 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseScout: Algorithm-System Co-design for Budgeted Tiny Object Selection on Edge Platforms
Apr 28, 2026Deploying tiny object perception on edge platforms is challenging because practical systems must satisfy both strict compute budgets and end-to-end latency constraints. A common strategy is to first select a small number of candidate patches from a high-resolution image and then apply downstream processing only to the selected regions. However, existing detector-based frontends are not well aligned with this setting: strong offline detection accuracy does not necessarily yield effective low-budget patch prioritization, nor does it guarantee usable performance once transport and inference delays are considered. In this work, we study budgeted tiny object selection on edge platforms from a joint algorithm--system perspective. We present DenseScout, a lightweight dense-response selector with only 1.01M parameters, which directly ranks candidate patch locations from a high-resolution scene via a lightweight proxy input and is better aligned with low-budget tiny-object prioritization than detector-style frontends. To bridge offline selector quality and deployable utility, we further develop a transport-aware runtime realization on heterogeneous edge devices and adopt QoS-constrained recall, which counts a target as successfully perceived only if it is covered by the selected regions and the end-to-end processing finishes before the deadline. Experiments show that DenseScout consistently outperforms detector-based baselines in offline budgeted patch-selection evaluation, especially in low-budget regimes, while cross-platform results on RK3588 and Jetson Orin NX show that deployable performance depends jointly on selector quality and runtime realization efficiency. These results suggest that edge tiny object perception should be optimized as an algorithm--system co-design problem rather than as isolated model selection.
Curricular Subgoals for Inverse Reinforcement Learning
Jun 14, 2023



Inverse Reinforcement Learning (IRL) aims to reconstruct the reward function from expert demonstrations to facilitate policy learning, and has demonstrated its remarkable success in imitation learning. To promote expert-like behavior, existing IRL methods mainly focus on learning global reward functions to minimize the trajectory difference between the imitator and the expert. However, these global designs are still limited by the redundant noise and error propagation problems, leading to the unsuitable reward assignment and thus downgrading the agent capability in complex multi-stage tasks. In this paper, we propose a novel Curricular Subgoal-based Inverse Reinforcement Learning (CSIRL) framework, that explicitly disentangles one task with several local subgoals to guide agent imitation. Specifically, CSIRL firstly introduces decision uncertainty of the trained agent over expert trajectories to dynamically select subgoals, which directly determines the exploration boundary of different task stages. To further acquire local reward functions for each stage, we customize a meta-imitation objective based on these curricular subgoals to train an intrinsic reward generator. Experiments on the D4RL and autonomous driving benchmarks demonstrate that the proposed methods yields results superior to the state-of-the-art counterparts, as well as better interpretability. Our code is available at https://github.com/Plankson/CSIRL.
Neural network state estimation for full quantum state tomography
Nov 19, 2018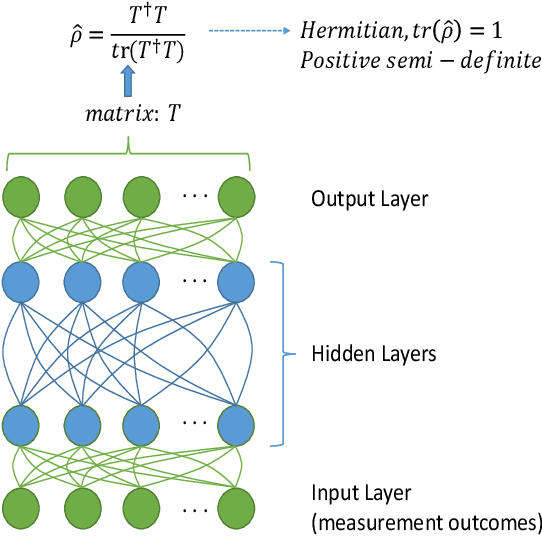
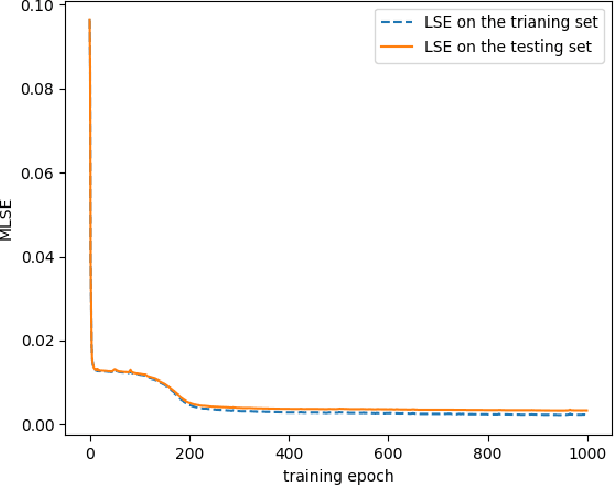
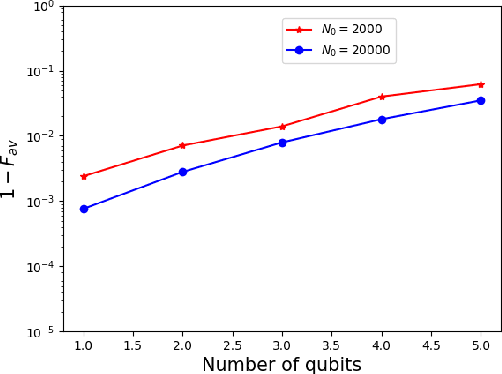
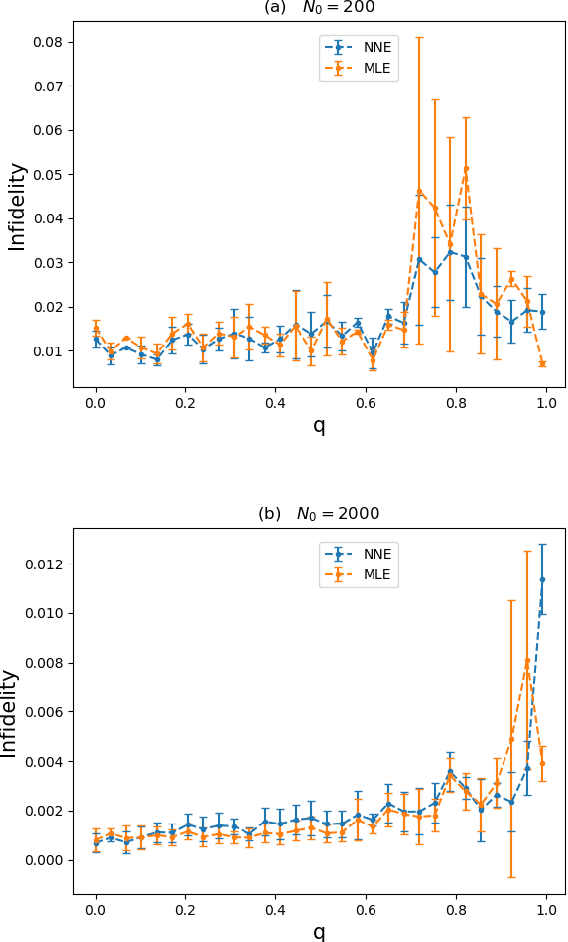
An efficient state estimation model, neural network estimation (NNE), empowered by machine learning techniques, is presented for full quantum state tomography (FQST). A parameterized function based on neural network is applied to map the measurement outcomes to the estimated quantum states. Parameters are updated with supervised learning procedures. From the computational complexity perspective our algorithm is the most efficient one among existing state estimation algorithms for full quantum state tomography. We perform numerical tests to prove both the accuracy and scalability of our model.