 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro Symbolic Continual Learning: Knowledge, Reasoning Shortcuts and Concept Rehearsal
Feb 02, 2023



We introduce Neuro-Symbolic Continual Learning, where a model has to solve a sequence of neuro-symbolic tasks, that is, it has to map sub-symbolic inputs to high-level concepts and compute predictions by reasoning consistently with prior knowledge. Our key observation is that neuro-symbolic tasks, although different, often share concepts whose semantics remains stable over time. Traditional approaches fall short: existing continual strategies ignore knowledge altogether, while stock neuro-symbolic architectures suffer from catastrophic forgetting. We show that leveraging prior knowledge by combining neuro-symbolic architectures with continual strategies does help avoid catastrophic forgetting, but also that doing so can yield models affected by reasoning shortcuts. These undermine the semantics of the acquired concepts, even when detailed prior knowledge is provided upfront and inference is exact, and in turn continual performance. To overcome these issues, we introduce COOL, a COncept-level cOntinual Learning strategy tailored for neuro-symbolic continual problems that acquires high-quality concepts and remembers them over time. Our experiments on three novel benchmarks highlights how COOL attains sustained high performance on neuro-symbolic continual learning tasks in which other strategies fail.
Input Perturbation Reduces Exposure Bias in Diffusion Models
Jan 27, 2023Denoising Diffusion Probabilistic Models have shown an impressive generation quality, although their long sampling chain leads to high computational costs. In this paper, we observe that a long sampling chain also leads to an error accumulation phenomenon, which is similar to the \textbf{exposure bias} problem in autoregressive text generation. Specifically, we note that there is a discrepancy between training and testing, since the former is conditioned on the ground truth samples, while the latter is conditioned on the previously generated results. To alleviate this problem, we propose a very simple but effective training regularization, consisting in perturbing the ground truth samples to simulate the inference time prediction errors. We empirically show that the proposed input perturbation leads to a significant improvement of the sample quality while reducing both the training and the inference times. For instance, on CelebA 64$\times$64, we achieve a new state-of-the-art FID score of 1.27, while saving 37.5% of the training time.
CaSpeR: Latent Spectral Regularization for Continual Learning
Jan 09, 2023While biological intelligence grows organically as new knowledge is gathered throughout life, Artificial Neural Networks forget catastrophically whenever they face a changing training data distribution. Rehearsal-based Continual Learning (CL) approaches have been established as a versatile and reliable solution to overcome this limitation; however, sudden input disruptions and memory constraints are known to alter the consistency of their predictions. We study this phenomenon by investigating the geometric characteristics of the learner's latent space and find that replayed data points of different classes increasingly mix up, interfering with classification. Hence, we propose a geometric regularizer that enforces weak requirements on the Laplacian spectrum of the latent space, promoting a partitioning behavior. We show that our proposal, called Continual Spectral Regularizer (CaSpeR), can be easily combined with any rehearsal-based CL approach and improves the performance of SOTA methods on standard benchmarks. Finally, we conduct additional analysis to provide insights into CaSpeR's effects and applicability.
