 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Hyperspectral Imaging in Hardware via Trained Metasurface Encoders
Apr 05, 2022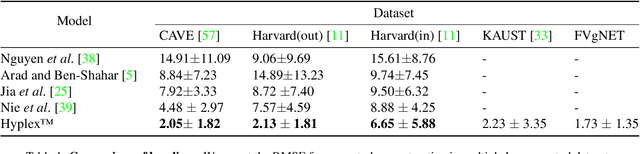

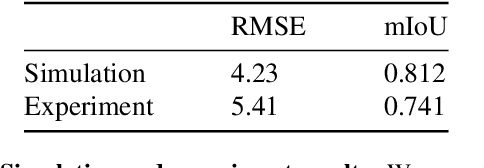
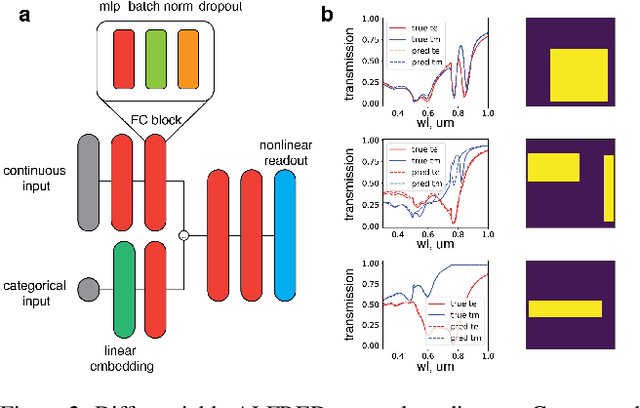
Hyperspectral imaging has attracted significant attention to identify spectral signatures for image classification and automated pattern recognition in computer vision. State-of-the-art implementations of snapshot hyperspectral imaging rely on bulky, non-integrated, and expensive optical elements, including lenses, spectrometers, and filters. These macroscopic components do not allow fast data processing for, e.g real-time and high-resolution videos. This work introduces Hyplex, a new integrated architecture addressing the limitations discussed above. Hyplex is a CMOS-compatible, fast hyperspectral camera that replaces bulk optics with nanoscale metasurfaces inversely designed through artificial intelligence. Hyplex does not require spectrometers but makes use of conventional monochrome cameras, opening up the possibility for real-time and high-resolution hyperspectral imaging at inexpensive costs. Hyplex exploits a model-driven optimization, which connects the physical metasurfaces layer with modern visual computing approaches based on end-to-end training. We design and implement a prototype version of Hyplex and compare its performance against the state-of-the-art for typical imaging tasks such as spectral reconstruction and semantic segmentation. In all benchmarks, Hyplex reports the smallest reconstruction error. We additionally present what is, to the best of our knowledge, the largest publicly available labeled hyperspectral dataset for semantic segmentation.
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
Dec 01, 2021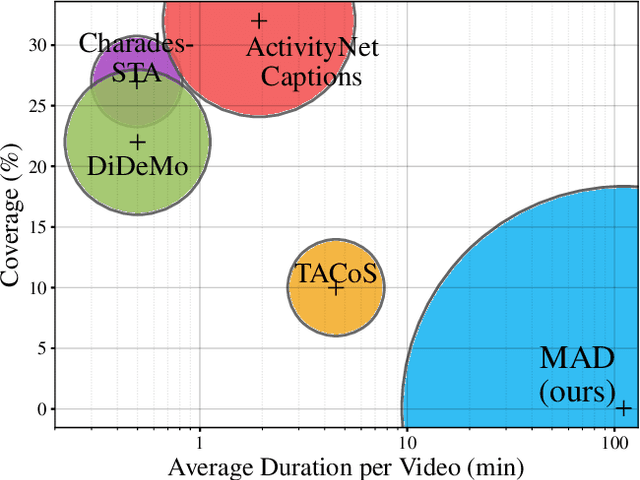
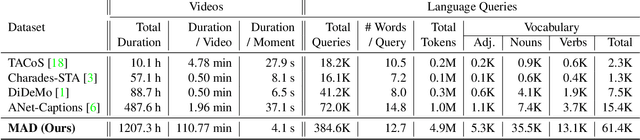


The recent and increasing interest in video-language research has driven the development of large-scale datasets that enable data-intensive machine learning techniques. In comparison, limited effort has been made at assessing the fitness of these datasets for the video-language grounding task. Recent works have begun to discover significant limitations in these datasets, suggesting that state-of-the-art techniques commonly overfit to hidden dataset biases. In this work, we present MAD (Movie Audio Descriptions), a novel benchmark that departs from the paradigm of augmenting existing video datasets with text annotations and focuses on crawling and aligning available audio descriptions of mainstream movies. MAD contains over 384,000 natural language sentences grounded in over 1,200 hours of video and exhibits a significant reduction in the currently diagnosed biases for video-language grounding datasets. MAD's collection strategy enables a novel and more challenging version of video-language grounding, where short temporal moments (typically seconds long) must be accurately grounded in diverse long-form videos that can last up to three hours.
