 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMS-Net: Regression and Masking for Soccer Event Spotting
Feb 15, 2021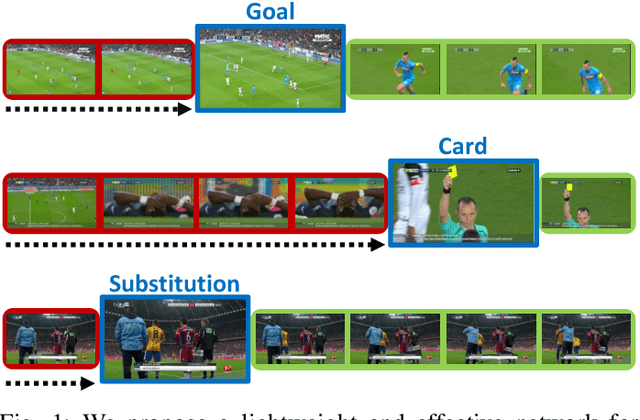
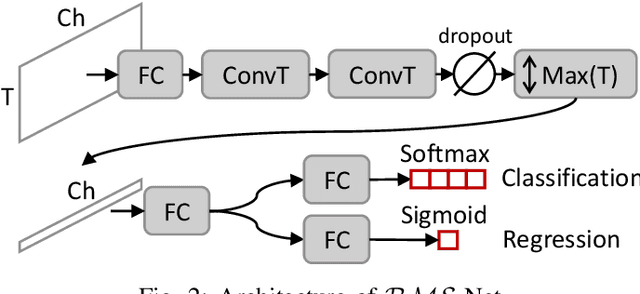
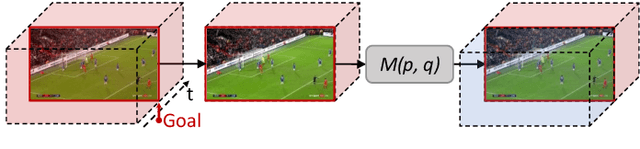
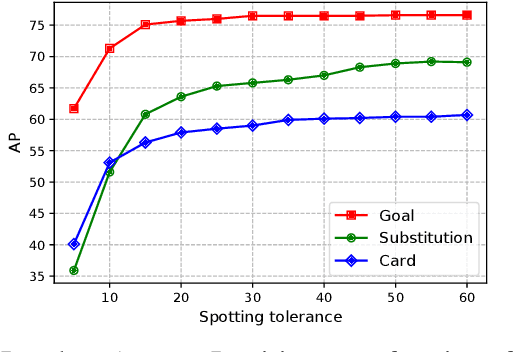
The recently proposed action spotting task consists in finding the exact timestamp in which an event occurs. This task fits particularly well for soccer videos, where events correspond to salient actions strictly defined by soccer rules (a goal occurs when the ball crosses the goal line). In this paper, we devise a lightweight and modular network for action spotting, which can simultaneously predict the event label and its temporal offset using the same underlying features. We enrich our model with two training strategies: the first one for data balancing and uniform sampling, the second for masking ambiguous frames and keeping the most discriminative visual cues. When tested on the SoccerNet dataset and using standard features, our full proposal exceeds the current state of the art by 3 Average-mAP points. Additionally, it reaches a gain of more than 10 Average-mAP points on the test set when fine-tuned in combination with a strong 2D backbone.