On the Effectiveness of Lipschitz-Driven Rehearsal in Continual Learning
Oct 16, 2022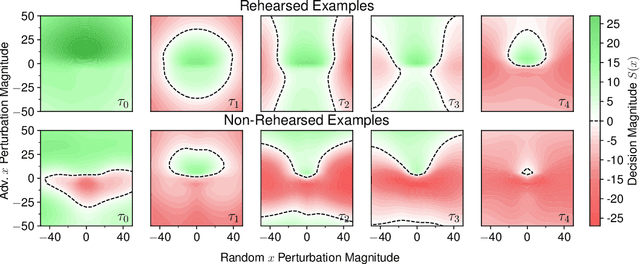
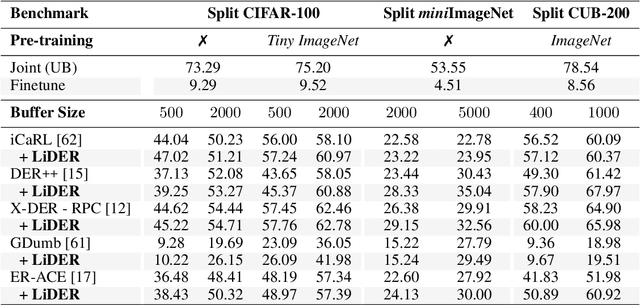
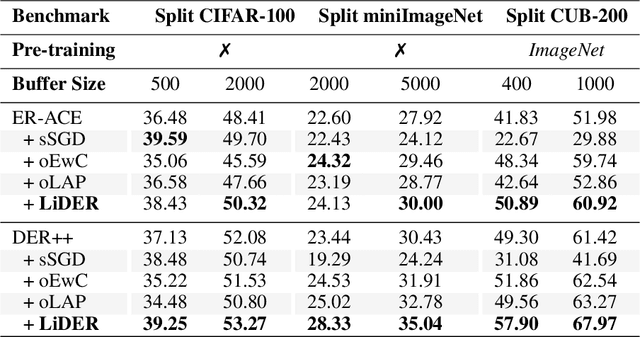
Rehearsal approaches enjoy immense popularity with Continual Learning (CL) practitioners. These methods collect samples from previously encountered data distributions in a small memory buffer; subsequently, they repeatedly optimize on the latter to prevent catastrophic forgetting. This work draws attention to a hidden pitfall of this widespread practice: repeated optimization on a small pool of data inevitably leads to tight and unstable decision boundaries, which are a major hindrance to generalization. To address this issue, we propose Lipschitz-DrivEn Rehearsal (LiDER), a surrogate objective that induces smoothness in the backbone network by constraining its layer-wise Lipschitz constants w.r.t. replay examples. By means of extensive experiments, we show that applying LiDER delivers a stable performance gain to several state-of-the-art rehearsal CL methods across multiple datasets, both in the presence and absence of pre-training. Through additional ablative experiments, we highlight peculiar aspects of buffer overfitting in CL and better characterize the effect produced by LiDER. Code is available at https://github.com/aimagelab/LiDER
Spotting Virus from Satellites: Modeling the Circulation of West Nile Virus Through Graph Neural Networks
Sep 07, 2022
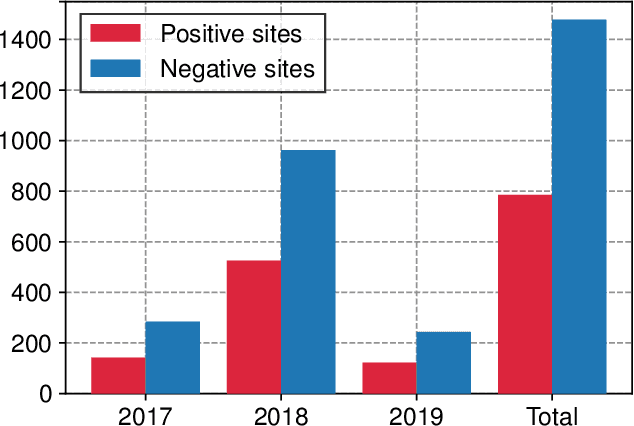
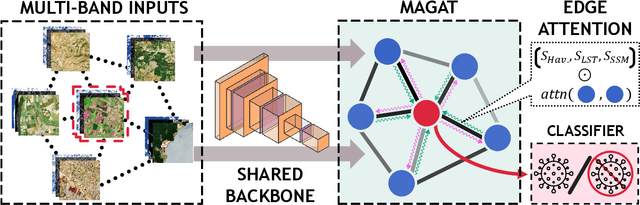
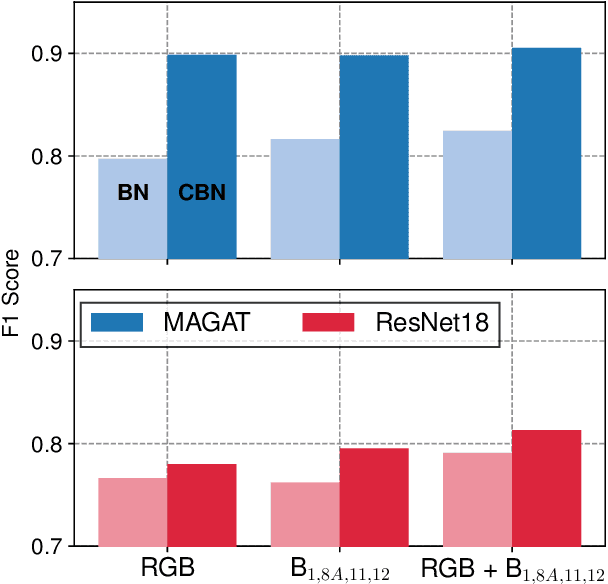
The occurrence of West Nile Virus (WNV) represents one of the most common mosquito-borne zoonosis viral infections. Its circulation is usually associated with climatic and environmental conditions suitable for vector proliferation and virus replication. On top of that, several statistical models have been developed to shape and forecast WNV circulation: in particular, the recent massive availability of Earth Observation (EO) data, coupled with the continuous advances in the field of Artificial Intelligence, offer valuable opportunities. In this paper, we seek to predict WNV circulation by feeding Deep