Voint Cloud: Multi-View Point Cloud Representation for 3D Understanding
Nov 30, 2021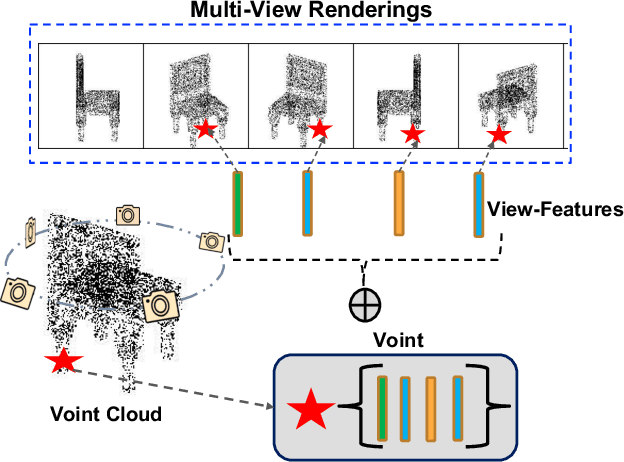
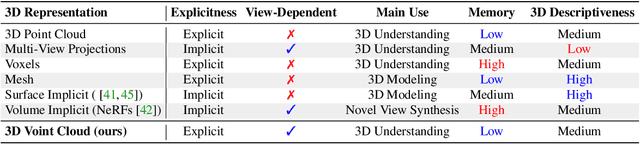
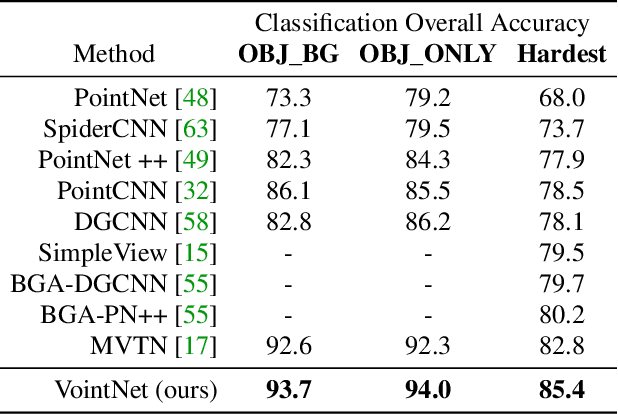
Multi-view projection methods have demonstrated promising performance on 3D understanding tasks like 3D classification and segmentation. However, it remains unclear how to combine such multi-view methods with the widely available 3D point clouds. Previous methods use unlearned heuristics to combine features at the point level. To this end, we introduce the concept of the multi-view point cloud (Voint cloud), representing each 3D point as a set of features extracted from several view-points. This novel 3D Voint cloud representation combines the compactness of 3D point cloud representation with the natural view-awareness of multi-view representation. Naturally, we can equip this new representation with convolutional and pooling operations. We deploy a Voint neural network (VointNet) with a theoretically established functional form to learn representations in the Voint space. Our novel representation achieves state-of-the-art performance on 3D classification and retrieval on ScanObjectNN, ModelNet40, and ShapeNet Core55. Additionally, we achieve competitive performance for 3D semantic segmentation on ShapeNet Parts. Further analysis shows that VointNet improves the robustness to rotation and occlusion compared to other methods.
