 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Corpus Poisoning Attacks in Continuous Space for Dense Retrieval
Apr 24, 2025This paper concerns corpus poisoning attacks in dense information retrieval, where an adversary attempts to compromise the ranking performance of a search algorithm by injecting a small number of maliciously generated documents into the corpus. Our work addresses two limitations in the current literature. First, attacks that perform adversarial gradient-based word substitution search do so in the discrete lexical space, while retrieval itself happens in the continuous embedding space. We thus propose an optimization method that operates in the embedding space directly. Specifically, we train a perturbation model with the objective of maintaining the geometric distance between the original and adversarial document embeddings, while also maximizing the token-level dissimilarity between the original and adversarial documents. Second, it is common for related work to have a strong assumption that the adversary has prior knowledge about the queries. In this paper, we focus on a more challenging variant of the problem where the adversary assumes no prior knowledge about the query distribution (hence, unsupervised). Our core contribution is an adversarial corpus attack that is fast and effective. We present comprehensive experimental results on both in- and out-of-domain datasets, focusing on two related tasks: a top-1 attack and a corpus poisoning attack. We consider attacks under both a white-box and a black-box setting. Notably, our method can generate successful adversarial examples in under two minutes per target document; four times faster compared to the fastest gradient-based word substitution methods in the literature with the same hardware. Furthermore, our adversarial generation method generates text that is more likely to occur under the distribution of natural text (low perplexity), and is therefore more difficult to detect.
Conversational Gold: Evaluating Personalized Conversational Search System using Gold Nuggets
Mar 12, 2025The rise of personalized conversational search systems has been driven by advancements in Large Language Models (LLMs), enabling these systems to retrieve and generate answers for complex information needs. However, the automatic evaluation of responses generated by Retrieval Augmented Generation (RAG) systems remains an understudied challenge. In this paper, we introduce a new resource for assessing the retrieval effectiveness and relevance of response generated by RAG systems, using a nugget-based evaluation framework. Built upon the foundation of TREC iKAT 2023, our dataset extends to the TREC iKAT 2024 collection, which includes 17 conversations and 20,575 relevance passage assessments, together with 2,279 extracted gold nuggets, and 62 manually written gold answers from NIST assessors. While maintaining the core structure of its predecessor, this new collection enables a deeper exploration of generation tasks in conversational settings. Key improvements in iKAT 2024 include: (1) ``gold nuggets'' -- concise, essential pieces of information extracted from relevant passages of the collection -- which serve as a foundation for automatic response evaluation; (2) manually written answers to provide a gold standard for response evaluation; (3) unanswerable questions to evaluate model hallucination; (4) expanded user personas, providing richer contextual grounding; and (5) a transition from Personal Text Knowledge Base (PTKB) ranking to PTKB classification and selection. Built on this resource, we provide a framework for long-form answer generation evaluation, involving nuggets extraction and nuggets matching, linked to retrieval. This establishes a solid resource for advancing research in personalized conversational search and long-form answer generation. Our resources are publicly available at https://github.com/irlabamsterdam/CONE-RAG.
Reproducing NevIR: Negation in Neural Information Retrieval
Feb 19, 2025



Negation is a fundamental aspect of human communication, yet it remains a challenge for Language Models (LMs) in Information Retrieval (IR). Despite the heavy reliance of modern neural IR systems on LMs, little attention has been given to their handling of negation. In this study, we reproduce and extend the findings of NevIR, a benchmark study that revealed most IR models perform at or below the level of random ranking when dealing with negation. We replicate NevIR's original experiments and evaluate newly developed state-of-the-art IR models. Our findings show that a recently emerging category - listwise Large Language Model (LLM) rerankers - outperforms other models but still underperforms human performance. Additionally, we leverage ExcluIR, a benchmark dataset designed for exclusionary queries with extensive negation, to assess the generalizability of negation understanding. Our findings suggest that fine-tuning on one dataset does not reliably improve performance on the other, indicating notable differences in their data distributions. Furthermore, we observe that only cross-encoders and listwise LLM rerankers achieve reasonable performance across both negation tasks.