Neural Networks (DNNs) with satellite images, which have been extensively shown to hold environmental and climatic features. Notably, while previous approaches analyze each geographical site independently, we propose a spatial-aware approach that considers also the characteristics of close sites. Specifically, we build upon Graph Neural Networks (GNN) to aggregate features from neighbouring places, and further extend these modules to consider multiple relations, such as the difference in temperature and soil moisture between two sites, as well as the geographical distance. Moreover, we inject time-related information directly into the model to take into account the seasonality of virus spread. We design an experimental setting that combines satellite images - from Landsat and Sentinel missions - with ground truth observations of WNV circulation in Italy. We show that our proposed Multi-Adjacency Graph Attention Network (MAGAT) consistently leads to higher performance when paired with an appropriate pre-training stage. Finally, we assess the importance of each component of MAGAT in our ablation studies.
Consistency-based Self-supervised Learning for Temporal Anomaly Localization
Aug 10, 2022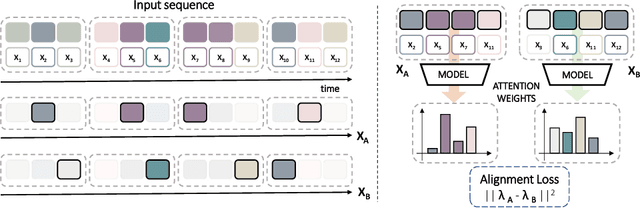

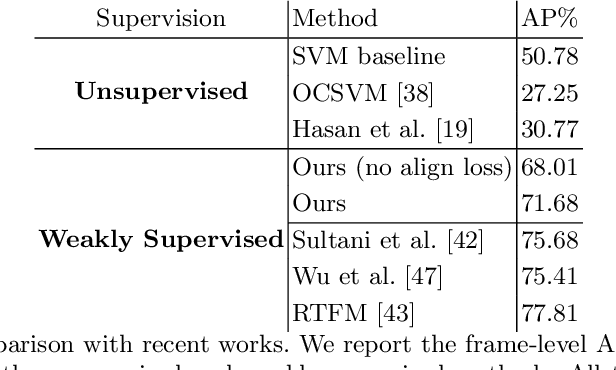
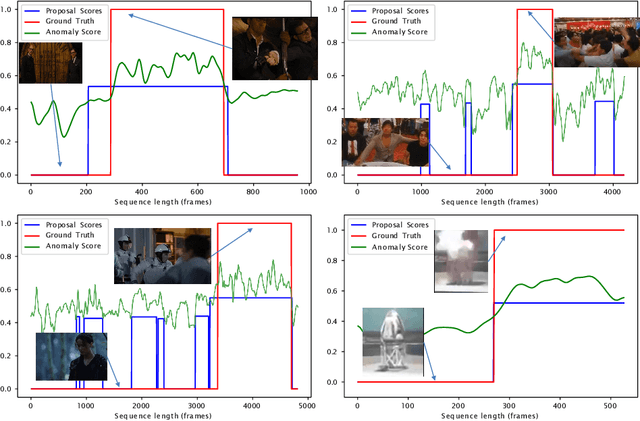
This work tackles Weakly Supervised Anomaly detection, in which a predictor is allowed to learn not only from normal examples but also from a few labeled anomalies made available during training. In particular, we deal with the localization of anomalous activities within the video stream: this is a very challenging scenario, as training examples come only with video-level annotations (and not frame-level). Several recent works have proposed various regularization terms to address it i.e. by enforcing sparsity and smoothness constraints over the weakly-learned frame-level anomaly scores. In this work, we get inspired by recent advances within the field of self-supervised learning and ask the model to yield the same scores for different augmentations of the same video sequence. We show that enforcing such an alignment improves the performance of the model on XD-Violence.
