 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation under Missingness Shift
Nov 03, 2022Rates of missing data often depend on record-keeping policies and thus may change across times and locations, even when the underlying features are comparatively stable. In this paper, we introduce the problem of Domain Adaptation under Missingness Shift (DAMS). Here, (labeled) source data and (unlabeled) target data would be exchangeable but for different missing data mechanisms. We show that when missing data indicators are available, DAMS can reduce to covariate shift. Focusing on the setting where missing data indicators are absent, we establish the following theoretical results for underreporting completely at random: (i) covariate shift is violated (adaptation is required); (ii) the optimal source predictor can perform worse on the target domain than a constant one; (iii) the optimal target predictor can be identified, even when the missingness rates themselves are not; and (iv) for linear models, a simple analytic adjustment yields consistent estimates of the optimal target parameters. In experiments on synthetic and semi-synthetic data, we demonstrate the promise of our methods when assumptions hold. Finally, we discuss a rich family of future extensions.
Domain Adaptation under Open Set Label Shift
Jul 26, 2022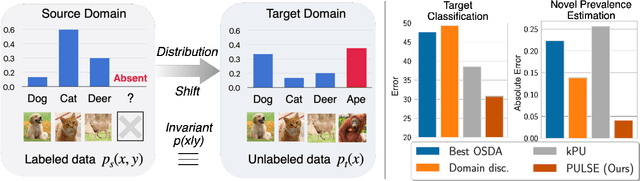
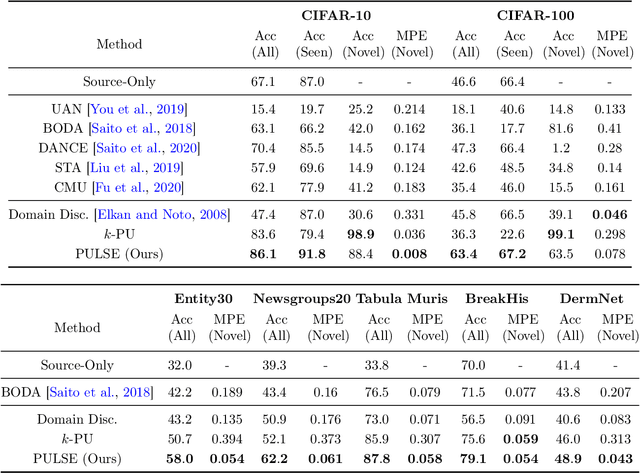
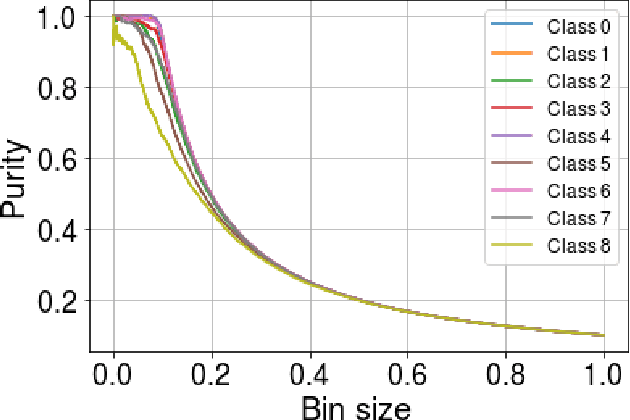
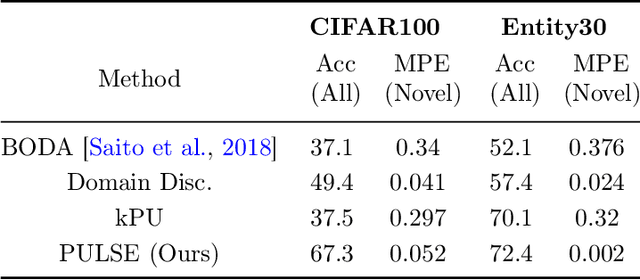
We introduce the problem of domain adaptation under Open Set Label Shift (OSLS) where the label distribution can change arbitrarily and a new class may arrive during deployment, but the class-conditional distributions p(x|y) are domain-invariant. OSLS subsumes domain adaptation under label shift and Positive-Unlabeled (PU) learning. The learner's goals here are two-fold: (a) estimate the target label distribution, including the novel class; and (b) learn a target classifier. First, we establish necessary and sufficient conditions for identifying these quantities. Second, motivated by advances in label shift and PU learning, we propose practical methods for both tasks that leverage black-box predictors. Unlike typical Open Set Domain Adaptation (OSDA) problems, which tend to be ill-posed and amenable only to heuristics, OSLS offers a well-posed problem amenable to more principled machinery. Experiments across numerous semi-synthetic benchmarks on vision, language, and medical datasets demonstrate that our methods consistently outperform OSDA baselines, achieving 10--25% improvements in target domain accuracy. Finally, we analyze the proposed methods, establishing finite-sample convergence to the true label marginal and convergence to optimal classifier for linear models in a Gaussian setup. Code is available at https://github.com/acmi-lab/Open-Set-Label-Shift.
