 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-optimal estimates for the $\ell^p$-Lipschitz constants of deep random ReLU neural networks
Jun 24, 2025

This paper studies the $\ell^p$-Lipschitz constants of ReLU neural networks $\Phi: \mathbb{R}^d \to \mathbb{R}$ with random parameters for $p \in [1,\infty]$. The distribution of the weights follows a variant of the He initialization and the biases are drawn from symmetric distributions. We derive high probability upper and lower bounds for wide networks that differ at most by a factor that is logarithmic in the network's width and linear in its depth. In the special case of shallow networks, we obtain matching bounds. Remarkably, the behavior of the $\ell^p$-Lipschitz constant varies significantly between the regimes $ p \in [1,2) $ and $ p \in [2,\infty] $. For $p \in [2,\infty]$, the $\ell^p$-Lipschitz constant behaves similarly to $\Vert g\Vert_{p'}$, where $g \in \mathbb{R}^d$ is a $d$-dimensional standard Gaussian vector and $1/p + 1/p' = 1$. In contrast, for $p \in [1,2)$, the $\ell^p$-Lipschitz constant aligns more closely to $\Vert g \Vert_{2}$.
Memorization with neural nets: going beyond the worst case
Oct 12, 2023In practice, deep neural networks are often able to easily interpolate their training data. To understand this phenomenon, many works have aimed to quantify the memorization capacity of a neural network architecture: the largest number of points such that the architecture can interpolate any placement of these points with any assignment of labels. For real-world data, however, one intuitively expects the presence of a benign structure so that interpolation already occurs at a smaller network size than suggested by memorization capacity. In this paper, we investigate interpolation by adopting an instance-specific viewpoint. We introduce a simple randomized algorithm that, given a fixed finite dataset with two classes, with high probability constructs an interpolating three-layer neural network in polynomial time. The required number of parameters is linked to geometric properties of the two classes and their mutual arrangement. As a result, we obtain guarantees that are independent of the number of samples and hence move beyond worst-case memorization capacity bounds. We illustrate the effectiveness of the algorithm in non-pathological situations with extensive numerical experiments and link the insights back to the theoretical results.
Plug-in Channel Estimation with Dithered Quantized Signals in Spatially Non-Stationary Massive MIMO Systems
Jan 11, 2023



As the array dimension of massive MIMO systems increases to unprecedented levels, two problems occur. First, the spatial stationarity assumption along the antenna elements is no longer valid. Second, the large array size results in an unacceptably high power consumption if high-resolution analog-to-digital converters are used. To address these two challenges, we consider a Bussgang linear minimum mean square error (BLMMSE)-based channel estimator for large scale massive MIMO systems with one-bit quantizers and a spatially non-stationary channel. Whereas other works usually assume that the channel covariance is known at the base station, we consider a plug-in BLMMSE estimator that uses an estimate of the channel covariance and rigorously analyze the distortion produced by using an estimated, rather than the true, covariance. To cope with the spatial non-stationarity, we introduce dithering into the quantized signals and provide a theoretical error analysis. In addition, we propose an angular domain fitting procedure which is based on solving an instance of non-negative least squares. For the multi-user data transmission phase, we further propose a BLMMSE-based receiver to handle one-bit quantized data signals. Our numerical results show that the performance of the proposed BLMMSE channel estimator is very close to the oracle-aided scheme with ideal knowledge of the channel covariance matrix. The BLMMSE receiver outperforms the conventional maximum-ratio-combining and zero-forcing receivers in terms of the resulting ergodic sum rate.