SCTN: Sparse Convolution-Transformer Network for Scene Flow Estimation
Jun 02, 2021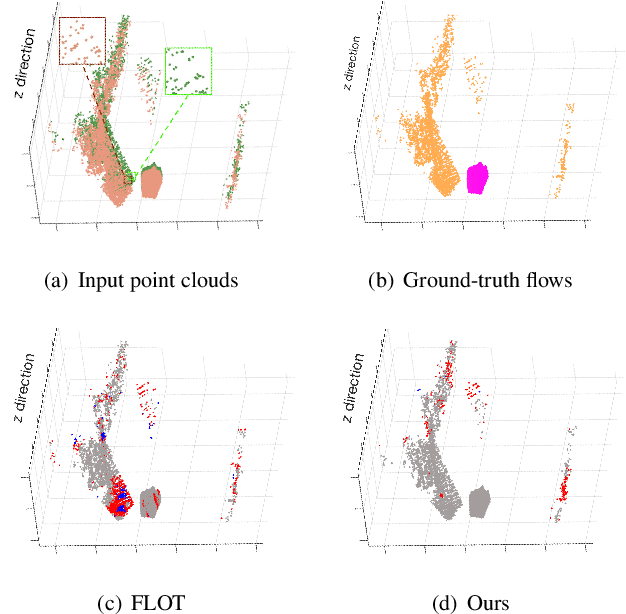
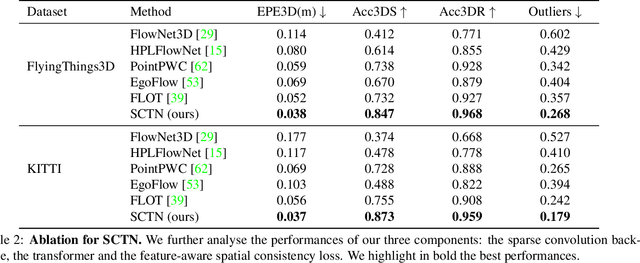
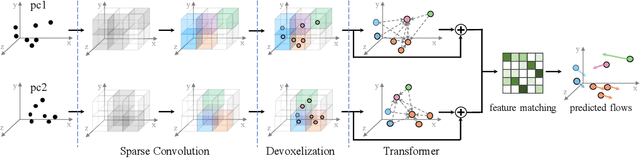
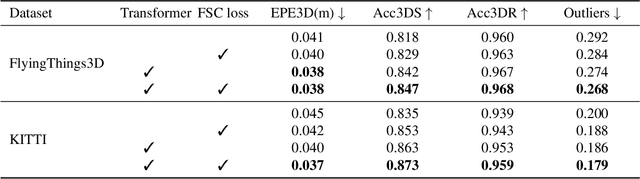
We propose a novel scene flow estimation approach to capture and infer 3D motions from point clouds. Estimating 3D motions for point clouds is challenging, since a point cloud is unordered and its density is significantly non-uniform. Such unstructured data poses difficulties in matching corresponding points between point clouds, leading to inaccurate flow estimation. We propose a novel architecture named Sparse Convolution-Transformer Network (SCTN) that equips the sparse convolution with the transformer. Specifically, by leveraging the sparse convolution, SCTN transfers irregular point cloud into locally consistent flow features for estimating continuous and consistent motions within an object/local object part. We further propose to explicitly learn point relations using a point transformer module, different from exiting methods. We show that the learned relation-based contextual information is rich and helpful for matching corresponding points, benefiting scene flow estimation. In addition, a novel loss function is proposed to adaptively encourage flow consistency according to feature similarity. Extensive experiments demonstrate that our proposed approach achieves a new state of the art in scene flow estimation. Our approach achieves an error of 0.038 and 0.037 (EPE3D) on FlyingThings3D and KITTI Scene Flow respectively, which significantly outperforms previous methods by large margins.
Camera Calibration and Player Localization in SoccerNet-v2 and Investigation of their Representations for Action Spotting
Apr 19, 2021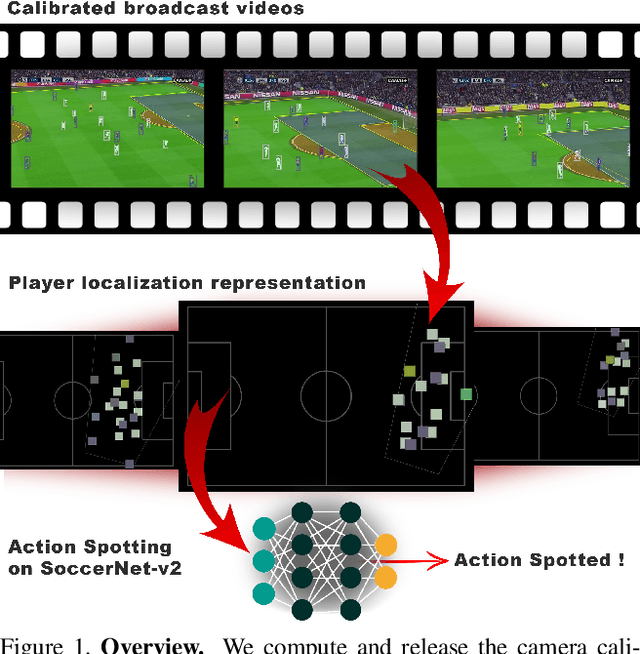
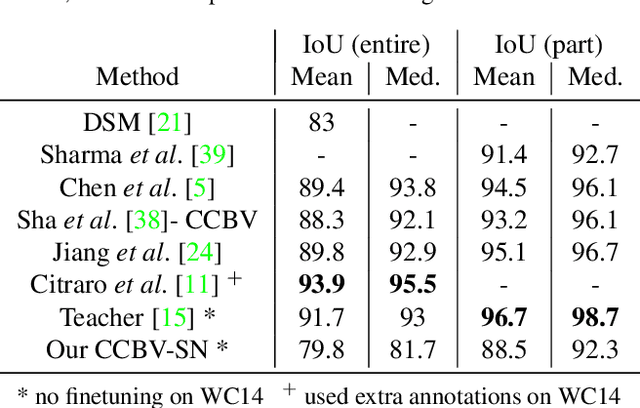