Leveraging Unlabeled Data to Predict Out-of-Distribution Performance
Feb 09, 2022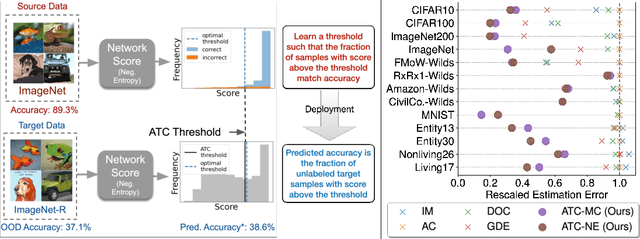
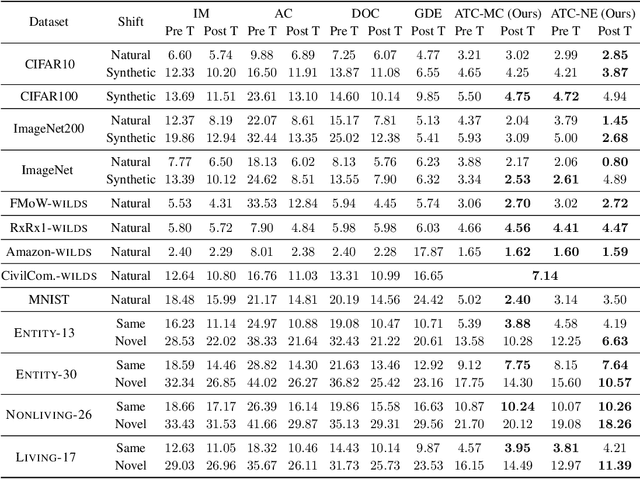
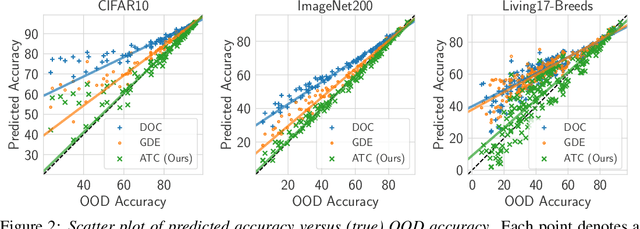
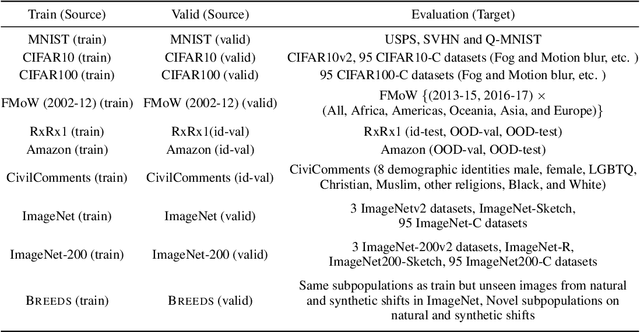
Real-world machine learning deployments are characterized by mismatches between the source (training) and target (test) distributions that may cause performance drops. In this work, we investigate methods for predicting the target domain accuracy using only labeled source data and unlabeled target data. We propose Average Thresholded Confidence (ATC), a practical method that learns a threshold on the model's confidence, predicting accuracy as the fraction of unlabeled examples for which model confidence exceeds that threshold. ATC outperforms previous methods across several model architectures, types of distribution shifts (e.g., due to synthetic corruptions, dataset reproduction, or novel subpopulations), and datasets (Wilds, ImageNet, Breeds, CIFAR, and MNIST). In our experiments, ATC estimates target performance $2$-$4\times$ more accurately than prior methods. We also explore the theoretical foundations of the problem, proving that, in general, identifying the accuracy is just as hard as identifying the optimal predictor and thus, the efficacy of any method rests upon (perhaps unstated) assumptions on the nature of the shift. Finally, analyzing our method on some toy distributions, we provide insights concerning when it works.
