 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Out-of-Distribution Error via Optimal Transport
May 25, 2023



Out-of-distribution (OOD) data poses serious challenges in deployed machine learning models, so methods of predicting a model's performance on OOD data without labels are important for machine learning safety. While a number of methods have been proposed by prior work, they often underestimate the actual error, sometimes by a large margin, which greatly impacts their applicability to real tasks. In this work, we identify pseudo-label shift, or the difference between the predicted and true OOD label distributions, as a key indicator to this underestimation. Based on this observation, we introduce a novel method for estimating model performance by leveraging optimal transport theory, Confidence Optimal Transport (COT), and show that it provably provides more robust error estimates in the presence of pseudo-label shift. Additionally, we introduce an empirically-motivated variant of COT, Confidence Optimal Transport with Thresholding (COTT), which applies thresholding to the individual transport costs and further improves the accuracy of COT's error estimates. We evaluate COT and COTT on a variety of standard benchmarks that induce various types of distribution shift -- synthetic, novel subpopulation, and natural -- and show that our approaches significantly outperform existing state-of-the-art methods with an up to 3x lower prediction error.
Sharing Lifelong Reinforcement Learning Knowledge via Modulating Masks
May 18, 2023



Lifelong learning agents aim to learn multiple tasks sequentially over a lifetime. This involves the ability to exploit previous knowledge when learning new tasks and to avoid forgetting. Modulating masks, a specific type of parameter isolation approach, have recently shown promise in both supervised and reinforcement learning. While lifelong learning algorithms have been investigated mainly within a single-agent approach, a question remains on how multiple agents can share lifelong learning knowledge with each other. We show that the parameter isolation mechanism used by modulating masks is particularly suitable for exchanging knowledge among agents in a distributed and decentralized system of lifelong learners. The key idea is that the isolation of specific task knowledge to specific masks allows agents to transfer only specific knowledge on-demand, resulting in robust and effective distributed lifelong learning. We assume fully distributed and asynchronous scenarios with dynamic agent numbers and connectivity. An on-demand communication protocol ensures agents query their peers for specific masks to be transferred and integrated into their policies when facing each task. Experiments indicate that on-demand mask communication is an effective way to implement distributed lifelong reinforcement learning and provides a lifelong learning benefit with respect to distributed RL baselines such as DD-PPO, IMPALA, and PPO+EWC. The system is particularly robust to connection drops and demonstrates rapid learning due to knowledge exchange.
Predicting Out-of-Distribution Error with Confidence Optimal Transport
Feb 10, 2023



Out-of-distribution (OOD) data poses serious challenges in deployed machine learning models as even subtle changes could incur significant performance drops. Being able to estimate a model's performance on test data is important in practice as it indicates when to trust to model's decisions. We present a simple yet effective method to predict a model's performance on an unknown distribution without any addition annotation. Our approach is rooted in the Optimal Transport theory, viewing test samples' output softmax scores from deep neural networks as empirical samples from an unknown distribution. We show that our method, Confidence Optimal Transport (COT), provides robust estimates of a model's performance on a target domain. Despite its simplicity, our method achieves state-of-the-art results on three benchmark datasets and outperforms existing methods by a large margin.
Linear Optimal Partial Transport Embedding
Feb 08, 2023Optimal transport (OT) has gained popularity due to its various applications in fields such as machine learning, statistics, and signal processing. However, the balanced mass requirement limits its performance in practical problems. To address these limitations, variants of the OT problem, including unbalanced OT, Optimal partial transport (OPT), and Hellinger Kantorovich (HK), have been proposed. In this paper, we propose the Linear optimal partial transport (LOPT) embedding, which extends the (local) linearization technique on OT and HK to the OPT problem. The proposed embedding allows for faster computation of OPT distance between pairs of positive measures. Besides our theoretical contributions, we demonstrate the LOPT embedding technique in point-cloud interpolation and PCA analysis.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023



Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Sliced Optimal Partial Transport
Dec 21, 2022Optimal transport (OT) has become exceedingly popular in machine learning, data science, and computer vision. The core assumption in the OT problem is the equal total amount of mass in source and target measures, which limits its application. Optimal Partial Transport (OPT) is a recently proposed solution to this limitation. Similar to the OT problem, the computation of OPT relies on solving a linear programming problem (often in high dimensions), which can become computationally prohibitive. In this paper, we propose an efficient algorithm for calculating the OPT problem between two non-negative measures in one dimension. Next, following the idea of sliced OT distances, we utilize slicing to define the sliced OPT distance. Finally, we demonstrate the computational and accuracy benefits of the sliced OPT-based method in various numerical experiments. In particular, we show an application of our proposed Sliced-OPT in noisy point cloud registration.
Lifelong Reinforcement Learning with Modulating Masks
Dec 21, 2022Lifelong learning aims to create AI systems that continuously and incrementally learn during a lifetime, similar to biological learning. Attempts so far have met problems, including catastrophic forgetting, interference among tasks, and the inability to exploit previous knowledge. While considerable research has focused on learning multiple input distributions, typically in classification, lifelong reinforcement learning (LRL) must also deal with variations in the state and transition distributions, and in the reward functions. Modulating masks, recently developed for classification, are particularly suitable to deal with such a large spectrum of task variations. In this paper, we adapted modulating masks to work with deep LRL, specifically PPO and IMPALA agents. The comparison with LRL baselines in both discrete and continuous RL tasks shows competitive performance. We further investigated the use of a linear combination of previously learned masks to exploit previous knowledge when learning new tasks: not only is learning faster, the algorithm solves tasks that we could not otherwise solve from scratch due to extremely sparse rewards. The results suggest that RL with modulating masks is a promising approach to lifelong learning, to the composition of knowledge to learn increasingly complex tasks, and to knowledge reuse for efficient and faster learning.
Is Multi-Task Learning an Upper Bound for Continual Learning?
Oct 26, 2022



