 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Multitask Learning with Factorized Diffusion Policy
Dec 26, 2025Multitask learning poses significant challenges due to the highly multimodal and diverse nature of robot action distributions. However, effectively fitting policies to these complex task distributions is often difficult, and existing monolithic models often underfit the action distribution and lack the flexibility required for efficient adaptation. We introduce a novel modular diffusion policy framework that factorizes complex action distributions into a composition of specialized diffusion models, each capturing a distinct sub-mode of the behavior space for a more effective overall policy. In addition, this modular structure enables flexible policy adaptation to new tasks by adding or fine-tuning components, which inherently mitigates catastrophic forgetting. Empirically, across both simulation and real-world robotic manipulation settings, we illustrate how our method consistently outperforms strong modular and monolithic baselines.
TEDi Policy: Temporally Entangled Diffusion for Robotic Control
Jun 07, 2024
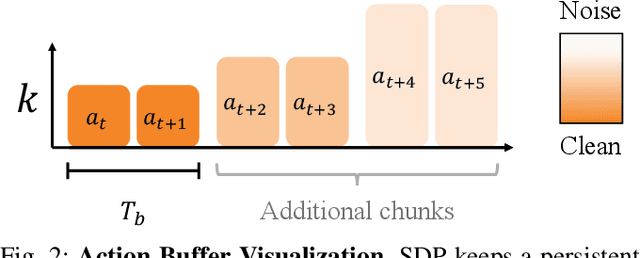
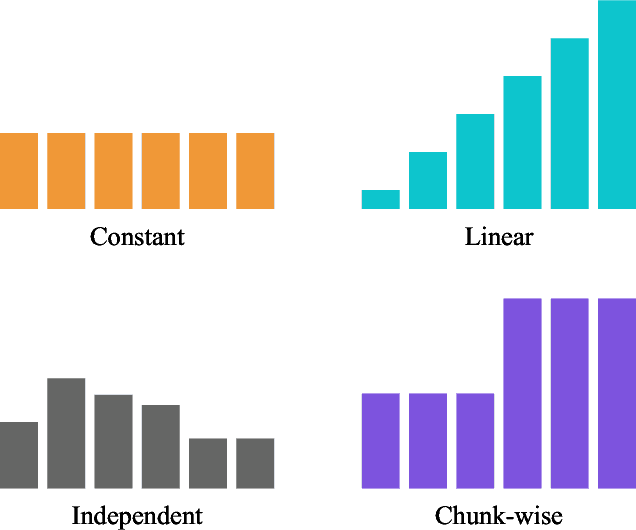
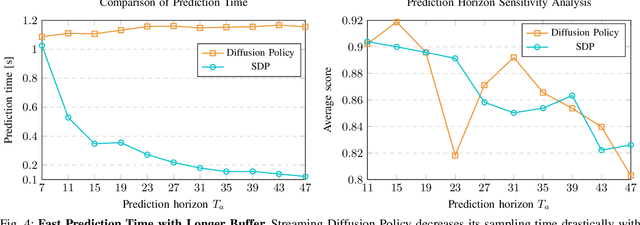
Diffusion models have been shown to excel in robotic imitation learning by mastering the challenge of modeling complex distributions. However, sampling speed has traditionally not been a priority due to their popularity for image generation, limiting their application to dynamical tasks. While recent work has improved the sampling speed of diffusion-based robotic policies, they are restricted to techniques from the image generation domain. We adapt Temporally Entangled Diffusion (TEDi), a framework specific for trajectory generation, to speed up diffusion-based policies for imitation learning. We introduce TEDi Policy, with novel regimes for training and sampling, and show that it drastically improves the sampling speed while remaining performant when applied to state-of-the-art diffusion-based imitation learning policies.