Minimax Optimal Regression over Sobolev Spaces via Laplacian Eigenmaps on Neighborhood Graphs
Nov 14, 2021
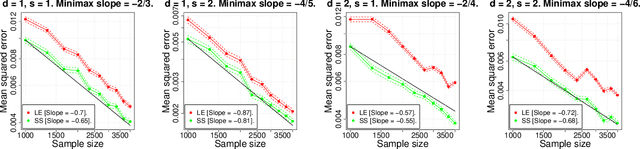
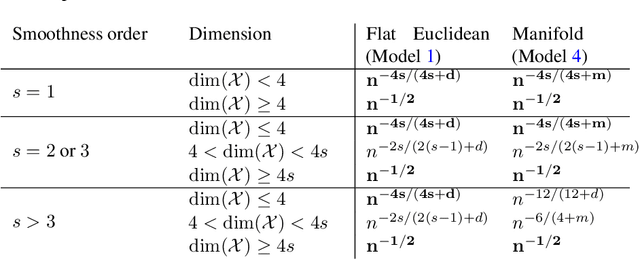
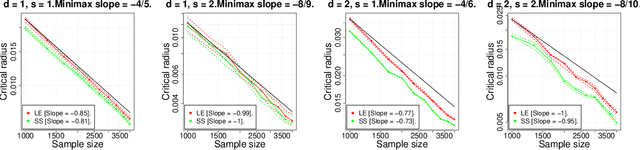
In this paper we study the statistical properties of Principal Components Regression with Laplacian Eigenmaps (PCR-LE), a method for nonparametric regression based on Laplacian Eigenmaps (LE). PCR-LE works by projecting a vector of observed responses ${\bf Y} = (Y_1,\ldots,Y_n)$ onto a subspace spanned by certain eigenvectors of a neighborhood graph Laplacian. We show that PCR-LE achieves minimax rates of convergence for random design regression over Sobolev spaces. Under sufficient smoothness conditions on the design density $p$, PCR-LE achieves the optimal rates for both estimation (where the optimal rate in squared $L^2$ norm is known to be $n^{-2s/(2s + d)}$) and goodness-of-fit testing ($n^{-4s/(4s + d)}$). We also show that PCR-LE is \emph{manifold adaptive}: that is, we consider the situation where the design is supported on a manifold of small intrinsic dimension $m$, and give upper bounds establishing that PCR-LE achieves the faster minimax estimation ($n^{-2s/(2s + m)}$) and testing ($n^{-4s/(4s + m)}$) rates of convergence. Interestingly, these rates are almost always much faster than the known rates of convergence of graph Laplacian eigenvectors to their population-level limits; in other words, for this problem regression with estimated features appears to be much easier, statistically speaking, than estimating the features itself. We support these theoretical results with empirical evidence.
