 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing False Positives in Static Bug Detection with LLMs: An Empirical Study in Industry
Jan 26, 2026Static analysis tools (SATs) are widely adopted in both academia and industry for improving software quality, yet their practical use is often hindered by high false positive rates, especially in large-scale enterprise systems. These false alarms demand substantial manual inspection, creating severe inefficiencies in industrial code review. While recent work has demonstrated the potential of large language models (LLMs) for false alarm reduction on open-source benchmarks, their effectiveness in real-world enterprise settings remains unclear. To bridge this gap, we conduct the first comprehensive empirical study of diverse LLM-based false alarm reduction techniques in an industrial context at Tencent, one of the largest IT companies in China. Using data from Tencent's enterprise-customized SAT on its large-scale Advertising and Marketing Services software, we construct a dataset of 433 alarms (328 false positives, 105 true positives) covering three common bug types. Through interviewing developers and analyzing the data, our results highlight the prevalence of false positives, which wastes substantial manual effort (e.g., 10-20 minutes of manual inspection per alarm). Meanwhile, our results show the huge potential of LLMs for reducing false alarms in industrial settings (e.g., hybrid techniques of LLM and static analysis eliminate 94-98% of false positives with high recall). Furthermore, LLM-based techniques are cost-effective, with per-alarm costs as low as 2.1-109.5 seconds and $0.0011-$0.12, representing orders-of-magnitude savings compared to manual review. Finally, our case analysis further identifies key limitations of LLM-based false alarm reduction in industrial settings.
MiLMo:Minority Multilingual Pre-trained Language Model
Dec 04, 2022



Pre-trained language models are trained on large-scale unsupervised data, and they can be fine-tuned on small-scale labeled datasets and achieve good results. Multilingual pre-trained language models can be trained on multiple languages and understand multiple languages at the same time. At present, the research on pre-trained models mainly focuses on rich-resource language, while there is relatively little research on low-resource languages such as minority languages, and the public multilingual pre-trained language model can not work well for minority languages. Therefore, this paper constructs a multilingual pre-trained language model named MiLMo that performs better on minority language tasks, including Mongolian, Tibetan, Uyghur, Kazakh and Korean. To solve the problem of scarcity of datasets on minority languages and verify the effectiveness of the MiLMo model, this paper constructs a minority multilingual text classification dataset named MiTC, and trains a word2vec model for each language. By comparing the word2vec model and the pre-trained model in the text classification task, this paper provides an optimal scheme for the downstream task research of minority languages. The final experimental results show that the performance of the pre-trained model is better than that of the word2vec model, and it has achieved the best results in minority multilingual text classification. The multilingual pre-trained language model MiLMo, multilingual word2vec model and multilingual text classification dataset MiTC are published on https://milmo.cmli-nlp.com.
TiBERT: Tibetan Pre-trained Language Model
May 15, 2022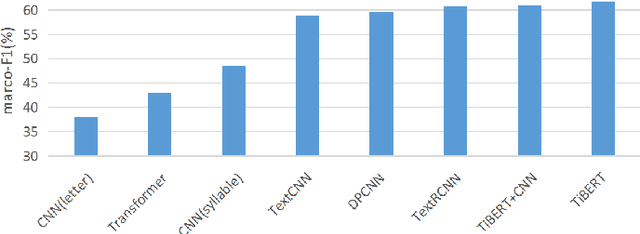
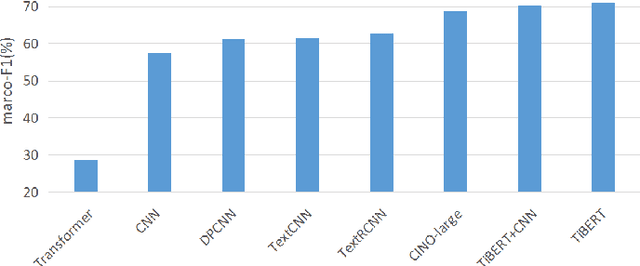


The pre-trained language model is trained on large-scale unlabeled text and can achieve state-of-the-art results in many different downstream tasks. However, the current pre-trained language model is mainly concentrated in the Chinese and English fields. For low resource language such as Tibetan, there is lack of a monolingual pre-trained model. To promote the development of Tibetan natural language processing tasks, this paper collects the large-scale training data from Tibetan websites and constructs a vocabulary that can cover 99.95$\%$ of the words in the corpus by using Sentencepiece. Then, we train the Tibetan monolingual pre-trained language model named TiBERT on the data and vocabulary. Finally, we apply TiBERT to the downstream tasks of text classification and question generation, and compare it with classic models and multilingual pre-trained models, the experimental results show that TiBERT can achieve the best performance. Our model is published in http://tibert.cmli-nlp.com/