Generalising via Meta-Examples for Continual Learning in the Wild
Jan 28, 2021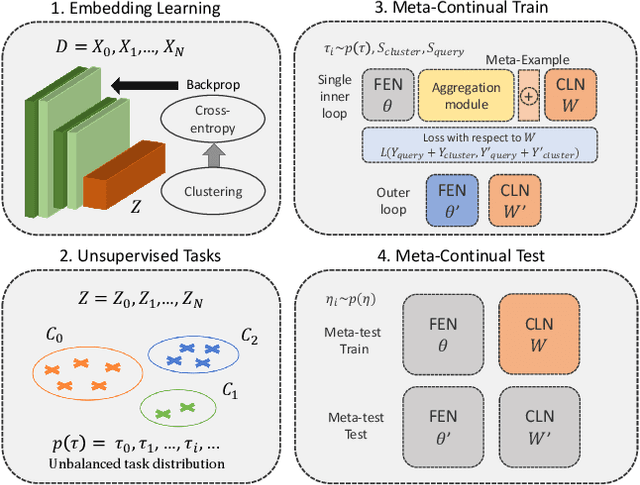
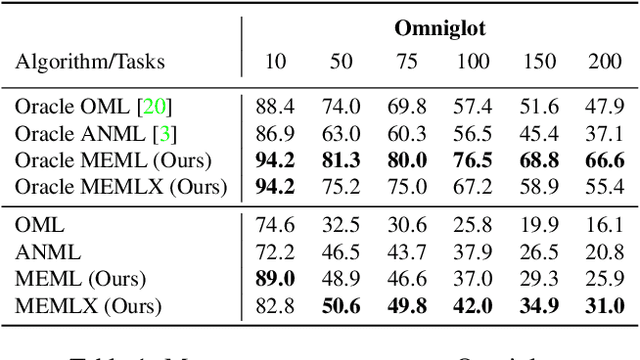
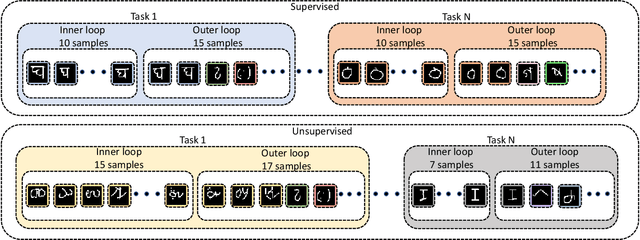
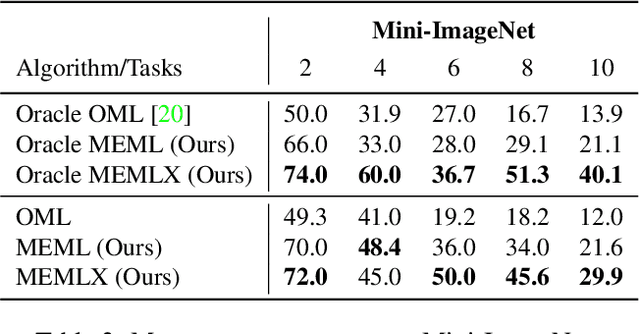
Learning quickly and continually is still an ambitious task for neural networks. Indeed, many real-world applications do not reflect the learning setting where neural networks shine, as data are usually few, mostly unlabelled and come as a stream. To narrow this gap, we introduce FUSION - Few-shot UnSupervIsed cONtinual learning - a novel strategy which aims to deal with neural networks that "learn in the wild", simulating a real distribution and flow of unbalanced tasks. We equip FUSION with MEML - Meta-Example Meta-Learning - a new module that simultaneously alleviates catastrophic forgetting and favours the generalisation and future learning of new tasks. To encourage features reuse during the meta-optimisation, our model exploits a single inner loop per task, taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. To further enhance the generalisation capability of MEML, we extend it by adopting a technique that creates various augmented tasks and optimises over the hardest. Experimental results on few-shot learning benchmarks show that our model exceeds the other baselines in both FUSION and fully supervised case. We also explore how it behaves in standard continual learning consistently outperforming state-of-the-art approaches.
Rethinking Experience Replay: a Bag of Tricks for Continual Learning
Oct 12, 2020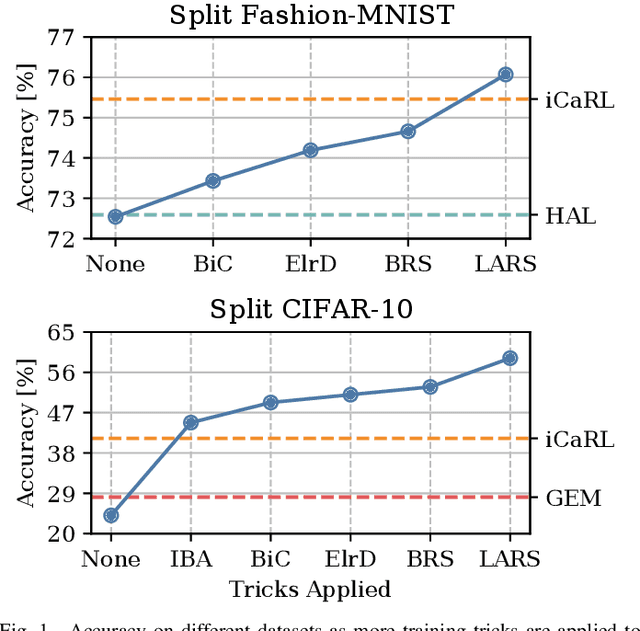
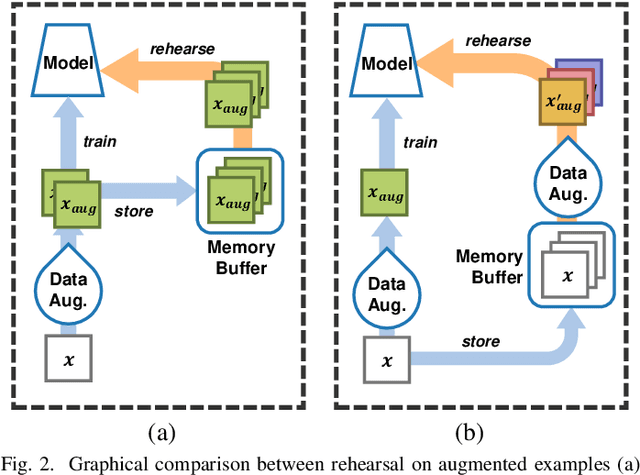

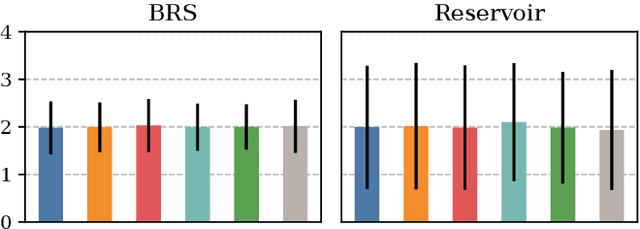