Mixture Proportion Estimation and PU Learning: A Modern Approach
Nov 01, 2021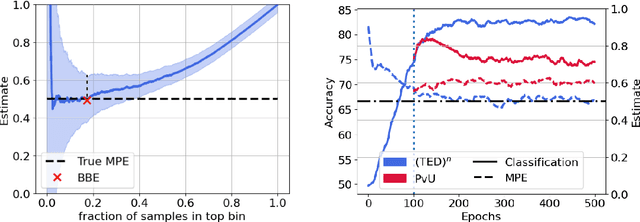
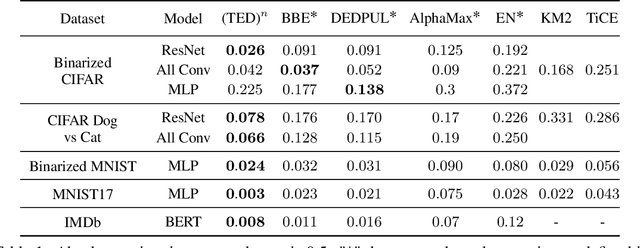
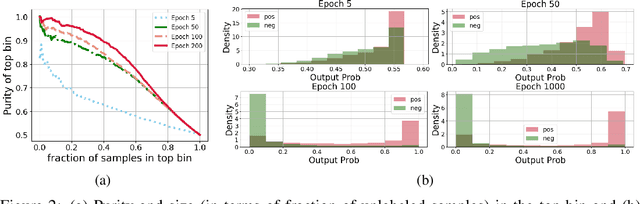
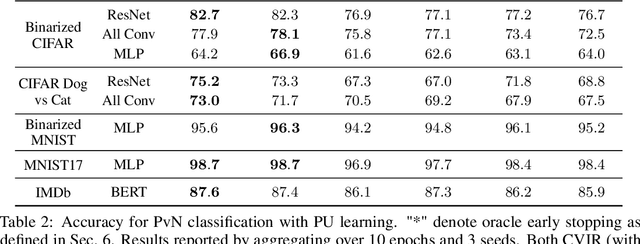
Given only positive examples and unlabeled examples (from both positive and negative classes), we might hope nevertheless to estimate an accurate positive-versus-negative classifier. Formally, this task is broken down into two subtasks: (i) Mixture Proportion Estimation (MPE) -- determining the fraction of positive examples in the unlabeled data; and (ii) PU-learning -- given such an estimate, learning the desired positive-versus-negative classifier. Unfortunately, classical methods for both problems break down in high-dimensional settings. Meanwhile, recently proposed heuristics lack theoretical coherence and depend precariously on hyperparameter tuning. In this paper, we propose two simple techniques: Best Bin Estimation (BBE) (for MPE); and Conditional Value Ignoring Risk (CVIR), a simple objective for PU-learning. Both methods dominate previous approaches empirically, and for BBE, we establish formal guarantees that hold whenever we can train a model to cleanly separate out a small subset of positive examples. Our final algorithm (TED)$^n$, alternates between the two procedures, significantly improving both our mixture proportion estimator and classifier
Heavy-tailed Streaming Statistical Estimation
Aug 25, 2021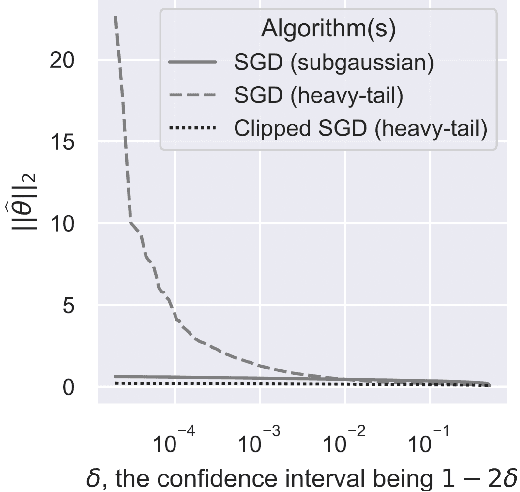
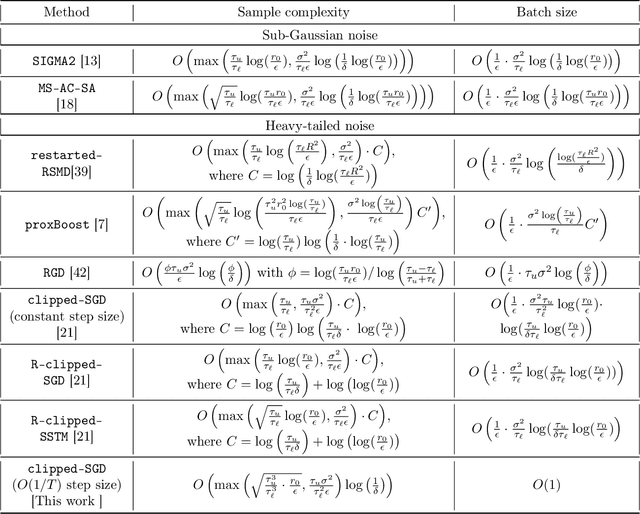
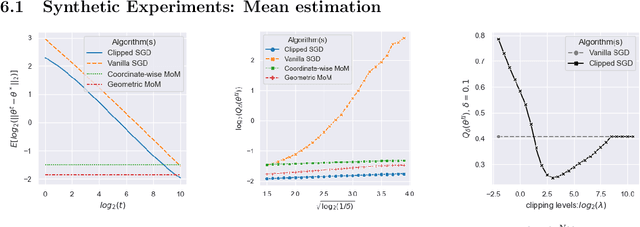
We consider the task of heavy-tailed statistical estimation given streaming $p$-dimensional samples. This could also be viewed as stochastic optimization under heavy-tailed distributions, with an additional $O(p)$ space complexity constraint. We design a clipped stochastic gradient descent algorithm and provide an improved analysis, under a more nuanced condition on the noise of the stochastic gradients, which we show is critical when analyzing stochastic optimization problems arising from general statistical estimation problems. Our results guarantee convergence not just in expectation but with exponential concentration, and moreover does so using $O(1)$ batch size. We provide consequences of our results for mean estimation and linear regression. Finally, we provide empirical corroboration of our results and algorithms via synthetic experiments for mean estimation and linear regression.
Plugin Estimation of Smooth Optimal Transport Maps