Learning the Quality of Machine Permutations in Job Shop Scheduling
Jul 07, 2022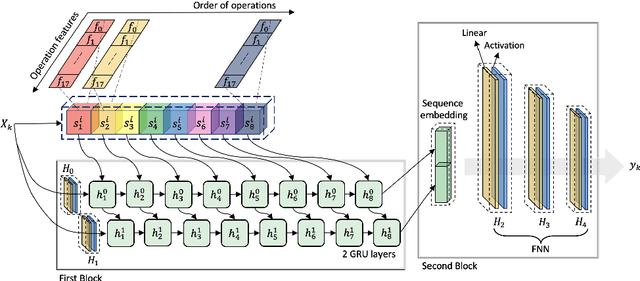
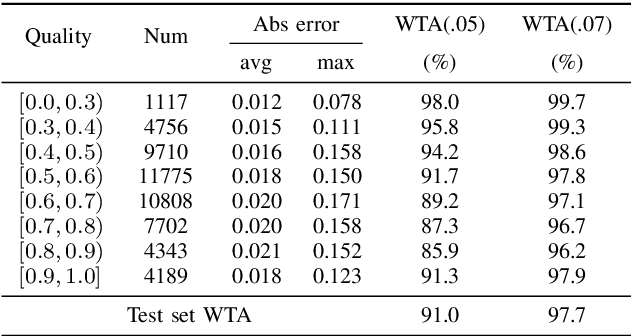
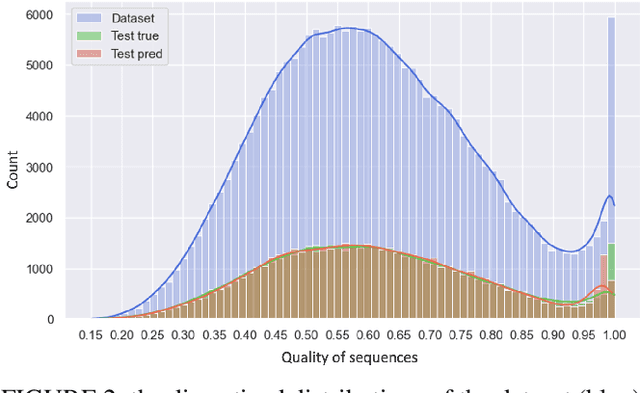

In recent years, the power demonstrated by Machine Learning (ML) has increasingly attracted the interest of the optimization community that is starting to leverage ML for enhancing and automating the design of optimal and approximate algorithms. One combinatorial optimization problem that has been tackled with ML is the Job Shop scheduling Problem (JSP). Most of the recent works focusing on the JSP and ML are based on Deep Reinforcement Learning (DRL), and only a few of them leverage supervised learning techniques. The recurrent reasons for avoiding supervised learning seem to be the difficulty in casting the right learning task, i.e., what is meaningful to predict, and how to obtain labels. Therefore, we first propose a novel supervised learning task that aims at predicting the quality of machine permutations. Then, we design an original methodology to estimate this quality that allows to create an accurate sequential deep learning model (binary accuracy above 95%). Finally, we empirically demonstrate the value of predicting the quality of machine permutations by enhancing the performance of a simple Tabu Search algorithm inspired by the works in the literature.
