 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOilSAM2: Memory-Augmented SAM2 for Scalable SAR Oil Spill Detection
Mar 10, 2026Segmenting oil spills from Synthetic Aperture Radar (SAR) imagery remains challenging due to severe appearance variability, scale heterogeneity, and the absence of temporal continuity in real world monitoring scenarios. While foundation models such as Segment Anything (SAM) enable prompt driven segmentation, existing SAM based approaches operate on single images and cannot effectively reuse information across scenes. Memory augmented variants (e.g., SAM2) further assume temporal coherence, making them prone to semantic drift when applied to unordered SAR image collections. We propose OilSAM2, a memory augmented segmentation framework tailored for unordered SAR oil spill monitoring. OilSAM2 introduces a hierarchical feature aware multi scale memory bank that explicitly models texture, structure, and semantic level representations, enabling robust cross image information reuse. To mitigate memory drift, we further propose a structure semantic consistent memory update strategy that selectively refreshes memory based on semantic discrepancy and structural variation.Experiments on two public SAR oil spill datasets demonstrate that OilSAM2 achieves state of the art segmentation performance, delivering stable and accurate results under noisy SAR monitoring scenarios. The source code is available at https://github.com/Chenshuaiyu1120/OILSAM2.
Beyond Segmentation: An Oil Spill Change Detection Framework Using Synthetic SAR Imagery
Jan 05, 2026Marine oil spills are urgent environmental hazards that demand rapid and reliable detection to minimise ecological and economic damage. While Synthetic Aperture Radar (SAR) imagery has become a key tool for large-scale oil spill monitoring, most existing detection methods rely on deep learning-based segmentation applied to single SAR images. These static approaches struggle to distinguish true oil spills from visually similar oceanic features (e.g., biogenic slicks or low-wind zones), leading to high false positive rates and limited generalizability, especially under data-scarce conditions. To overcome these limitations, we introduce Oil Spill Change Detection (OSCD), a new bi-temporal task that focuses on identifying changes between pre- and post-spill SAR images. As real co-registered pre-spill imagery is not always available, we propose the Temporal-Aware Hybrid Inpainting (TAHI) framework, which generates synthetic pre-spill images from post-spill SAR data. TAHI integrates two key components: High-Fidelity Hybrid Inpainting for oil-free reconstruction, and Temporal Realism Enhancement for radiometric and sea-state consistency. Using TAHI, we construct the first OSCD dataset and benchmark several state-of-the-art change detection models. Results show that OSCD significantly reduces false positives and improves detection accuracy compared to conventional segmentation, demonstrating the value of temporally-aware methods for reliable, scalable oil spill monitoring in real-world scenarios.
Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest Overfitting
Sep 14, 2022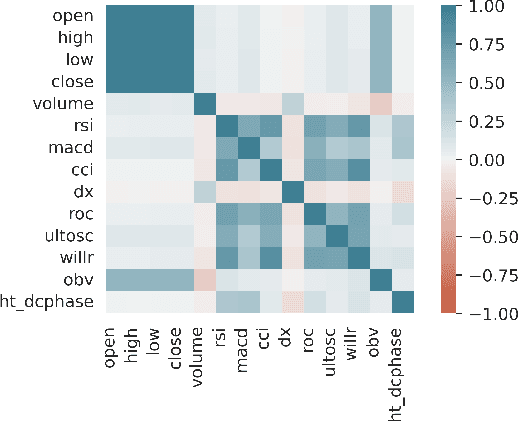
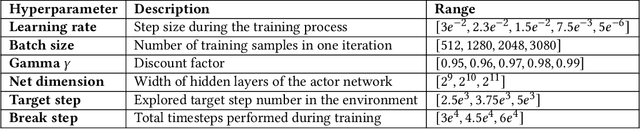
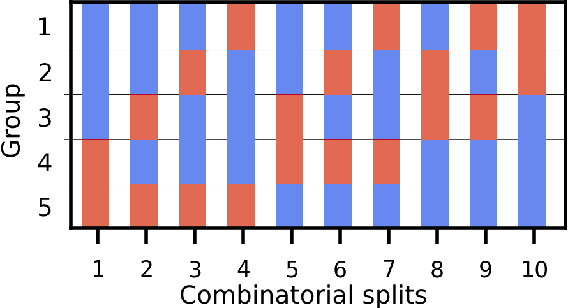
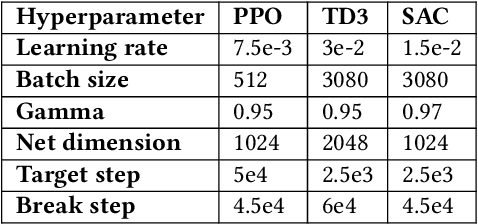
Designing profitable and reliable trading strategies is challenging in the highly volatile cryptocurrency market. Existing works applied deep reinforcement learning methods and optimistically reported increased profits in backtesting, which may suffer from the false positive issue due to overfitting. In this paper, we propose a practical approach to address backtest overfitting for cryptocurrency trading using deep reinforcement learning. First, we formulate the detection of backtest overfitting as a hypothesis test. Then, we train the DRL agents, estimate the probability of overfitting, and reject the overfitted agents, increasing the chance of good trading performance. Finally, on 10 cryptocurrencies over a testing period from 05/01/2022 to 06/27/2022 (during which the crypto market crashed two times), we show that the less overfitted deep reinforcement learning agents have a higher Sharpe ratio than that of more over-fitted agents, an equal weight strategy, and the S&P DBM Index (market benchmark), offering confidence in possible deployment to a real market.