In Continual Learning, a Neural Network is trained on a stream of data whose distribution shifts over time. Under these assumptions, it is especially challenging to improve on classes appearing later in the stream while remaining accurate on previous ones. This is due to the infamous problem of catastrophic forgetting, which causes a quick performance degradation when the classifier focuses on learning new categories. Recent literature proposed various approaches to tackle this issue, often resorting to very sophisticated techniques. In this work, we show that naive rehearsal can be patched to achieve similar performance. We point out some shortcomings that restrain Experience Replay (ER) and propose five tricks to mitigate them. Experiments show that ER, thus enhanced, displays an accuracy gain of 51.2 and 26.9 percentage points on the CIFAR-10 and CIFAR-100 datasets respectively (memory buffer size 1000). As a result, it surpasses current state-of-the-art rehearsal-based methods.
Few-Shot Unsupervised Continual Learning through Meta-Examples
Sep 17, 2020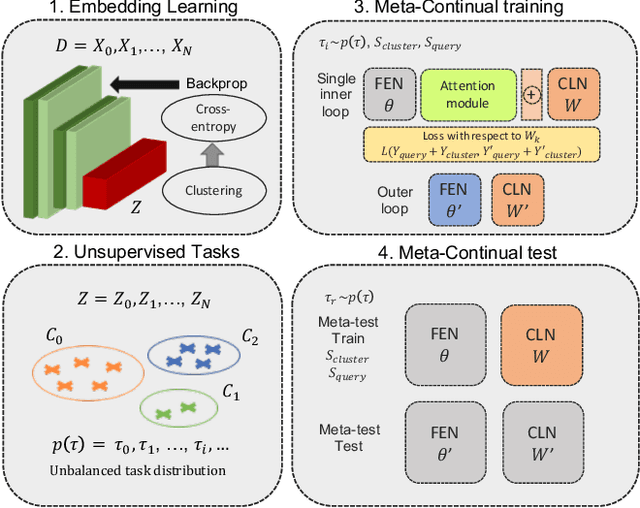
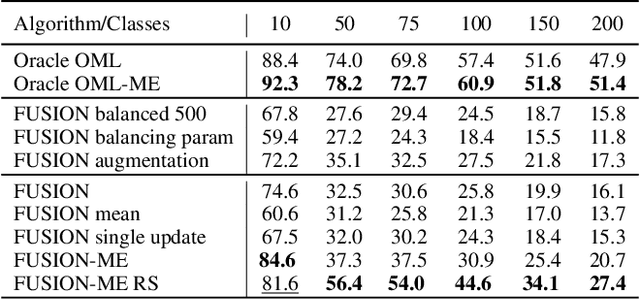
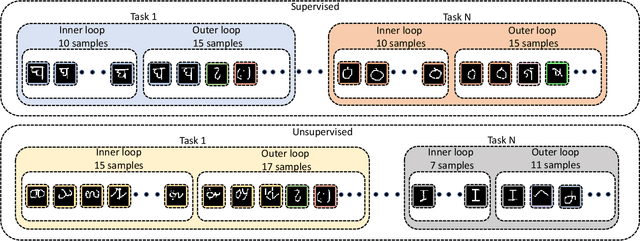
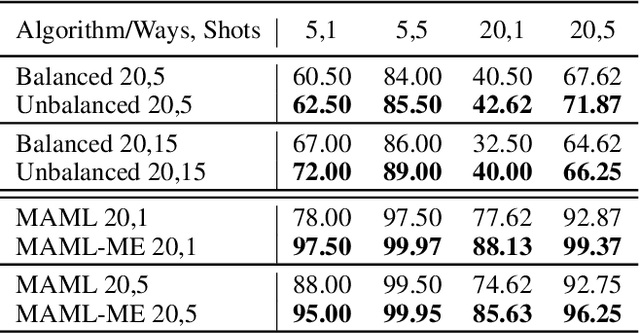
In real-world applications, data do not reflect the ones commonly used for neural networks training, since they are usually few, unbalanced, unlabeled and can be available as a stream. Hence many existing deep learning solutions suffer from a limited range of applications, in particular in the case of online streaming data that evolve over time. To narrow this gap, in this work we introduce a novel and complex setting involving unsupervised meta-continual learning with unbalanced tasks. These tasks are built through a clustering procedure applied to a fitted embedding space. We exploit a meta-learning scheme that simultaneously alleviates catastrophic forgetting and favors the generalization to new tasks, even Out-of-Distribution ones. Moreover, to encourage feature reuse during the meta-optimization, we exploit a single inner loop taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. Experimental results on few-shot learning benchmarks show competitive