IRLab@iKAT24: Learned Sparse Retrieval with Multi-aspect LLM Query Generation for Conversational Search
Nov 22, 2024



The Interactive Knowledge Assistant Track (iKAT) 2024 focuses on advancing conversational assistants, able to adapt their interaction and responses from personalized user knowledge. The track incorporates a Personal Textual Knowledge Base (PTKB) alongside Conversational AI tasks, such as passage ranking and response generation. Query Rewrite being an effective approach for resolving conversational context, we explore Large Language Models (LLMs), as query rewriters. Specifically, our submitted runs explore multi-aspect query generation using the MQ4CS framework, which we further enhance with Learned Sparse Retrieval via the SPLADE architecture, coupled with robust cross-encoder models. We also propose an alternative to the previous interleaving strategy, aggregating multiple aspects during the reranking phase. Our findings indicate that multi-aspect query generation is effective in enhancing performance when integrated with advanced retrieval and reranking models. Our results also lead the way for better personalization in Conversational Search, relying on LLMs to integrate personalization within query rewrite, and outperforming human rewrite performance.
DiSCo Meets LLMs: A Unified Approach for Sparse Retrieval and Contextual Distillation in Conversational Search
Oct 18, 2024



Conversational Search (CS) is the task of retrieving relevant documents from a corpus within a conversational context, combining retrieval with conversational context modeling. With the explosion of Large Language Models (LLMs), the CS field has seen major improvements with LLMs rewriting user queries, accounting for conversational context. However, engaging LLMs at inference time harms efficiency. Current methods address this by distilling embeddings from human-rewritten queries to learn the context modeling task. Yet, these approaches predominantly focus on context modeling, and only treat the contrastive component of the retrieval task within a distillation-independent loss term. To address these limitations, we propose a new distillation method, as a relaxation of the previous objective, unifying retrieval and context modeling. We relax the existing training objectives by distilling similarity scores between conversations and documents, rather than relying solely on representation learning. Our proposed distillation objective allows for more freedom in the representation space and leverages the contrastive nature of document relevance. Through experiments on Learned Sparse Retrieval (LSR) across 5 CS datasets, our approach demonstrates substantial improvements in both in-domain and out-of-domain retrieval performance, outperforming state-of-the-art with gains of up to 6 points in recall for out-of-domain datasets. Additionally, through the relaxation of the objective, we propose a multi-teacher distillation, using multiple LLMs as teachers, yielding additional gains, and outperforming the teachers themselves in in-domain experiments. Finally, analysis of the sparsity of the models reveals that our distillation allows for better control over the sparsity of the trained models.
Benchmarking Middle-Trained Language Models for Neural Search
Jun 05, 2023Middle training methods aim to bridge the gap between the Masked Language Model (MLM) pre-training and the final finetuning for retrieval. Recent models such as CoCondenser, RetroMAE, and LexMAE argue that the MLM task is not sufficient enough to pre-train a transformer network for retrieval and hence propose various tasks to do so. Intrigued by those novel methods, we noticed that all these models used different finetuning protocols, making it hard to assess the benefits of middle training. We propose in this paper a benchmark of CoCondenser, RetroMAE, and LexMAE, under the same finetuning conditions. We compare both dense and sparse approaches under various finetuning protocols and middle training on different collections (MS MARCO, Wikipedia or Tripclick). We use additional middle training baselines, such as a standard MLM finetuning on the retrieval collection, optionally augmented by a CLS predicting the passage term frequency. For the sparse approach, our study reveals that there is almost no statistical difference between those methods: the more effective the finetuning procedure is, the less difference there is between those models. For the dense approach, RetroMAE using MS MARCO as middle-training collection shows excellent results in almost all the settings. Finally, we show that middle training on the retrieval collection, thus adapting the language model to it, is a critical factor. Overall, a better experimental setup should be adopted to evaluate middle training methods. Code available at https://github.com/naver/splade/tree/benchmarch-SIGIR23
A Static Pruning Study on Sparse Neural Retrievers
Apr 25, 2023Sparse neural retrievers, such as DeepImpact, uniCOIL and SPLADE, have been introduced recently as an efficient and effective way to perform retrieval with inverted indexes. They aim to learn term importance and, in some cases, document expansions, to provide a more effective document ranking compared to traditional bag-of-words retrieval models such as BM25. However, these sparse neural retrievers have been shown to increase the computational costs and latency of query processing compared to their classical counterparts. To mitigate this, we apply a well-known family of techniques for boosting the efficiency of query processing over inverted indexes: static pruning. We experiment with three static pruning strategies, namely document-centric, term-centric and agnostic pruning, and we assess, over diverse datasets, that these techniques still work with sparse neural retrievers. In particular, static pruning achieves $2\times$ speedup with negligible effectiveness loss ($\leq 2\%$ drop) and, depending on the use case, even $4\times$ speedup with minimal impact on the effectiveness ($\leq 8\%$ drop). Moreover, we show that neural rerankers are robust to candidates from statically pruned indexes.