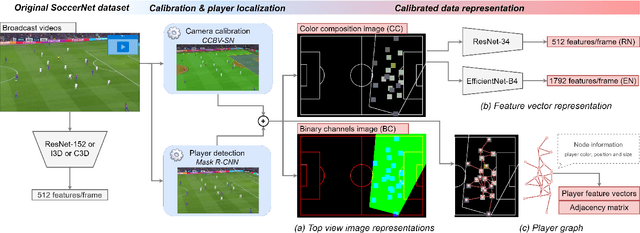
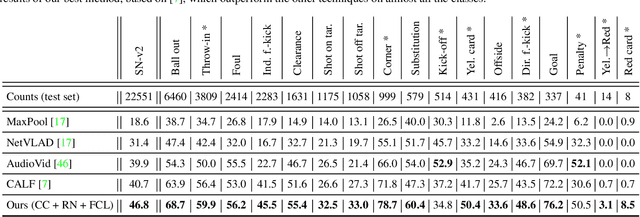
Soccer broadcast video understanding has been drawing a lot of attention in recent years within data scientists and industrial companies. This is mainly due to the lucrative potential unlocked by effective deep learning techniques developed in the field of computer vision. In this work, we focus on the topic of camera calibration and on its current limitations for the scientific community. More precisely, we tackle the absence of a large-scale calibration dataset and of a public calibration network trained on such a dataset. Specifically, we distill a powerful commercial calibration tool in a recent neural network architecture on the large-scale SoccerNet dataset, composed of untrimmed broadcast videos of 500 soccer games. We further release our distilled network, and leverage it to provide 3 ways of representing the calibration results along with player localization. Finally, we exploit those representations within the current best architecture for the action spotting task of SoccerNet-v2, and achieve new state-of-the-art performances.
Temporally-Aware Feature Pooling for Action Spotting in Soccer Broadcasts
Apr 14, 2021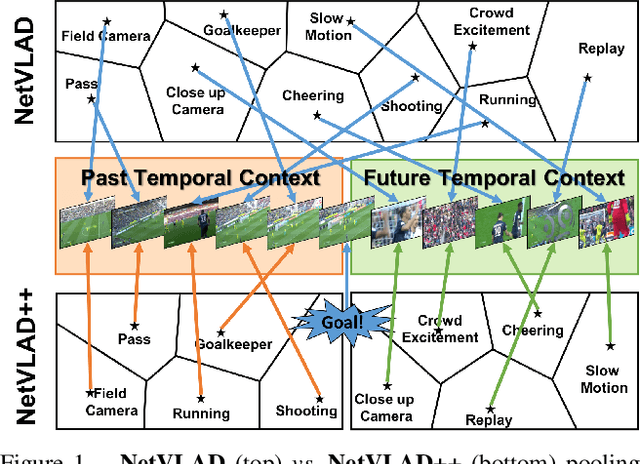

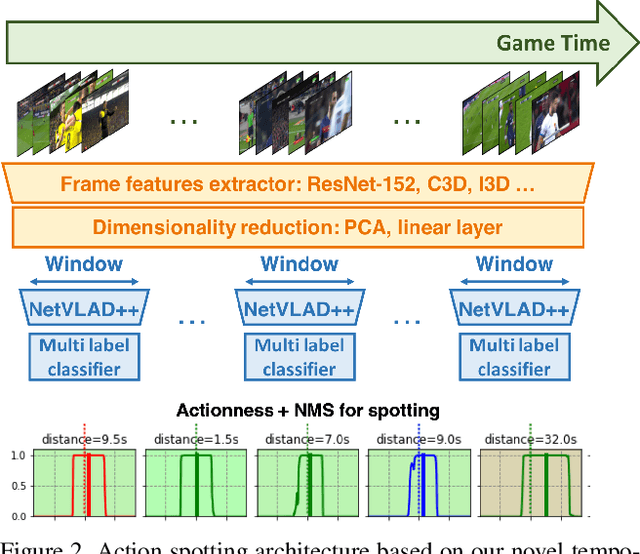
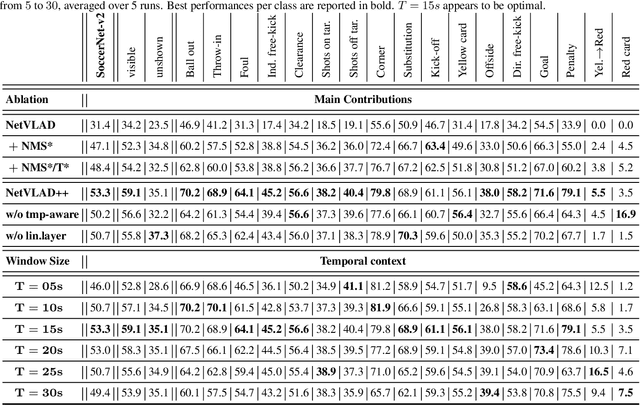
Toward the goal of automatic production for sports broadcasts, a paramount task consists in understanding the high-level semantic information of the game in play. For instance, recognizing and localizing the main actions of the game would allow producers to adapt and automatize the broadcast production, focusing on the important details of the game and maximizing the spectator engagement. In this paper, we focus our analysis on action spotting in soccer broadcast, which consists in temporally localizing the