Jul 26, 2021We analyze a number of natural estimators for the optimal transport map between two distributions and show that they are minimax optimal. We adopt the plugin approach: our estimators are simply optimal couplings between measures derived from our observations, appropriately extended so that they define functions on $\mathbb{R}^d$. When the underlying map is assumed to be Lipschitz, we show that computing the optimal coupling between the empirical measures, and extending it using linear smoothers, already gives a minimax optimal estimator. When the underlying map enjoys higher regularity, we show that the optimal coupling between appropriate nonparametric density estimates yields faster rates. Our work also provides new bounds on the risk of corresponding plugin estimators for the quadratic Wasserstein distance, and we show how this problem relates to that of estimating optimal transport maps using stability arguments for smooth and strongly convex Brenier potentials. As an application of our results, we derive a central limit theorem for a density plugin estimator of the squared Wasserstein distance, which is centered at its population counterpart when the underlying distributions have sufficiently smooth densities. In contrast to known central limit theorems for empirical estimators, this result easily lends itself to statistical inference for Wasserstein distances.
Minimax Optimal Regression over Sobolev Spaces via Laplacian Regularization on Neighborhood Graphs
Jun 03, 2021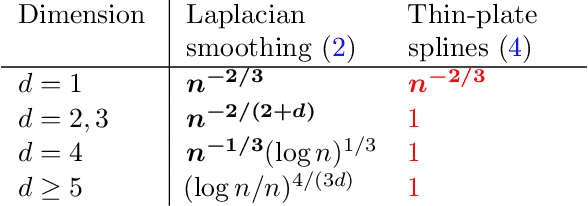
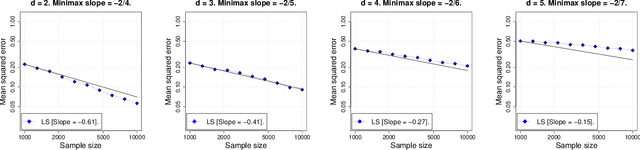

In this paper we study the statistical properties of Laplacian smoothing, a graph-based approach to nonparametric regression. Under standard regularity conditions, we establish upper bounds on the error of the Laplacian smoothing estimator $\widehat{f}$, and a goodness-of-fit test also based on $\widehat{f}$. These upper bounds match the minimax optimal estimation and testing rates of convergence over the first-order Sobolev class $H^1(\mathcal{X})$, for $\mathcal{X}\subseteq \mathbb{R}^d$ and $1 \leq d < 4$; in the estimation problem, for $d = 4$, they are optimal modulo a $\log n$ factor. Additionally, we prove that Laplacian smoothing is manifold-adaptive: if $\mathcal{X} \subseteq \mathbb{R}^d$ is an $m$-dimensional manifold with $m < d$, then the error rate of Laplacian smoothing (in either estimation or testing) depends only on $m$, in the same way it would if $\mathcal{X}$ were a full-dimensional set in $\mathbb{R}^d$.
