 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectified Euler k-means and Beyond
Aug 06, 2021
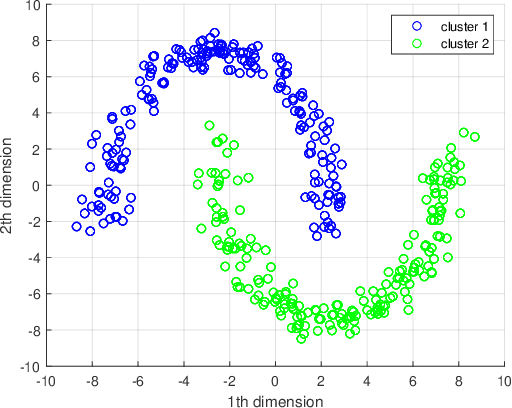
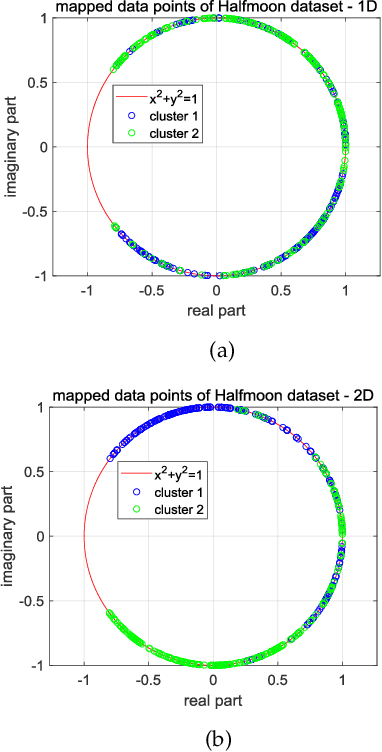
Euler k-means (EulerK) first maps data onto the unit hyper-sphere surface of equi-dimensional space via a complex mapping which induces the robust Euler kernel and next employs the popular $k$-means. Consequently, besides enjoying the virtues of k-means such as simplicity and scalability to large data sets, EulerK is also robust to noises and outliers. Although so, the centroids captured by EulerK deviate from the unit hyper-sphere surface and thus in strict distributional sense, actually are outliers. This weird phenomenon also occurs in some generic kernel clustering methods. Intuitively, using such outlier-like centroids should not be quite reasonable but it is still seldom attended. To eliminate the deviation, we propose two Rectified Euler k-means methods, i.e., REK1 and REK2, which retain the merits of EulerK while acquire real centroids residing on the mapped space to better characterize the data structures. Specifically, REK1 rectifies EulerK by imposing the constraint on the centroids while REK2 views each centroid as the mapped image from a pre-image in the original space and optimizes these pre-images in Euler kernel induced space. Undoubtedly, our proposed REKs can methodologically be extended to solve problems of such a category. Finally, the experiments validate the effectiveness of REK1 and REK2.