main actions in a soccer game. To that end, we propose a novel feature pooling method based on NetVLAD, dubbed NetVLAD++, that embeds temporally-aware knowledge. Different from previous pooling methods that consider the temporal context as a single set to pool from, we split the context before and after an action occurs. We argue that considering the contextual information around the action spot as a single entity leads to a sub-optimal learning for the pooling module. With NetVLAD++, we disentangle the context from the past and future frames and learn specific vocabularies of semantics for each subsets, avoiding to blend and blur such vocabulary in time. Injecting such prior knowledge creates more informative pooling modules and more discriminative pooled features, leading into a better understanding of the actions. We train and evaluate our methodology on the recent large-scale dataset SoccerNet-v2, reaching 53.4% Average-mAP for action spotting, a +12.7% improvement w.r.t the current state-of-the-art.
SALA: Soft Assignment Local Aggregation for 3D Semantic Segmentation
Dec 29, 2020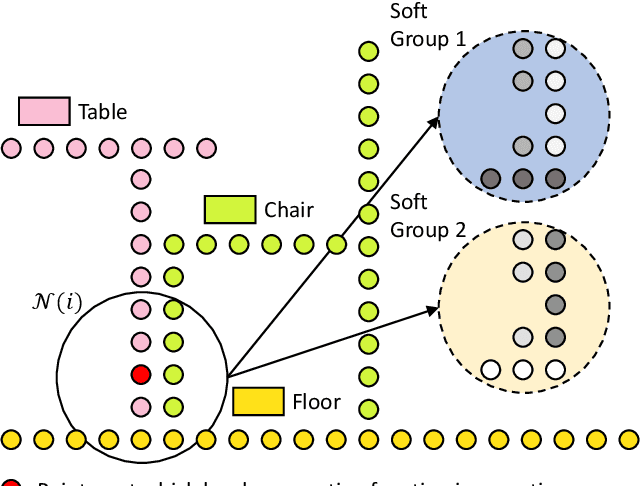
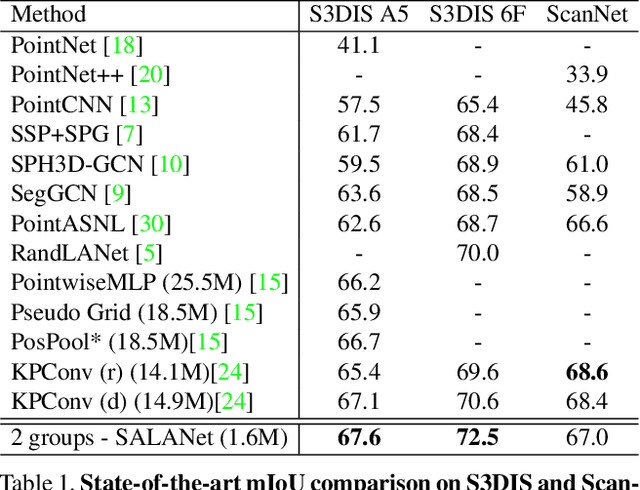
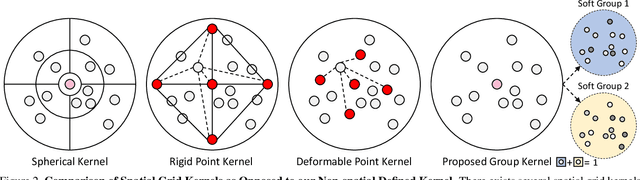
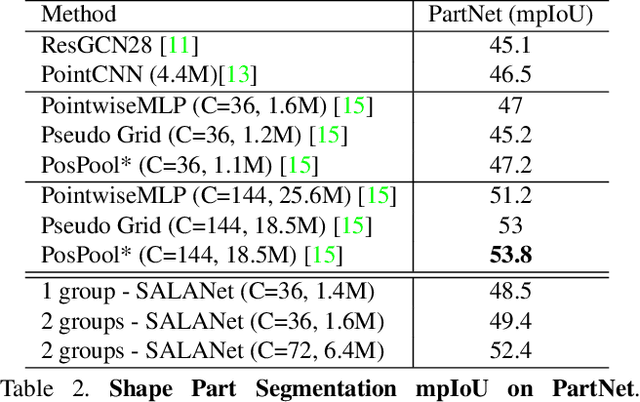
We introduce the idea of using learnable neighbor-to-grid soft assignment in grid-based aggregation functions for the task of 3D semantic segmentation. Previous methods in literature operate on a predefined geometric grid such as local volume partitions or irregular kernel points. These methods use geometric functions to assign local neighbors to their corresponding grid. Such geometric heuristics are potentially sub-optimal for the end task of semantic segmentation. Furthermore, they are applied uniformly throughout the depth of the network. A more general alternative would allow the network to