A Study on FGSM Adversarial Training for Neural Retrieval
Jan 25, 2023


Neural retrieval models have acquired significant effectiveness gains over the last few years compared to term-based methods. Nevertheless, those models may be brittle when faced to typos, distribution shifts or vulnerable to malicious attacks. For instance, several recent papers demonstrated that such variations severely impacted models performances, and then tried to train more resilient models. Usual approaches include synonyms replacements or typos injections -- as data-augmentation -- and the use of more robust tokenizers (characterBERT, BPE-dropout). To further complement the literature, we investigate in this paper adversarial training as another possible solution to this robustness issue. Our comparison includes the two main families of BERT-based neural retrievers, i.e. dense and sparse, with and without distillation techniques. We then demonstrate that one of the most simple adversarial training techniques -- the Fast Gradient Sign Method (FGSM) -- can improve first stage rankers robustness and effectiveness. In particular, FGSM increases models performances on both in-domain and out-of-domain distributions, and also on queries with typos, for multiple neural retrievers.
Toward A Fine-Grained Analysis of Distribution Shifts in MSMARCO
May 05, 2022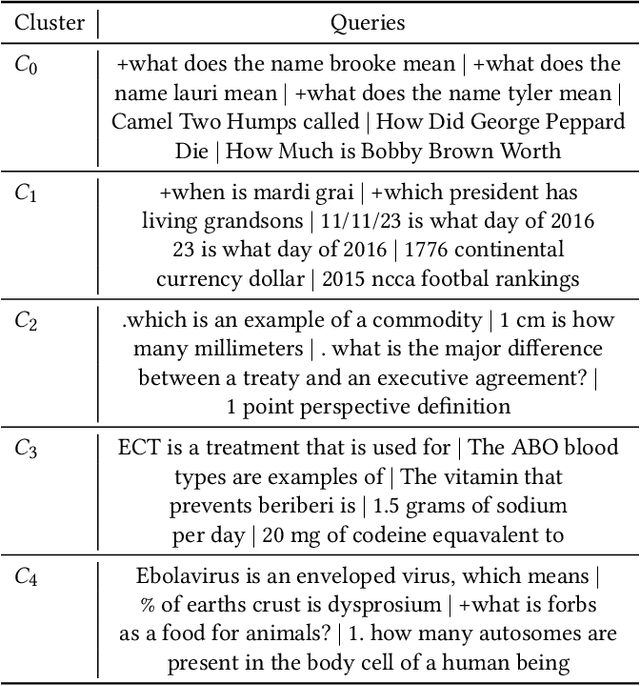
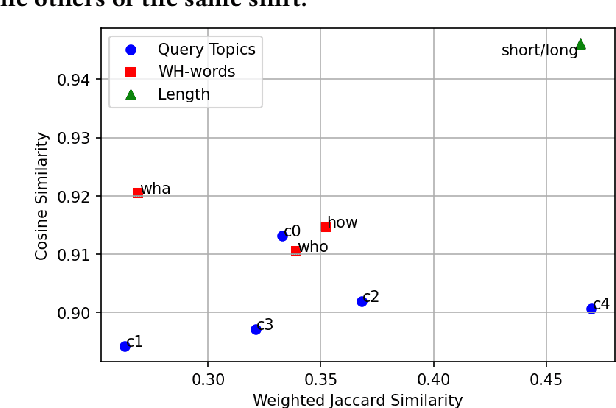
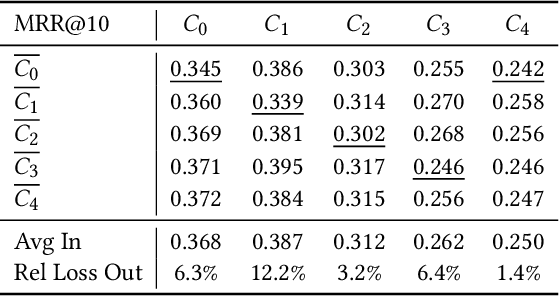
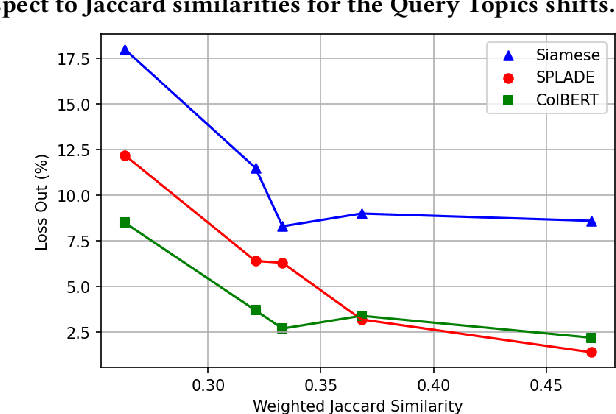
Recent IR approaches based on Pretrained Language Models (PLM) have now largely outperformed their predecessors on a variety of IR tasks. However, what happens to learned word representations with distribution shifts remains unclear. Recently, the BEIR benchmark was introduced to assess the performance of neural rankers in zero-shot settings and revealed deficiencies for several models. In complement to BEIR, we propose to control \textit{explicitly} distribution shifts. We selected different query subsets leading to different distribution shifts: short versus long queries, wh-words types of queries and 5 topic-based clusters. Then, we benchmarked state of the art neural rankers such as dense Bi-Encoder, SPLADE and ColBERT under these different training and test conditions. Our study demonstrates that it is possible to design distribution shift experiments within the MSMARCO collection, and that the query subsets we selected constitute an additional benchmark to better study factors of generalization for various models.
