heterogeneous. In order to handle this complicated scenario, in this paper, we design a simple and effective multi-task adaptive learning (MTAL) network to learn multiple tasks in such THMTL setting. Specifically, we explore and utilize the inherent relationship between tasks for knowledge sharing from similar convolution kernels in individual layers of the MTAL network. Then in order to realize the sharing, we weightedly aggregate any pair of convolutional kernels with their similarity greater than some threshold $\rho$, consequently, our model effectively performs cross-task learning while suppresses the intra-redundancy of the entire network. Finally, we conduct end-to-end training. Our experimental results demonstrate the effectiveness of our method in comparison with the state-of-the-art counterparts.
With False Friends Like These, Who Can Have Self-Knowledge?
Dec 29, 2020

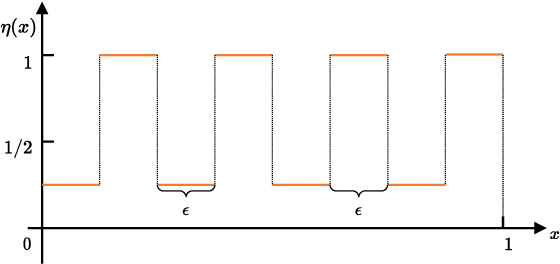

Adversarial examples arise from excessive sensitivity of a model. Commonly studied adversarial examples are malicious inputs, crafted by an adversary from correctly classified examples, to induce misclassification. This paper studies an intriguing, yet far overlooked consequence of the excessive sensitivity, that is, a misclassified example can be easily perturbed to help the model to produce correct output. Such perturbed examples look harmless, but actually can be maliciously utilized by a false friend to make the model self-satisfied. Thus we name them hypocritical examples. With false friends like these, a poorly performed model could behave like a state-of-the-art one. Once a deployer trusts the hypocritical performance and uses the "well-performed" model in real-world applications, potential security concerns appear even in benign environments. In this paper, we formalize the hypocritical risk for the first time and propose a defense method specialized for hypocritical examples by minimizing the tradeoff between natural risk and an upper bound of hypocritical risk. Moreover, our theoretical analysis reveals connections between adversarial risk and hypocritical risk. Extensive experiments verify the theoretical results and the effectiveness of our proposed methods.
Leave Zero Out: Towards a No-Cross-Validation Approach for Model Selection
Dec 28, 2020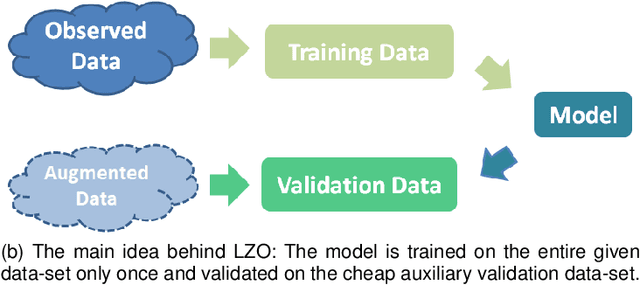
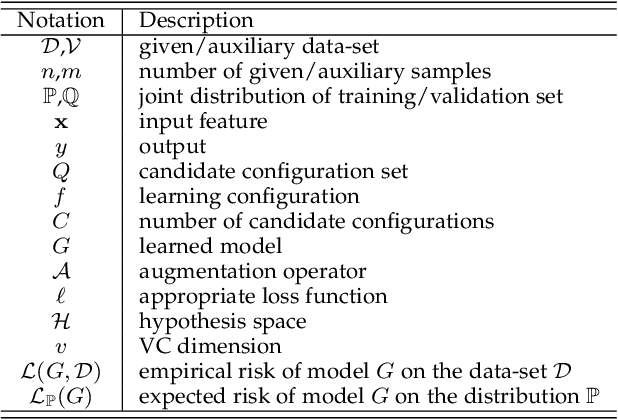
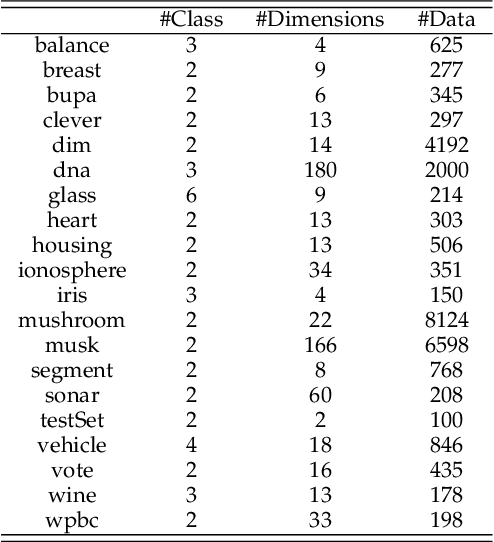
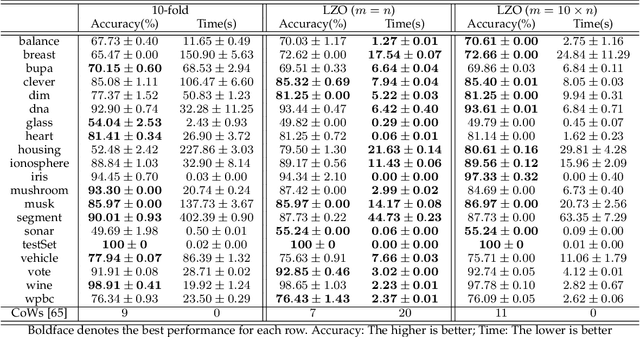
As the main workhorse for model selection, Cross Validation (CV) has achieved an empirical success due to its simplicity and intuitiveness. However, despite its ubiquitous role, CV often falls into the following notorious dilemmas. On the one hand, for small data cases, CV suffers a conservatively biased estimation, since some part of the limited data has to hold out for validation. On the other hand, for large data cases, CV tends to be extremely cumbersome, e.g., intolerant time-consuming, due to the repeated training procedures. Naturally, a straightforward ambition for CV is to validate the models with far less computational cost, while making full use of the entire given data-set for training. Thus, instead of holding out the given data, a cheap and theoretically guaranteed auxiliary/augmented validation is derived strategically in this paper. Such an embarrassingly simple strategy only needs to train models on the entire given data-set once, making the model-selection considerably efficient. In addition, the proposed validation approach is suitable for a wide range of learning settings due to the independence of both augmentation and out-of-sample estimation on learning process. In the end, we demonstrate the accuracy and computational benefits of our proposed method by extensive evaluation on multiple data-sets, models and tasks.
Convex Subspace Clustering by Adaptive Block Diagonal Representation
Sep 22, 2020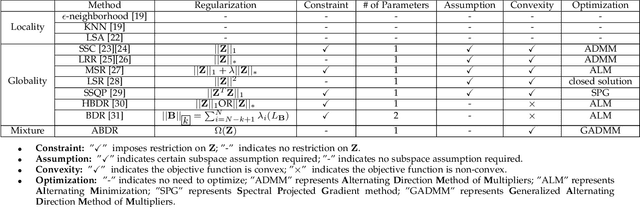
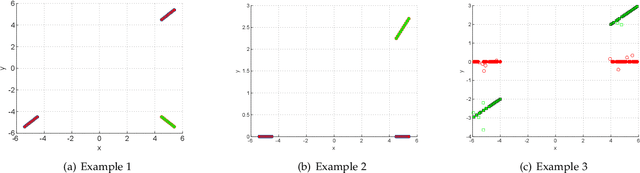