learn its own neighbor-to-grid assignment function that best suits the end task. Since it is learnable, this mapping has the flexibility to be different per layer. This paper leverages learned neighbor-to-grid soft assignment to define an aggregation function that balances efficiency and performance. We demonstrate the efficacy of our method by reaching state-of-the-art (SOTA) performance on S3DIS with almost 10$\times$ less parameters than the current reigning method. We also demonstrate competitive performance on ScanNet and PartNet as compared with much larger SOTA models.
SoccerNet-v2 : A Dataset and Benchmarks for Holistic Understanding of Broadcast Soccer Videos
Nov 26, 2020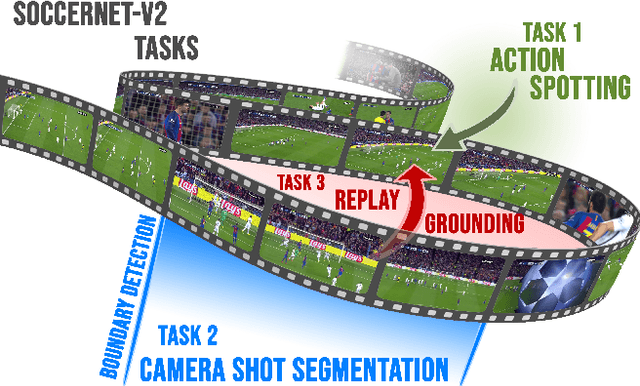
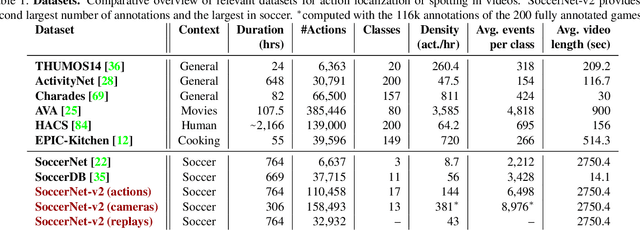
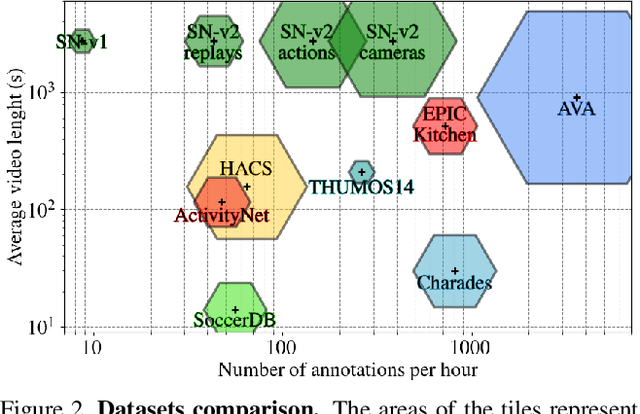
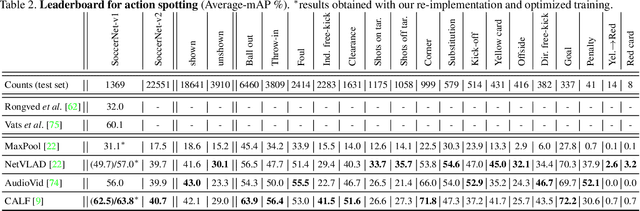
Understanding broadcast videos is a challenging task in computer vision, as it requires generic reasoning capabilities to appreciate the content offered by the video editing. In this work, we propose SoccerNet-v2, a novel large-scale corpus of manual annotations for the SoccerNet video dataset, along with open challenges to encourage more research in soccer understanding and broadcast production. Specifically, we release around 300k annotations within SoccerNet's 500 untrimmed broadcast soccer videos. We extend current tasks in the realm of soccer to include action spotting, camera shot segmentation with boundary detection, and we define a novel replay grounding task. For each task, we provide and discuss benchmark results, reproducible with our open-source adapted implementations of the most relevant works in the field. SoccerNet-v2 is presented to the broader research community to help push computer vision closer to automatic solutions for more general video understanding and production purposes.