performance even compared to the supervised case. Additionally, we empirically observe that in an unsupervised scenario, the small tasks and the variability in the clusters pooling play a crucial role in the generalization capability of the network. Further, on complex datasets, the exploitation of more clusters than the true number of classes leads to higher results, even compared to the ones obtained with full supervision, suggesting that a predefined partitioning into classes can miss relevant structural information.
Inter-Homines: Distance-Based Risk Estimation for Human Safety
Jul 20, 2020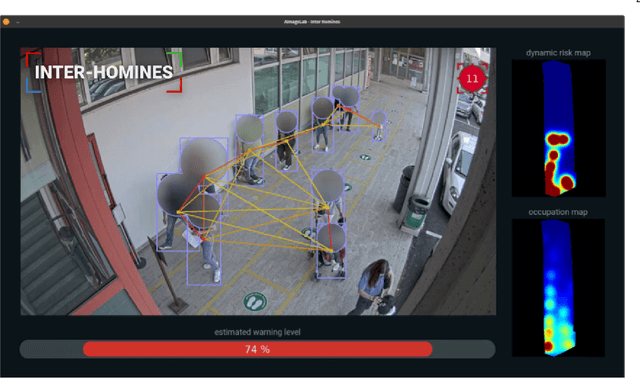
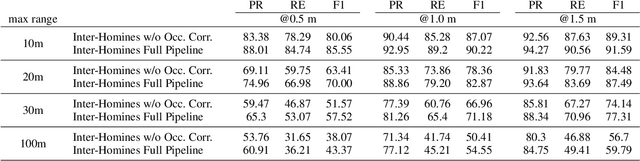
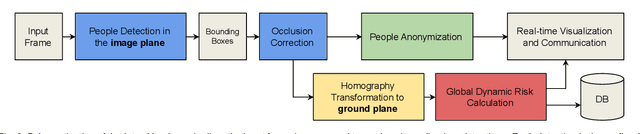

In this document, we report our proposal for modeling the risk of possible contagiousity in a given area monitored by RGB cameras where people freely move and interact. Our system, called Inter-Homines, evaluates in real-time the contagion risk in a monitored area by analyzing video streams: it is able to locate people in 3D space, calculate interpersonal distances and predict risk levels by building dynamic maps of the monitored area. Inter-Homines works both indoor and outdoor, in public and private crowded areas. The software is applicable to already installed cameras or low-cost cameras on industrial PCs, equipped with an additional embedded edge-AI system for temporary measurements. From the AI-side, we exploit a robust pipeline for real-time people detection and localization in the ground plane by homographic transformation based on state-of-the-art computer vision algorithms; it is a combination of a people detector and a pose estimator. From the risk modeling side, we propose a parametric model for a spatio-temporal dynamic risk estimation, that, validated by epidemiologists, could be useful for safety monitoring the acceptance of social distancing prevention measures by predicting the risk level of the scene.