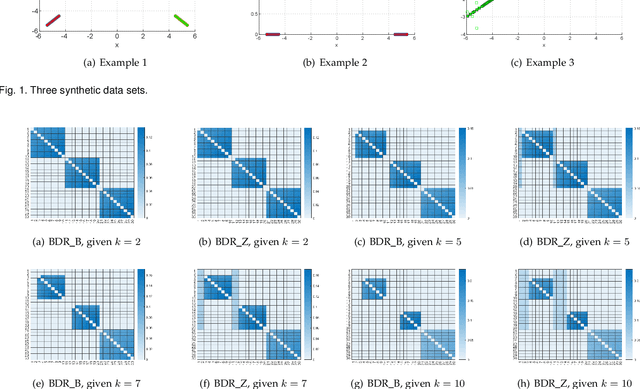
Subspace clustering is a class of extensively studied clustering methods and the spectral-type approaches are its important subclass whose key first step is to learn a coefficient matrix with block diagonal structure. To realize this step, sparse subspace clustering (SSC), low rank representation (LRR) and block diagonal representation (BDR) were successively proposed and have become the state-of-the-arts (SOTAs). Among them, the former two minimize their convex objectives by imposing sparsity and low rankness on the coefficient matrix respectively, but so-desired block diagonality cannot neccesarily be guaranteed practically while the latter designs a block diagonal matrix induced regularizer but sacrifices convexity. For solving this dilemma, inspired by Convex Biclustering, in this paper, we propose a simple yet efficient spectral-type subspace clustering method named Adaptive Block Diagonal Representation (ABDR) which strives to pursue so-desired block diagonality as BDR by coercively fusing the columns/rows of the coefficient matrix via a specially designed convex regularizer, consequently, ABDR naturally enjoys their merits and can adaptively form more desired block diagonality than the SOTAs without needing to prefix the number of blocks as done in BDR. Finally, experimental results on synthetic and real benchmarks demonstrate the superiority of ABDR.