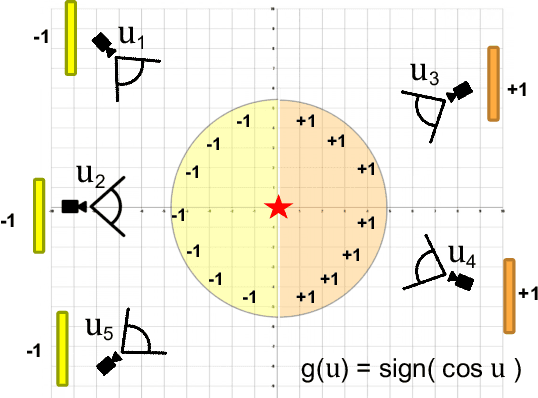
MVTN: Multi-View Transformation Network for 3D Shape Recognition
Nov 26, 2020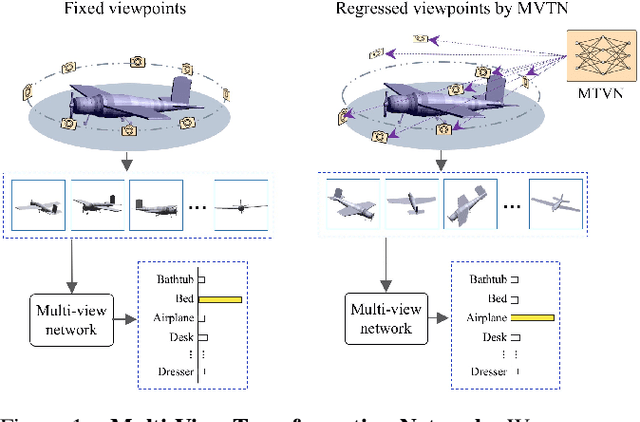
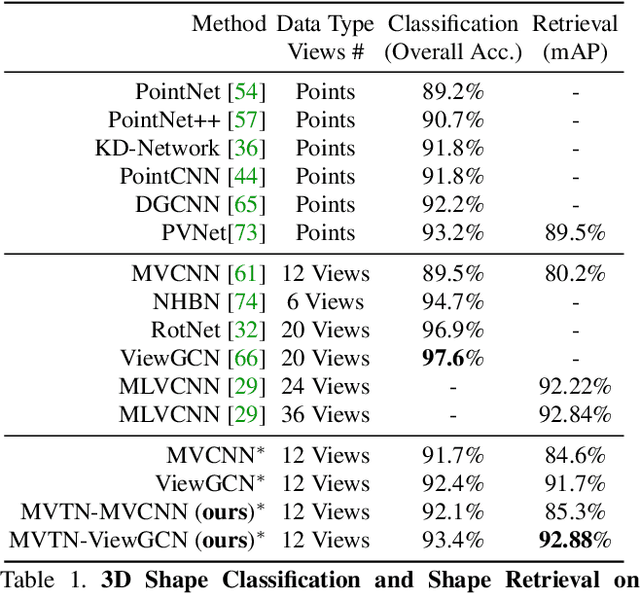
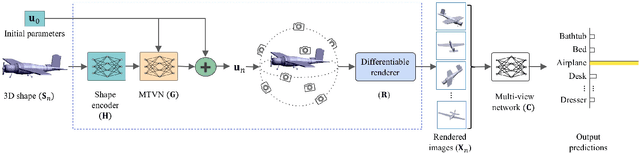
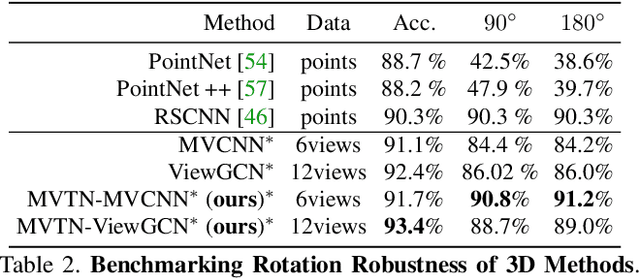
Multi-view projection methods have shown the capability to reach state-of-the-art performance on 3D shape recognition. Most advances in multi-view representation focus on pooling techniques that learn to aggregate information from the different views, which tend to be heuristically set and fixed for all shapes. To circumvent the lack of dynamism of current multi-view methods, we propose to learn those viewpoints. In particular, we introduce a Multi-View Transformation Network (MVTN) that regresses optimal viewpoints for 3D shape recognition. By leveraging advances in differentiable rendering, our MVTN is trained end-to-end with any multi-view network and optimized for 3D shape classification. We show that MVTN can be seamlessly integrated into various multi-view approaches to exhibit clear performance gains in the tasks of 3D shape classification and shape retrieval without any extra training supervision. Furthermore, our MVTN improves multi-view networks to achieve state-of-the-art performance in rotation robustness and in object shape retrieval on ModelNet40.