Zero-Shot and Few-Shot Classification of Biomedical Articles in Context of the COVID-19 Pandemic
Jan 11, 2022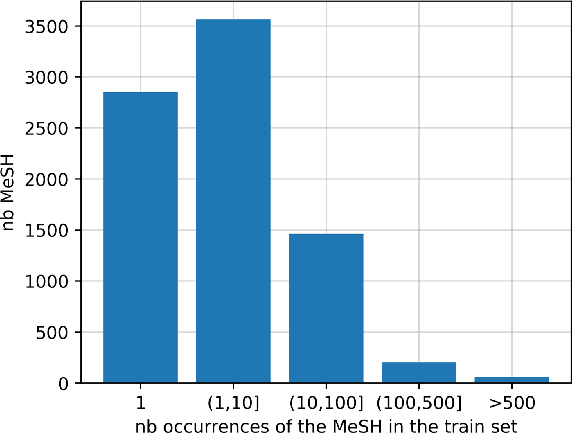
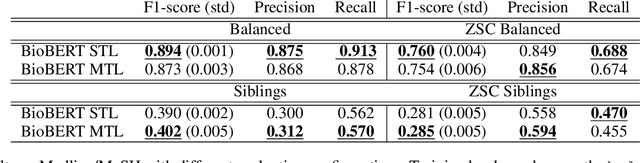
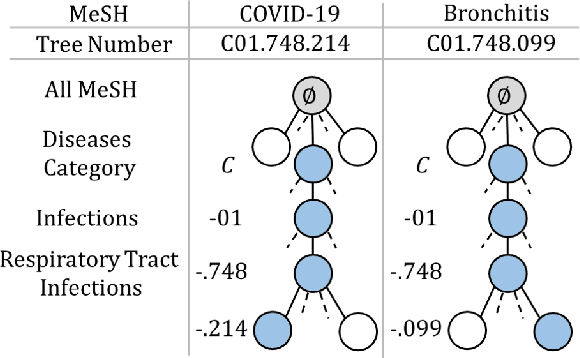
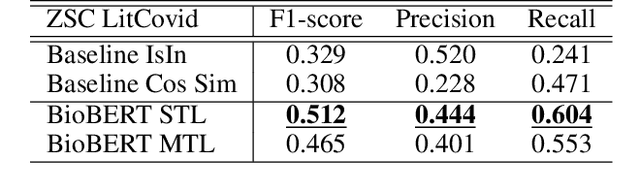
MeSH (Medical Subject Headings) is a large thesaurus created by the National Library of Medicine and used for fine-grained indexing of publications in the biomedical domain. In the context of the COVID-19 pandemic, MeSH descriptors have emerged in relation to articles published on the corresponding topic. Zero-shot classification is an adequate response for timely labeling of the stream of papers with MeSH categories. In this work, we hypothesise that rich semantic information available in MeSH has potential to improve BioBERT representations and make them more suitable for zero-shot/few-shot tasks. We frame the problem as determining if MeSH term definitions, concatenated with paper abstracts are valid instances or not, and leverage multi-task learning to induce the MeSH hierarchy in the representations thanks to a seq2seq task. Results establish a baseline on the MedLine and LitCovid datasets, and probing shows that the resulting representations convey the hierarchical relations present in MeSH.