Effects of Auxiliary Knowledge on Continual Learning
Jun 03, 2022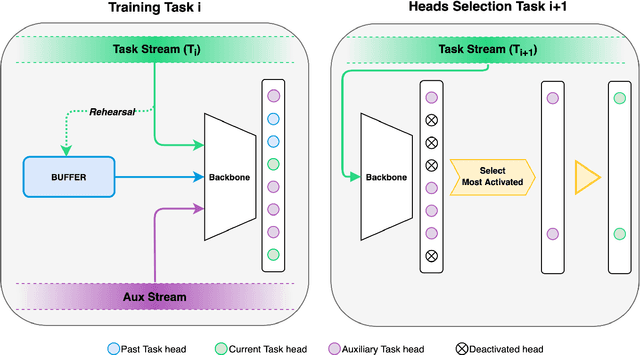
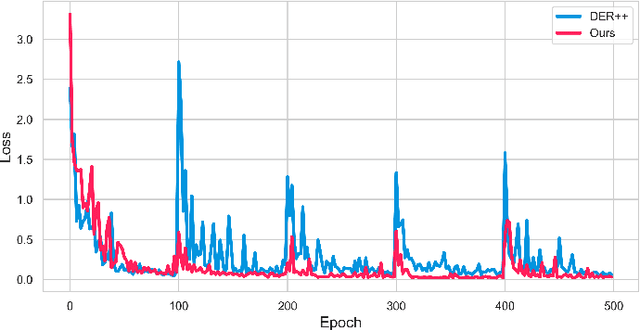
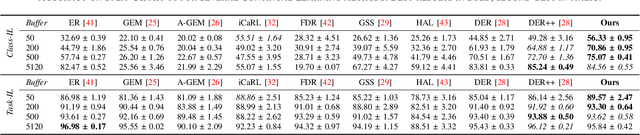
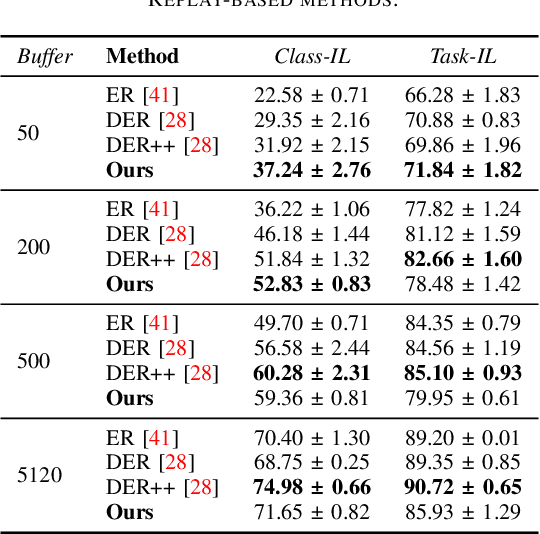
In Continual Learning (CL), a neural network is trained on a stream of data whose distribution changes over time. In this context, the main problem is how to learn new information without forgetting old knowledge (i.e., Catastrophic Forgetting). Most existing CL approaches focus on finding solutions to preserve acquired knowledge, so working on the past of the model. However, we argue that as the model has to continually learn new tasks, it is also important to put focus on the present knowledge that could improve following tasks learning. In this paper we propose a new, simple, CL algorithm that focuses on solving the current task in a way that might facilitate the learning of the next ones. More specifically, our approach combines the main data stream with a secondary, diverse and uncorrelated stream, from which the network can draw auxiliary knowledge. This helps the model from different perspectives, since auxiliary data may contain useful features for the current and the next tasks and incoming task classes can be mapped onto auxiliary classes. Furthermore, the addition of data to the current task is implicitly making the classifier more robust as we are forcing the extraction of more discriminative features. Our method can outperform existing state-of-the-art models on the most common CL Image Classification benchmarks.