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
Nov 23, 2020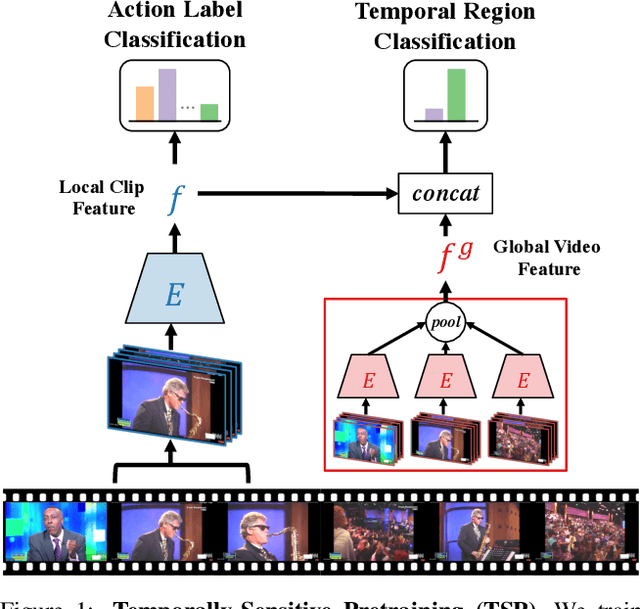


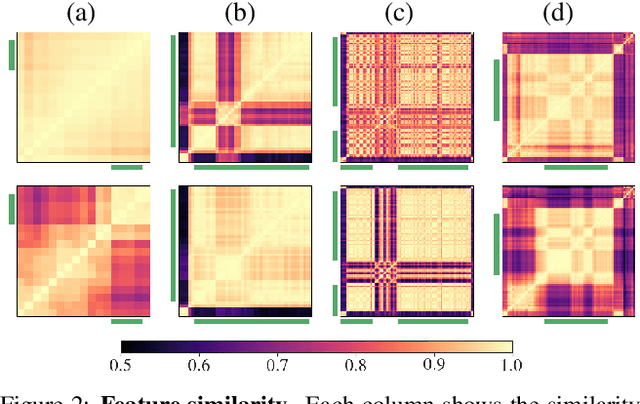
Understanding videos is challenging in computer vision. In particular, the large memory footprint of an untrimmed video makes most tasks infeasible to train end-to-end without dropping part of the input data. To cope with the memory limitation of commodity GPUs, current video localization models encode videos in an offline fashion. Even though these encoders are learned, they are typically trained for action classification tasks at the frame- or clip-level. Since it is difficult to finetune these encoders for other video tasks, they might be sub-optimal for temporal localization tasks. In this work, we propose a novel, supervised pretraining paradigm for clip-level video representation that does not only train to classify activities, but also considers background clips and global video information to gain temporal sensitivity. Extensive experiments show that features extracted by clip-level encoders trained with our novel pretraining task are more discriminative for several temporal localization tasks. Specifically, we show that using our newly trained features with state-of-the-art methods significantly improves performance on three tasks: Temporal Action Localization (+1.72% in average mAP on ActivityNet and +4.4% in mAP@0.5 on THUMOS14), Action Proposal Generation (+1.94% in AUC on ActivityNet), and Dense Video Captioning (+0.31% in average METEOR on ActivityNet Captions). We believe video feature encoding is an important building block for many video algorithms, and extracting meaningful features should be of paramount importance in the effort to build more accurate models.