Convex Subspace Clustering by Adaptive Block Diagonal Representation
Sep 22, 2020
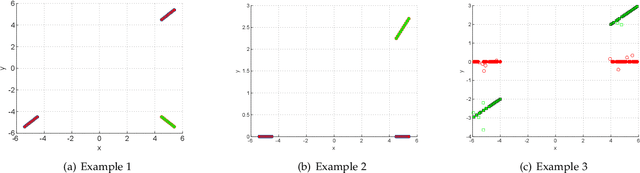

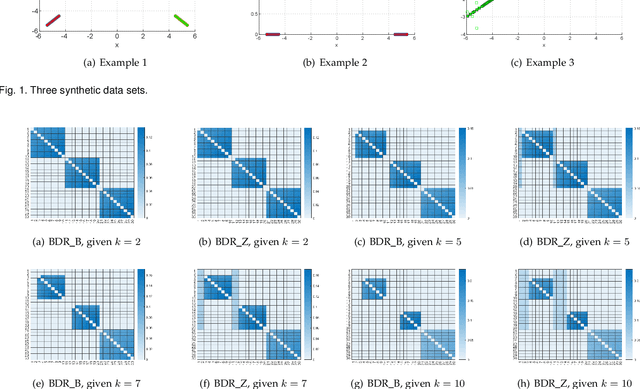
Subspace clustering is a class of extensively studied clustering methods and the spectral-type approaches are its important subclass whose key first step is to learn a coefficient matrix with block diagonal structure. To realize this step, sparse subspace clustering (SSC), low rank representation (LRR) and block diagonal representation (BDR) were successively proposed and have become the state-of-the-arts (SOTAs). Among them, the former two minimize their convex objectives by imposing sparsity and low rankness on the coefficient matrix respectively, but so-desired block diagonality cannot neccesarily be guaranteed practically while the latter designs a block diagonal matrix induced regularizer but sacrifices convexity. For solving this dilemma, inspired by Convex Biclustering, in this paper, we propose a simple yet efficient spectral-type subspace clustering method named Adaptive Block Diagonal Representation (ABDR) which strives to pursue so-desired block diagonality as BDR by coercively fusing the columns/rows of the coefficient matrix via a specially designed convex regularizer, consequently, ABDR naturally enjoys their merits and can adaptively form more desired block diagonality than the SOTAs without needing to prefix the number of blocks as done in BDR. Finally, experimental results on synthetic and real benchmarks demonstrate the superiority of ABDR.
A Centroid Auto-Fused Hierarchical Fuzzy c-Means Clustering
Apr 27, 2020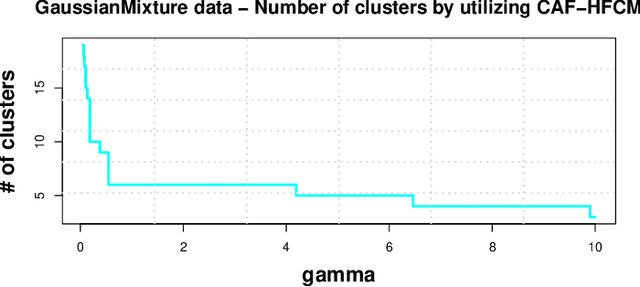
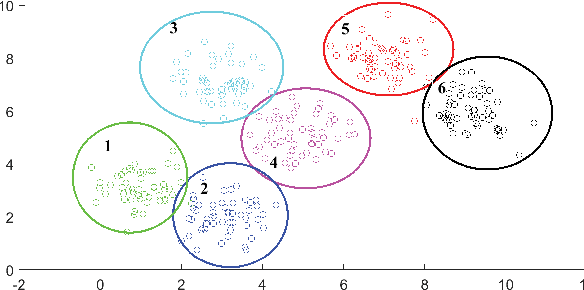
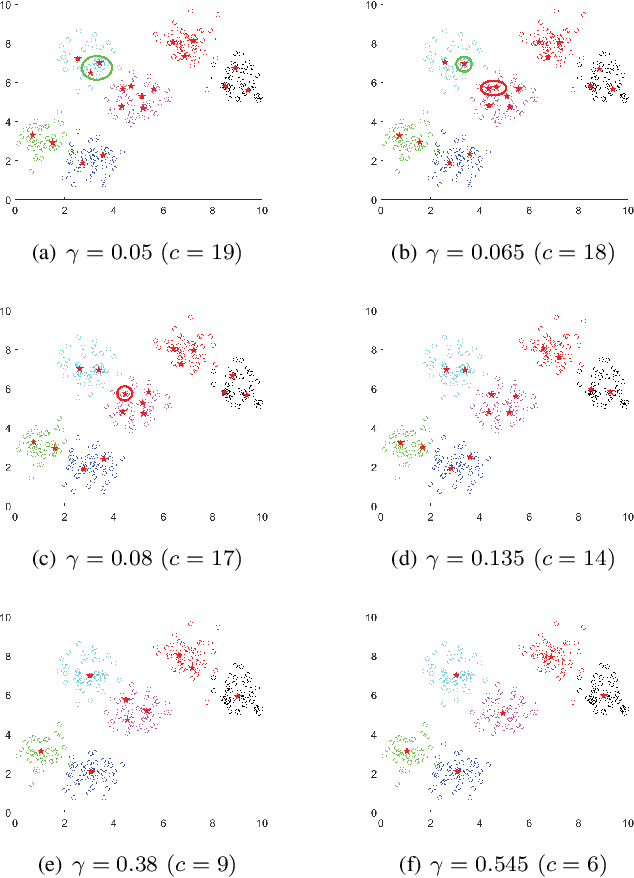
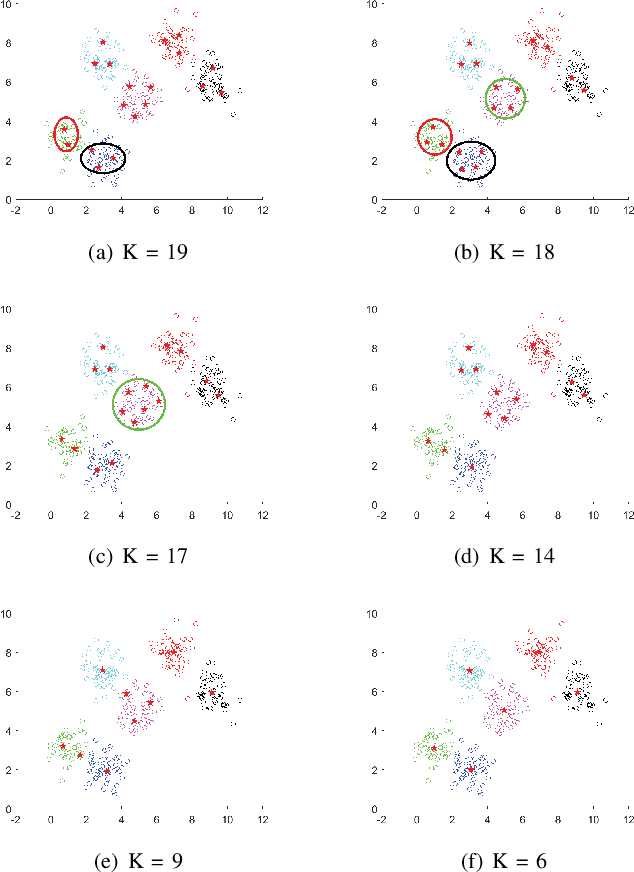
