 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIPHER: Cryptographic Insecurity Profiling via Hybrid Evaluation of Responses
Feb 01, 2026Large language models (LLMs) are increasingly used to assist developers with code, yet their implementations of cryptographic functionality often contain exploitable flaws. Minor design choices (e.g., static initialization vectors or missing authentication) can silently invalidate security guarantees. We introduce CIPHER(\textbf{C}ryptographic \textbf{I}nsecurity \textbf{P}rofiling via \textbf{H}ybrid \textbf{E}valuation of \textbf{R}esponses), a benchmark for measuring cryptographic vulnerability incidence in LLM-generated Python code under controlled security-guidance conditions. CIPHER uses insecure/neutral/secure prompt variants per task, a cryptography-specific vulnerability taxonomy, and line-level attribution via an automated scoring pipeline. Across a diverse set of widely used LLMs, we find that explicit ``secure'' prompting reduces some targeted issues but does not reliably eliminate cryptographic vulnerabilities overall. The benchmark and reproducible scoring pipeline will be publicly released upon publication.
ReGal: A First Look at PPO-based Legal AI for Judgment Prediction and Summarization in India
Dec 19, 2025This paper presents an early exploration of reinforcement learning methodologies for legal AI in the Indian context. We introduce Reinforcement Learning-based Legal Reasoning (ReGal), a framework that integrates Multi-Task Instruction Tuning with Reinforcement Learning from AI Feedback (RLAIF) using Proximal Policy Optimization (PPO). Our approach is evaluated across two critical legal tasks: (i) Court Judgment Prediction and Explanation (CJPE), and (ii) Legal Document Summarization. Although the framework underperforms on standard evaluation metrics compared to supervised and proprietary models, it provides valuable insights into the challenges of applying RL to legal texts. These challenges include reward model alignment, legal language complexity, and domain-specific adaptation. Through empirical and qualitative analysis, we demonstrate how RL can be repurposed for high-stakes, long-document tasks in law. Our findings establish a foundation for future work on optimizing legal reasoning pipelines using reinforcement learning, with broader implications for building interpretable and adaptive legal AI systems.
SELF-PERCEPT: Introspection Improves Large Language Models' Detection of Multi-Person Mental Manipulation in Conversations
May 27, 2025



Mental manipulation is a subtle yet pervasive form of abuse in interpersonal communication, making its detection critical for safeguarding potential victims. However, due to manipulation's nuanced and context-specific nature, identifying manipulative language in complex, multi-turn, and multi-person conversations remains a significant challenge for large language models (LLMs). To address this gap, we introduce the MultiManip dataset, comprising 220 multi-turn, multi-person dialogues balanced between manipulative and non-manipulative interactions, all drawn from reality shows that mimic real-world scenarios. For manipulative interactions, it includes 11 distinct manipulations depicting real-life scenarios. We conduct extensive evaluations of state-of-the-art LLMs, such as GPT-4o and Llama-3.1-8B, employing various prompting strategies. Despite their capabilities, these models often struggle to detect manipulation effectively. To overcome this limitation, we propose SELF-PERCEPT, a novel, two-stage prompting framework inspired by Self-Perception Theory, demonstrating strong performance in detecting multi-person, multi-turn mental manipulation. Our code and data are publicly available at https://github.com/danushkhanna/self-percept .
Unsupervised paradigm for information extraction from transcripts using BERT
Oct 09, 2021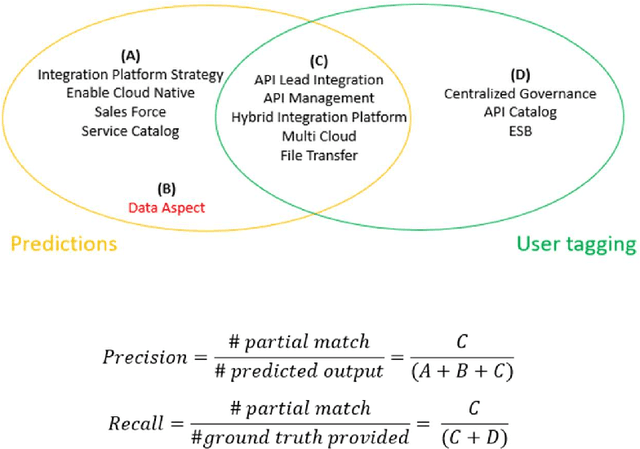
Audio call transcripts are one of the valuable sources of information for multiple downstream use cases such as understanding the voice of the customer and analyzing agent performance. However, these transcripts are noisy in nature and in an industry setting, getting tagged ground truth data is a challenge. In this paper, we present a solution implemented in the industry using BERT Language Models as part of our pipeline to extract key topics and multiple open intents discussed in the call. Another problem statement we looked at was the automatic tagging of transcripts into predefined categories, which traditionally is solved using supervised approach. To overcome the lack of tagged data, all our proposed approaches use unsupervised methods to solve the outlined problems. We evaluate the results by quantitatively comparing the automatically extracted topics, intents and tagged categories with human tagged ground truth and by qualitatively measuring the valuable concepts and intents that are not present in the ground truth. We achieved near human accuracy in extraction of these topics and intents using our novel approach