RATT: Leveraging Unlabeled Data to Guarantee Generalization
May 01, 2021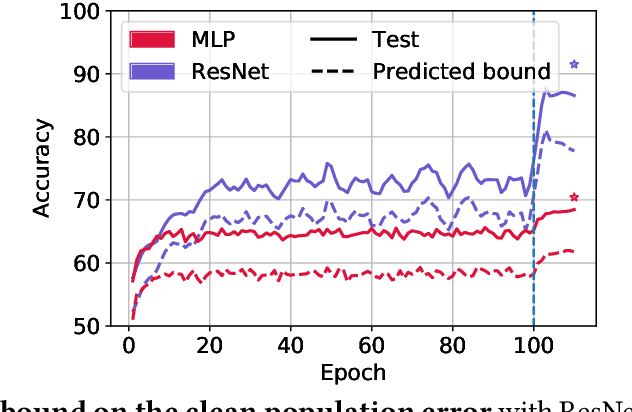
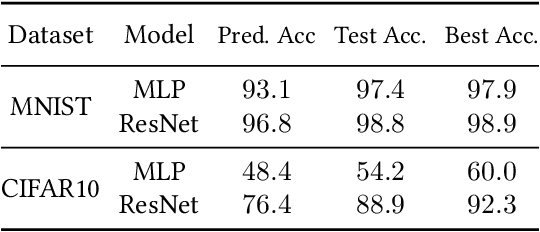
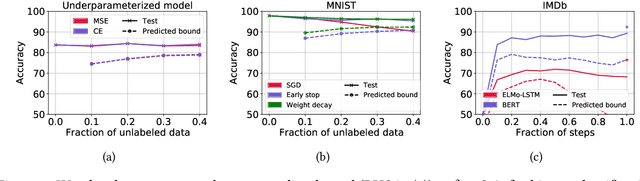
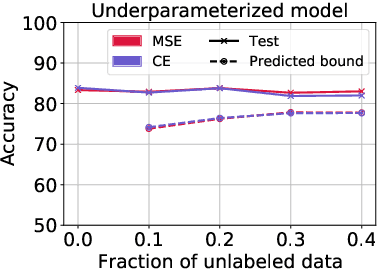
To assess generalization, machine learning scientists typically either (i) bound the generalization gap and then (after training) plug in the empirical risk to obtain a bound on the true risk; or (ii) validate empirically on holdout data. However, (i) typically yields vacuous guarantees for overparameterized models. Furthermore, (ii) shrinks the training set and its guarantee erodes with each re-use of the holdout set. In this paper, we introduce a method that leverages unlabeled data to produce generalization bounds. After augmenting our (labeled) training set with randomly labeled fresh examples, we train in the standard fashion. Whenever classifiers achieve low error on clean data and high error on noisy data, our bound provides a tight upper bound on the true risk. We prove that our bound is valid for 0-1 empirical risk minimization and with linear classifiers trained by gradient descent. Our approach is especially useful in conjunction with deep learning due to the early learning phenomenon whereby networks fit true labels before noisy labels but requires one intuitive assumption. Empirically, on canonical computer vision and NLP tasks, our bound provides non-vacuous generalization guarantees that track actual performance closely. This work provides practitioners with an option for certifying the generalization of deep nets even when unseen labeled data is unavailable and provides theoretical insights into the relationship between random label noise and generalization.