The Separation Capacity of Random Neural Networks
Jul 31, 2021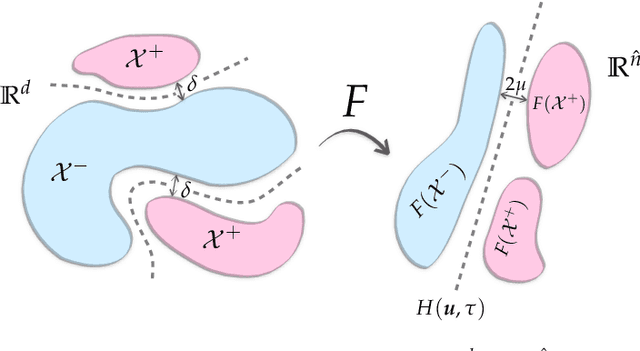
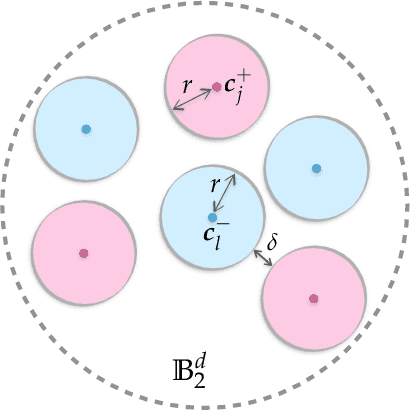
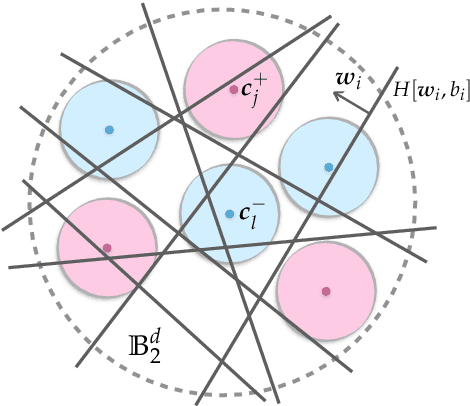
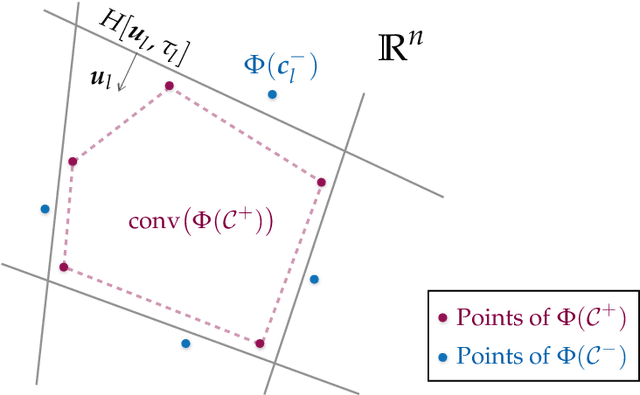
Neural networks with random weights appear in a variety of machine learning applications, most prominently as the initialization of many deep learning algorithms and as a computationally cheap alternative to fully learned neural networks. In the present article we enhance the theoretical understanding of random neural nets by addressing the following data separation problem: under what conditions can a random neural network make two classes $\mathcal{X}^-, \mathcal{X}^+ \subset \mathbb{R}^d$ (with positive distance) linearly separable? We show that a sufficiently large two-layer ReLU-network with standard Gaussian weights and uniformly distributed biases can solve this problem with high probability. Crucially, the number of required neurons is explicitly linked to geometric properties of the underlying sets $\mathcal{X}^-, \mathcal{X}^+$ and their mutual arrangement. This instance-specific viewpoint allows us to overcome the usual curse of dimensionality (exponential width of the layers) in non-pathological situations where the data carries low-complexity structure. We quantify the relevant structure of the data in terms of a novel notion of mutual complexity (based on a localized version of Gaussian mean width), which leads to sound and informative separation guarantees. We connect our result with related lines of work on approximation, memorization, and generalization.