Robust Re-Identification by Multiple Views Knowledge Distillation
Jul 08, 2020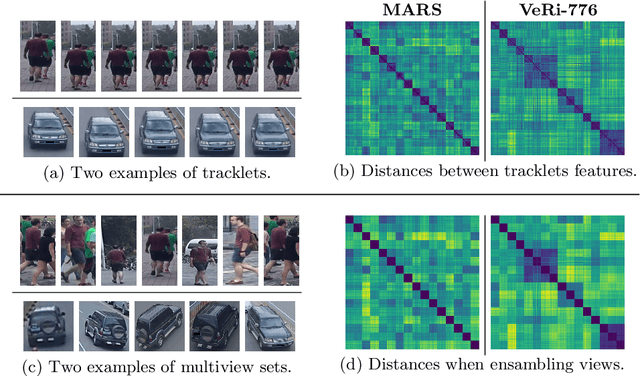
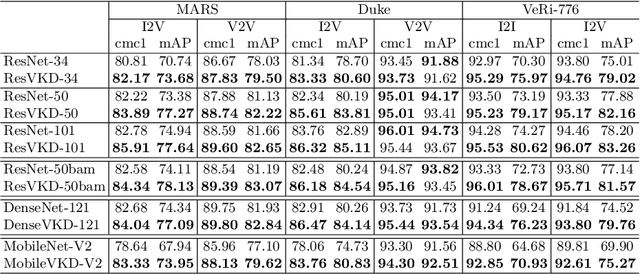

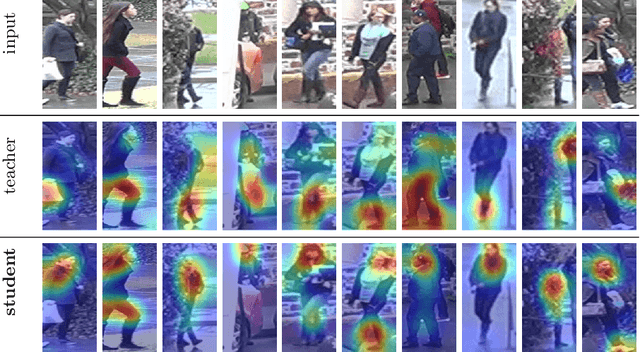
To achieve robustness in Re-Identification, standard methods leverage tracking information in a Video-To-Video fashion. However, these solutions face a large drop in performance for single image queries (e.g., Image-To-Video setting). Recent works address this severe degradation by transferring temporal information from a Video-based network to an Image-based one. In this work, we devise a training strategy that allows the transfer of a superior knowledge, arising from a set of views depicting the target object. Our proposal - Views Knowledge Distillation (VKD) - pins this visual variety as a supervision signal within a teacher-student framework, where the teacher educates a student who observes fewer views. As a result, the student outperforms not only its teacher but also the current state-of-the-art in Image-To-Video by a wide margin (6.3% mAP on MARS, 8.6% on Duke-Video-ReId and 5% on VeRi-776). A thorough analysis - on Person, Vehicle and Animal Re-ID - investigates the properties of VKD from a qualitatively and quantitatively perspective. Code is available at https://github.com/aimagelab/VKD.
Future Urban Scenes Generation Through Vehicles Synthesis
Jul 01, 2020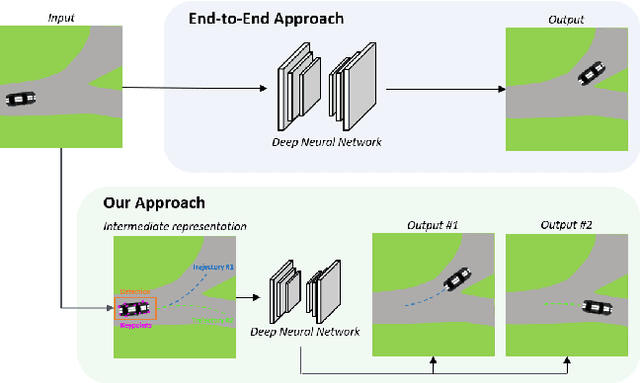
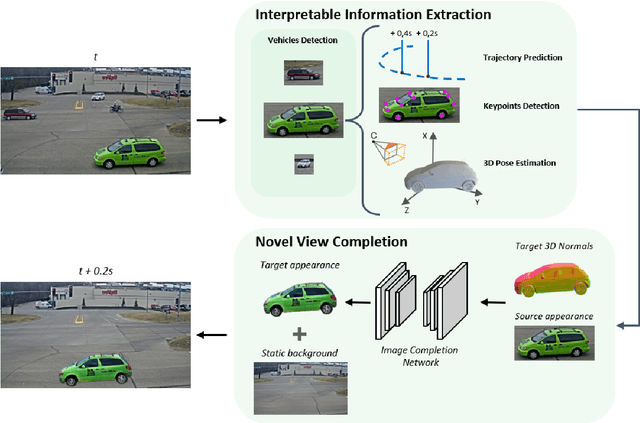

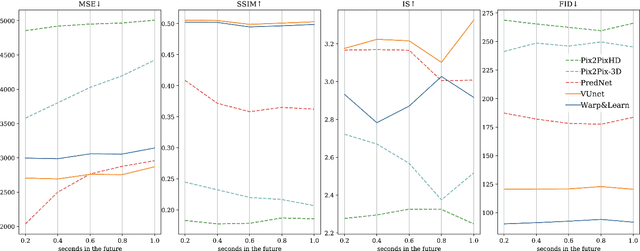
In this work we propose a deep learning pipeline to predict the visual future appearance of an urban scene. Despite recent advances, generating the entire scene in an end-to-end fashion is still far from being achieved. Instead, here we follow a two stages approach, where interpretable information is included in the loop and each actor is modelled independently. We leverage a per-object