Continual and multi-task learning are common machine learning approaches to learning from multiple tasks. The existing works in the literature often assume multi-task learning as a sensible performance upper bound for various continual learning algorithms. While this assumption is empirically verified for different continual learning benchmarks, it is not rigorously justified. Moreover, it is imaginable that when learning from multiple tasks, a small subset of these tasks could behave as adversarial tasks reducing the overall learning performance in a multi-task setting. In contrast, continual learning approaches can avoid the performance drop caused by such adversarial tasks to preserve their performance on the rest of the tasks, leading to better performance than a multi-task learner. This paper proposes a novel continual self-supervised learning setting, where each task corresponds to learning an invariant representation for a specific class of data augmentations. In this setting, we show that continual learning often beats multi-task learning on various benchmark datasets, including MNIST, CIFAR-10, and CIFAR-100.
Wasserstein Task Embedding for Measuring Task Similarities
Aug 24, 2022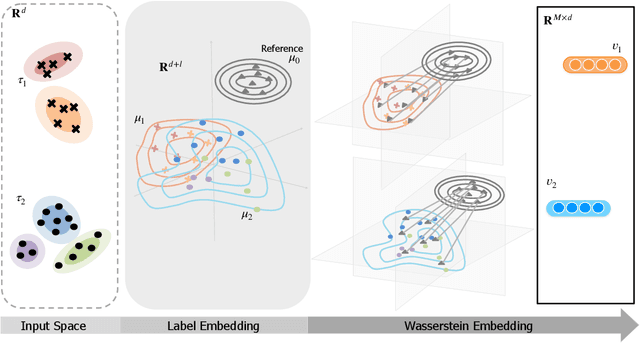
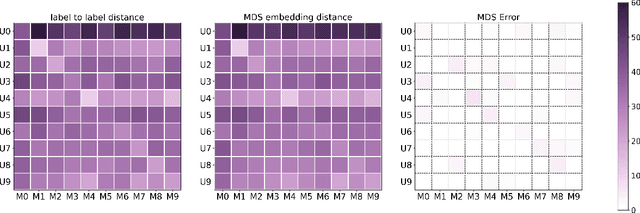
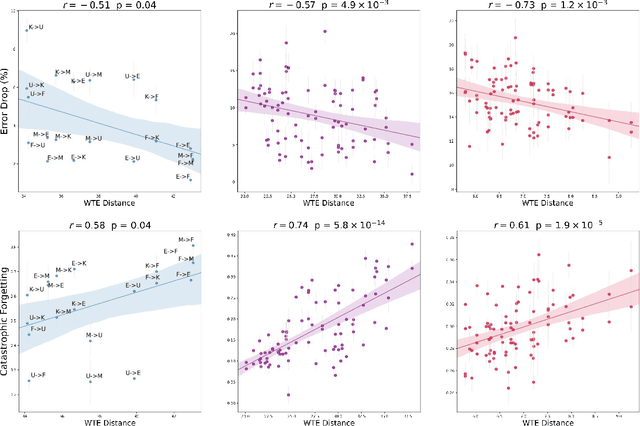
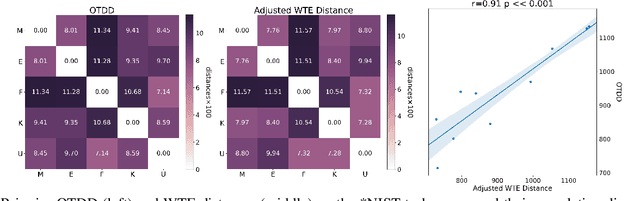
Measuring similarities between different tasks is critical in a broad spectrum of machine learning problems, including transfer, multi-task, continual, and meta-learning. Most current approaches to measuring task similarities are architecture-dependent: 1) relying on pre-trained models, or 2) training networks on tasks and using forward transfer as a proxy for task similarity. In this paper, we leverage the optimal transport theory and define a novel task embedding for supervised classification that is model-agnostic, training-free, and capable of handling (partially) disjoint label sets. In short, given a dataset with ground-truth labels, we perform a label embedding through multi-dimensional scaling and concatenate dataset samples with their corresponding label embeddings. Then, we define the distance between two datasets as the 2-Wasserstein distance between their updated samples. Lastly, we leverage the 2-Wasserstein embedding framework to embed tasks into a vector space in which the Euclidean distance between the embedded points approximates the proposed 2-Wasserstein distance between tasks. We show that the proposed embedding leads to a significantly faster comparison of tasks compared to related approaches like the Optimal Transport Dataset Distance (OTDD). Furthermore, we demonstrate the effectiveness of our proposed embedding through various numerical experiments and show statistically significant correlations between our proposed distance and the forward and backward transfer between tasks.
PRANC: Pseudo RAndom Networks for Compacting deep models
Jun 16, 2022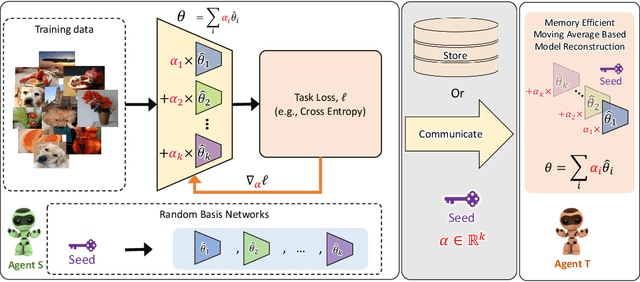
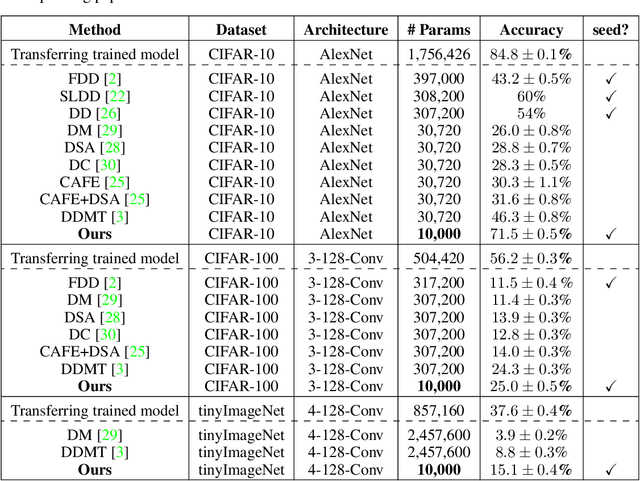
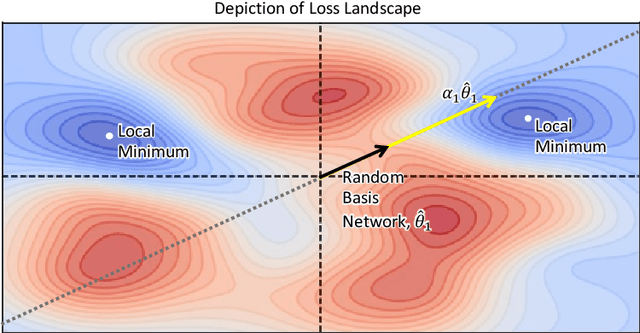
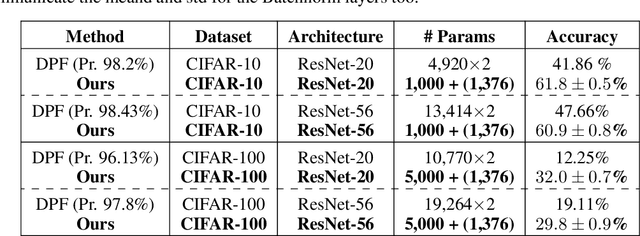
Communication becomes a bottleneck in various distributed Machine Learning settings. Here, we propose a novel training framework that leads to highly efficient communication of models between agents. In short, we train our network to be a linear combination of many pseudo-randomly generated frozen models. For communication, the source agent transmits only the `seed' scalar used to generate the pseudo-random `basis' networks along with the learned linear mixture coefficients. Our method, denoted as PRANC, learns almost $100\times$ fewer parameters than a deep model and still performs well on several datasets and architectures. PRANC enables 1) efficient communication of models between agents, 2) efficient model storage, and 3) accelerated inference by generating layer-wise weights on the fly. We test PRANC on CIFAR-10, CIFAR-100, tinyImageNet, and ImageNet-100 with various architectures like AlexNet, LeNet, ResNet18, ResNet20, and ResNet56 and demonstrate a massive reduction in the number of parameters while providing satisfactory performance on these benchmark datasets. The code is available \href{https://github.com/UCDvision/PRANC}{https://github.com/UCDvision/PRANC}