Transfer without Forgetting
Jun 01, 2022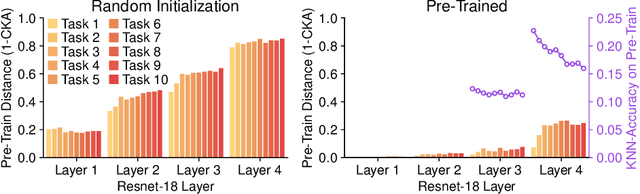
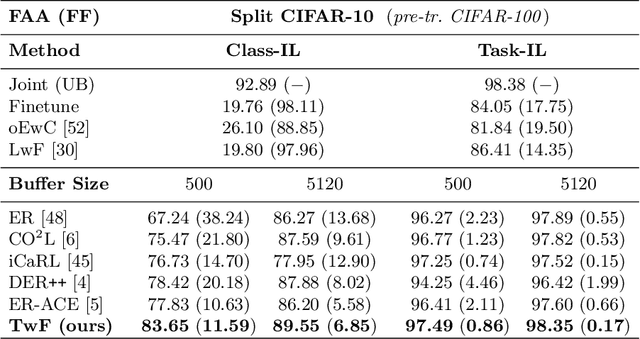
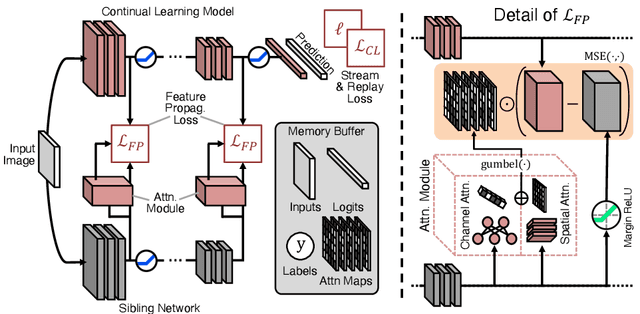
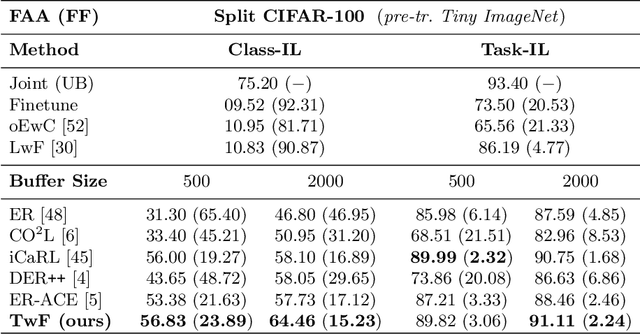
This work investigates the entanglement between Continual Learning (CL) and Transfer Learning (TL). In particular, we shed light on the widespread application of network pretraining, highlighting that it is itself subject to catastrophic forgetting. Unfortunately, this issue leads to the under-exploitation of knowledge transfer during later tasks. On this ground, we propose Transfer without Forgetting (TwF), a hybrid Continual Transfer Learning approach building upon a fixed pretrained sibling network, which continuously propagates the knowledge inherent in the source domain through a layer-wise loss term. Our experiments indicate that TwF steadily outperforms other CL methods across a variety of settings, averaging a 4.81% gain in Class-Incremental accuracy over a variety of datasets and different buffer sizes.
Goal-driven Self-Attentive Recurrent Networks for Trajectory Prediction
Apr 25, 2022



Human trajectory forecasting is a key component of autonomous vehicles, social-aware robots and advanced video-surveillance applications. This challenging task typically requires knowledge about past motion, the environment and likely destination areas. In this context, multi-modality is a fundamental aspect and its effective modeling can be beneficial to any architecture. Inferring accurate trajectories is nevertheless challenging, due to the inherently uncertain nature of the future. To overcome these difficulties, recent models use different inputs and propose to model human intentions using complex fusion mechanisms. In this respect, we propose a lightweight attention-based recurrent backbone that acts solely on past observed positions. Although this backbone already provides promising results, we demonstrate that its prediction accuracy can be improved considerably when combined with a scene-aware goal-estimation module. To this end, we employ a common goal module, based on a U-Net architecture, which additionally extracts semantic information to predict scene-compliant destinations. We conduct extensive experiments on publicly-available datasets (i.e. SDD, inD, ETH/UCY) and show that our approach performs on par with state-of-the-art techniques while reducing model complexity.