novel view synthesis paradigm; i.e. generating a synthetic representation of an object undergoing a geometrical roto-translation in the 3D space. Our model can be easily conditioned with constraints (e.g. input trajectories) provided by state-of-the-art tracking methods or by the user itself. This allows us to generate a set of diverse realistic futures starting from the same input in a multi-modal fashion. We visually and quantitatively show the superiority of this approach over traditional end-to-end scene-generation methods on CityFlow, a challenging real world dataset.
The color out of space: learning self-supervised representations for Earth Observation imagery
Jun 22, 2020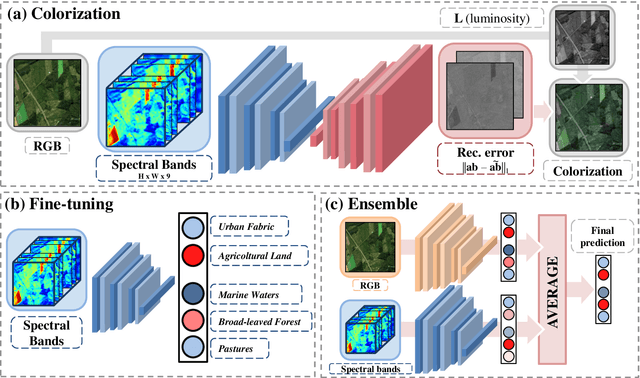
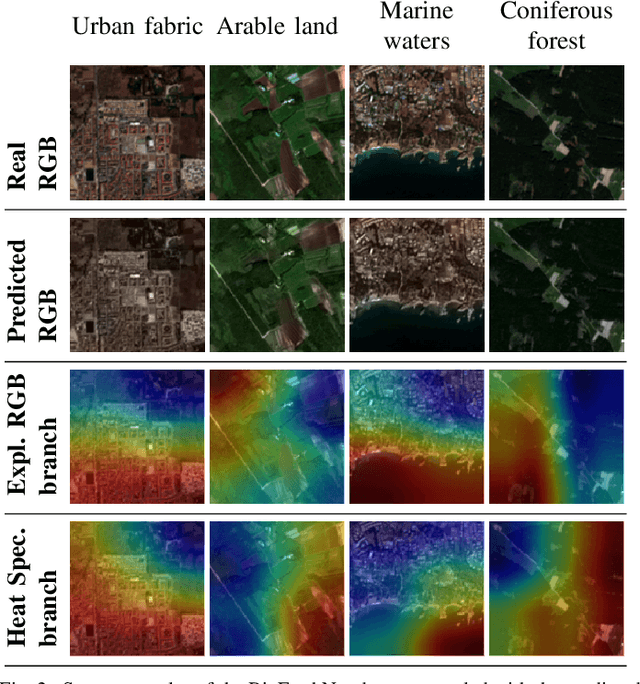
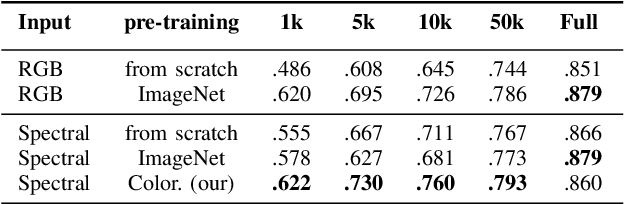
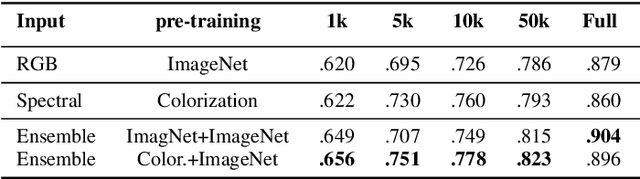
The recent growth in the number of satellite images fosters the development of effective deep-learning techniques for Remote Sensing (RS). However, their full potential is untapped due to the lack of large annotated datasets. Such a problem is usually countered by fine-tuning a feature extractor that is previously trained on the ImageNet dataset. Unfortunately, the domain of natural images differs from the RS one, which hinders the final performance. In this work, we propose to learn meaningful representations from satellite imagery, leveraging its high-dimensionality spectral bands to reconstruct the visible colors. We conduct experiments on land cover classification (BigEarthNet) and West Nile Virus detection, showing that colorization is a solid pretext task for training a feature extractor. Furthermore, we qualitatively observe that guesses based on natural images and colorization rely on different parts of the input. This paves the way to an ensemble model that eventually outperforms both the above-mentioned techniques.