Statistical post-processing of wind speed forecasts using convolutional neural networks
Jul 08, 2020
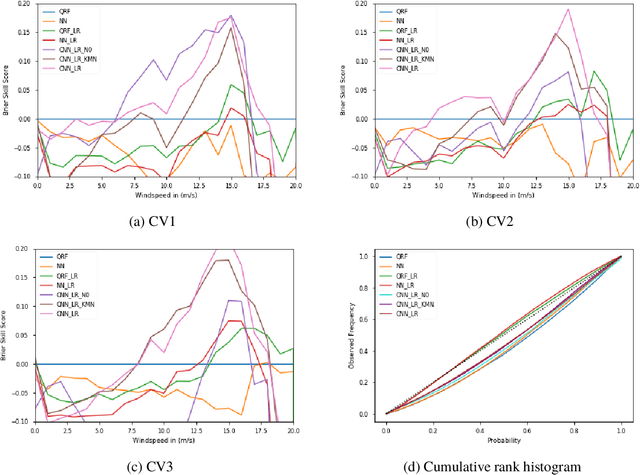

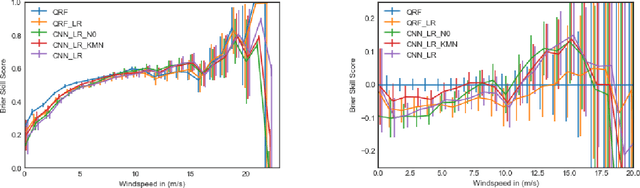
Current statistical post-processing methods for probabilistic weather forecasting are not capable of using full spatial patterns from the numerical weather prediction (NWP) model. In this paper we incorporate spatial wind speed information by using convolutional neural networks (CNNs) and obtain probabilistic wind speed forecasts in the Netherlands for 48 hours ahead, based on KNMI's Harmonie-Arome NWP model. The CNNs are shown to have higher Brier skill scores for medium to higher wind speeds, as well as a better continuous ranked probability score (CRPS), than fully connected neural networks and quantile regression forests.
Toward a unified theory of sparse dimensionality reduction in Euclidean space
Aug 25, 2015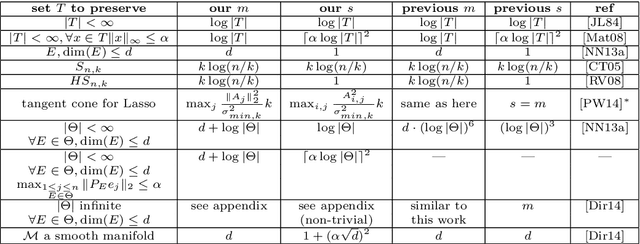
Let $\Phi\in\mathbb{R}^{m\times n}$ be a sparse Johnson-Lindenstrauss transform [KN14] with $s$ non-zeroes per column. For a subset $T$ of the unit sphere, $\varepsilon\in(0,1/2)$ given, we study settings for $m,s$ required to ensure $$ \mathop{\mathbb{E}}_\Phi \sup_{x\in T} \left|\|\Phi x\|_2^2 - 1 \right| < \varepsilon , $$ i.e. so that $\Phi$ preserves the norm of every $x\in T$ simultaneously and multiplicatively up to $1+\varepsilon$. We introduce a new complexity parameter, which depends on the geometry of $T$, and show that it suffices to choose $s$ and $m$ such that this parameter is small. Our result is a sparse analog of Gordon's theorem, which was concerned with a dense $\Phi$ having i.i.d. Gaussian entries. We qualitatively unify several results related to the Johnson-Lindenstrauss lemma, subspace embeddings, and Fourier-based restricted isometries. Our work also implies new results in using the sparse Johnson-Lindenstrauss transform in numerical linear algebra, classical and model-based compressed sensing, manifold learning, and constrained least squares problems such as the Lasso.
Dimensionality reduction with subgaussian matrices: a unified theory
Feb 17, 2014We present a theory for Euclidean dimensionality reduction with subgaussian matrices which unifies several restricted isometry property and Johnson-Lindenstrauss type results obtained earlier for specific data sets. In particular, we recover and, in several cases, improve results for sets of sparse and structured sparse vectors, low-rank matrices and tensors, and smooth manifolds. In addition, we establish a new Johnson-Lindenstrauss embedding for data sets taking the form of an infinite union of subspaces of a Hilbert space.