 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGS: Hierarchical Generative Scene Framework for Multi-Step Associative Semantic Spatial Composition
Oct 31, 2025Three-dimensional scene generation holds significant potential in gaming, film, and virtual reality. However, most existing methods adopt a single-step generation process, making it difficult to balance scene complexity with minimal user input. Inspired by the human cognitive process in scene modeling, which progresses from global to local, focuses on key elements, and completes the scene through semantic association, we propose HiGS, a hierarchical generative framework for multi-step associative semantic spatial composition. HiGS enables users to iteratively expand scenes by selecting key semantic objects, offering fine-grained control over regions of interest while the model completes peripheral areas automatically. To support structured and coherent generation, we introduce the Progressive Hierarchical Spatial-Semantic Graph (PHiSSG), which dynamically organizes spatial relationships and semantic dependencies across the evolving scene structure. PHiSSG ensures spatial and geometric consistency throughout the generation process by maintaining a one-to-one mapping between graph nodes and generated objects and supporting recursive layout optimization. Experiments demonstrate that HiGS outperforms single-stage methods in layout plausibility, style consistency, and user preference, offering a controllable and extensible paradigm for efficient 3D scene construction.
Auto-Conditioned Recurrent Networks for Extended Complex Human Motion Synthesis
Jul 09, 2018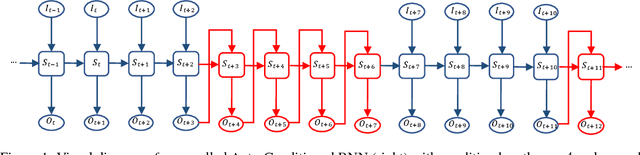
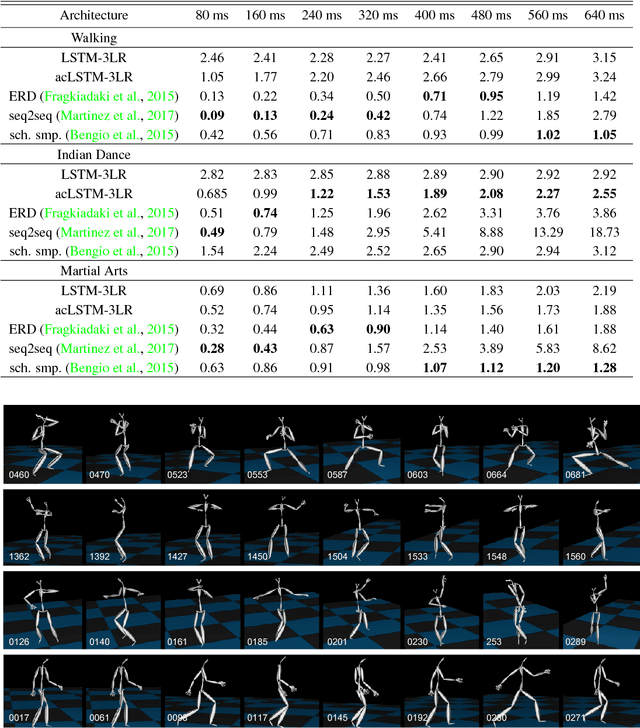
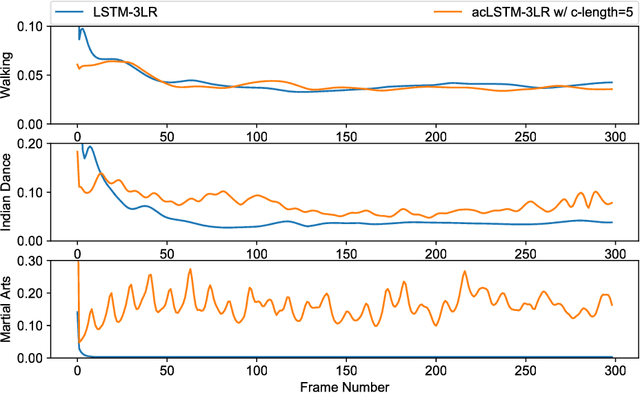
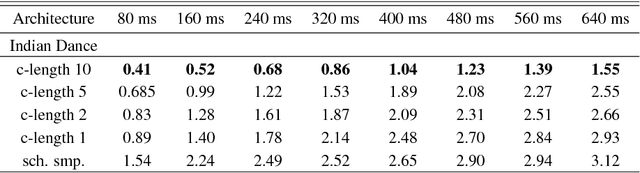
We present a real-time method for synthesizing highly complex human motions using a novel training regime we call the auto-conditioned Recurrent Neural Network (acRNN). Recently, researchers have attempted to synthesize new motion by using autoregressive techniques, but existing methods tend to freeze or diverge after a couple of seconds due to an accumulation of errors that are fed back into the network. Furthermore, such methods have only been shown to be reliable for relatively simple human motions, such as walking or running. In contrast, our approach can synthesize arbitrary motions with highly complex styles, including dances or martial arts in addition to locomotion. The acRNN is able to accomplish this by explicitly accommodating for autoregressive noise accumulation during training. Our work is the first to our knowledge that demonstrates the ability to generate over 18,000 continuous frames (300 seconds) of new complex human motion w.r.t. different styles.