DAG-Net: Double Attentive Graph Neural Network for Trajectory Forecasting
May 26, 2020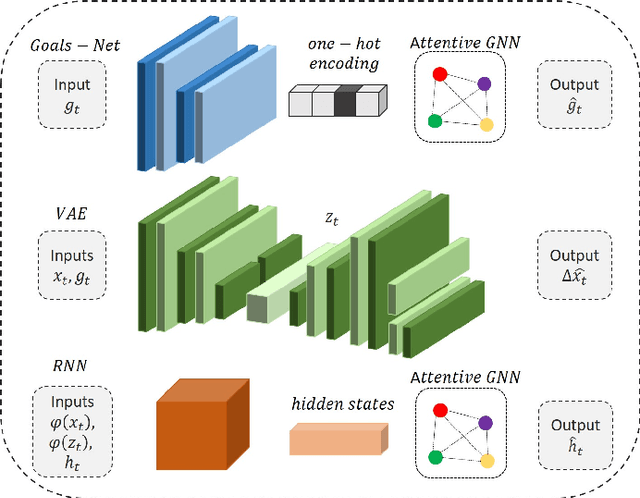
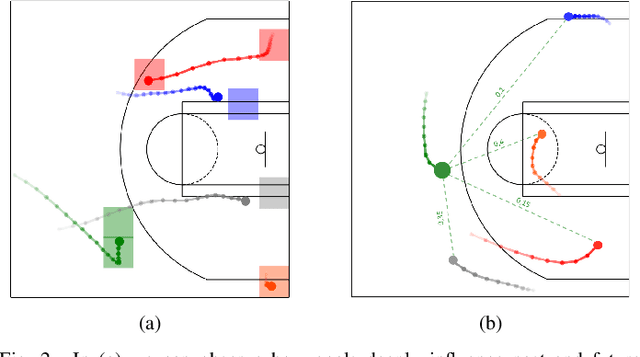
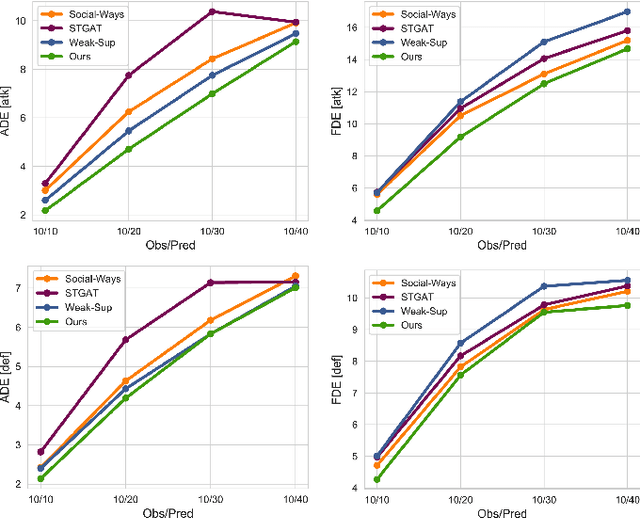
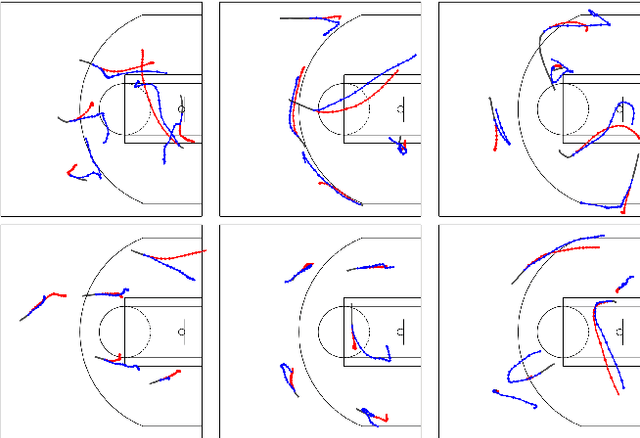
Understanding human motion behaviour is a critical task for several possible applications like self-driving cars or social robots, and in general for all those settings where an autonomous agent has to navigate inside a human-centric environment. This is non-trivial because human motion is inherently multi-modal: given a history of human motion paths, there are many plausible ways by which people could move in the future. Additionally, people activities are often driven by goals, e.g. reaching particular locations or interacting with the environment. We address both the aforementioned aspects by proposing a new recurrent generative model that considers both single agents' future goals and interactions between different agents. The model exploits a double attention-based graph neural network to collect information about the mutual influences among different agents and integrates it with data about agents' possible future objectives. Our proposal is general enough to be applied in different scenarios: the model achieves state-of-the-art results in both urban environments and also in sports applications.