Like k-means and Gaussian Mixture Model (GMM), fuzzy c-means (FCM) with soft partition has also become a popular clustering algorithm and still is extensively studied. However, these algorithms and their variants still suffer from some difficulties such as determination of the optimal number of clusters which is a key factor for clustering quality. A common approach for overcoming this difficulty is to use the trial-and-validation strategy, i.e., traversing every integer from large number like $\sqrt{n}$ to 2 until finding the optimal number corresponding to the peak value of some cluster validity index. But it is scarcely possible to naturally construct an adaptively agglomerative hierarchical cluster structure as using the trial-and-validation strategy. Even possible, existing different validity indices also lead to different number of clusters. To effectively mitigate the problems while motivated by convex clustering, in this paper we present a Centroid Auto-Fused Hierarchical Fuzzy c-means method (CAF-HFCM) whose optimization procedure can automatically agglomerate to form a cluster hierarchy, more importantly, yielding an optimal number of clusters without resorting to any validity index. Although a recently-proposed robust-learning fuzzy c-means (RL-FCM) can also automatically obtain the best number of clusters without the help of any validity index, so-involved 3 hyper-parameters need to adjust expensively, conversely, our CAF-HFCM involves just 1 hyper-parameter which makes the corresponding adjustment is relatively easier and more operational. Further, as an additional benefit from our optimization objective, the CAF-HFCM effectively reduces the sensitivity to the initialization of clustering performance. Moreover, our proposed CAF-HFCM method is able to be straightforwardly extended to various variants of FCM.