On Proximal Policy Optimization's Heavy-tailed Gradients
Feb 20, 2021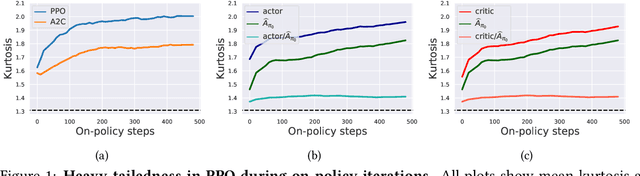
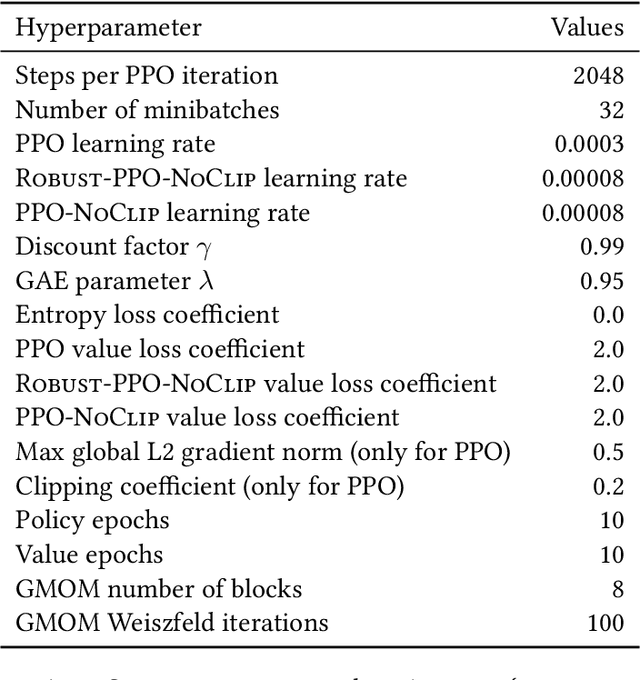
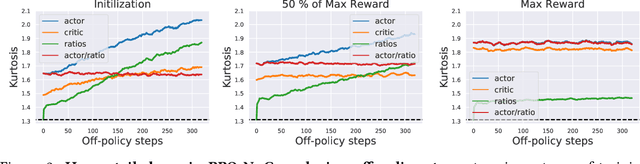
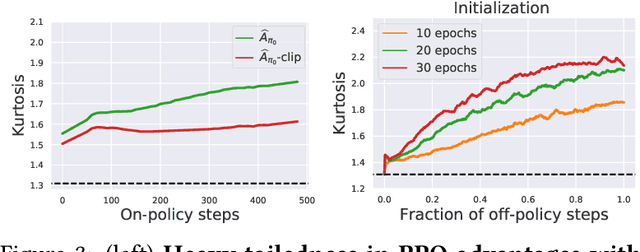
Modern policy gradient algorithms, notably Proximal Policy Optimization (PPO), rely on an arsenal of heuristics, including loss clipping and gradient clipping, to ensure successful learning. These heuristics are reminiscent of techniques from robust statistics, commonly used for estimation in outlier-rich ("heavy-tailed") regimes. In this paper, we present a detailed empirical study to characterize the heavy-tailed nature of the gradients of the PPO surrogate reward function. We demonstrate that the gradients, especially for the actor network, exhibit pronounced heavy-tailedness and that it increases as the agent's policy diverges from the behavioral policy (i.e., as the agent goes further off policy). Further examination implicates the likelihood ratios and advantages in the surrogate reward as the main sources of the observed heavy-tailedness. We then highlight issues arising due to the heavy-tailed nature of the gradients. In this light, we study the effects of the standard PPO clipping heuristics, demonstrating that these tricks primarily serve to offset heavy-tailedness in gradients. Thus motivated, we propose incorporating GMOM, a high-dimensional robust estimator, into PPO as a substitute for three clipping tricks. Despite requiring less hyperparameter tuning, our method matches the performance of PPO (with all heuristics enabled) on a battery of MuJoCo continuous control tasks.