AC-VRNN: Attentive Conditional-VRNN for Multi-Future Trajectory Prediction
May 17, 2020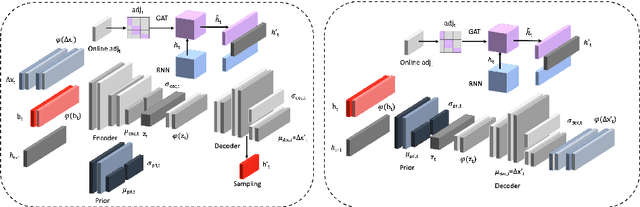
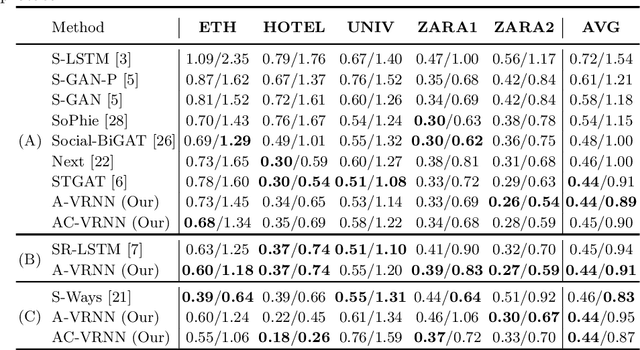
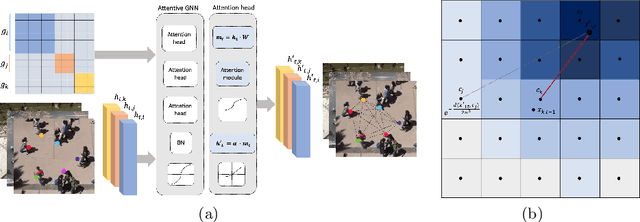
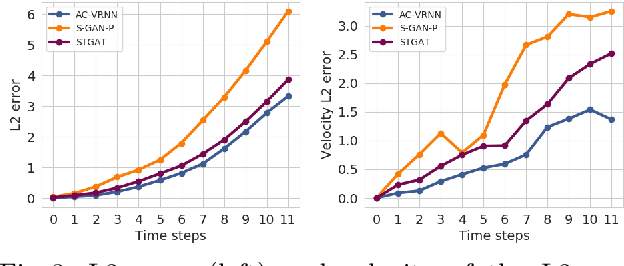
Anticipating human motion in crowded scenarios is essential for developing intelligent transportation systems, social-aware robots and advanced video-surveillance applications. An important aspect of such task is represented by the inherently multi-modal nature of human paths which makes socially-acceptable multiple futures when human interactions are involved. To this end, we propose a new generative model for multi-future trajectory prediction based on Conditional Variational Recurrent Neural Networks (C-VRNNs). Conditioning relies on prior belief maps, representing most likely moving directions and forcing the model to consider the collective agents' motion. Human interactions are modeled in a structured way with a graph attention mechanism, providing an online attentive hidden state refinement of the recurrent estimation. Compared to sequence-to-sequence methods, our model operates step-by-step, generating more refined and accurate predictions. To corroborate our model, we perform extensive experiments on publicly-available datasets (ETH, UCY and Stanford Drone Dataset) and demonstrate its effectiveness compared to state-of-the-art methods.