 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic-to-Word Recognition with Sequence-to-Sequence Models
Aug 21, 2018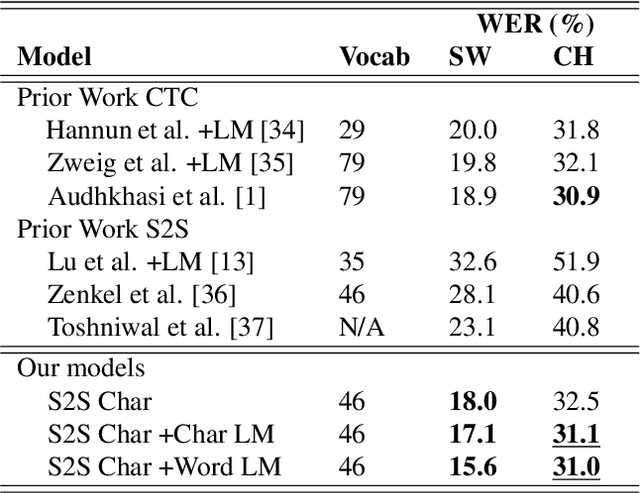
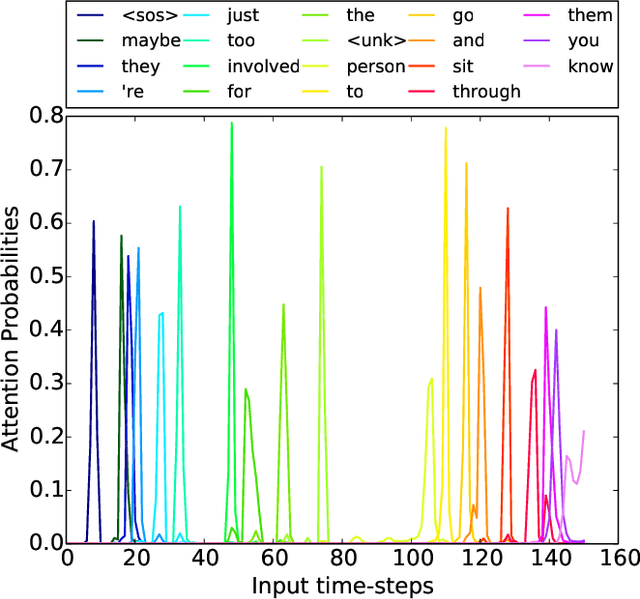
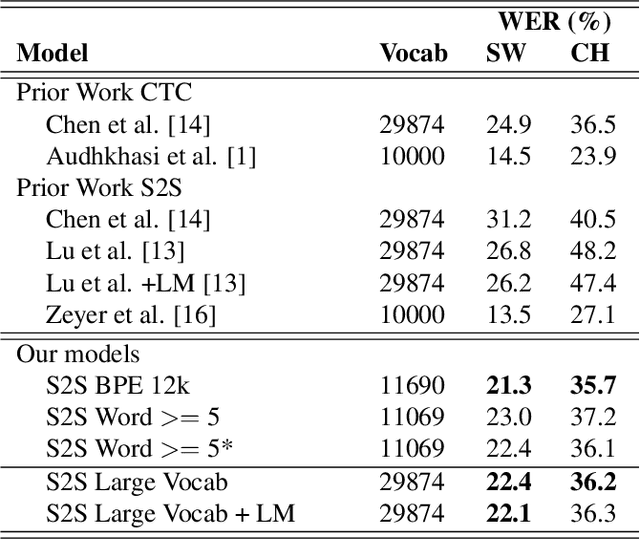
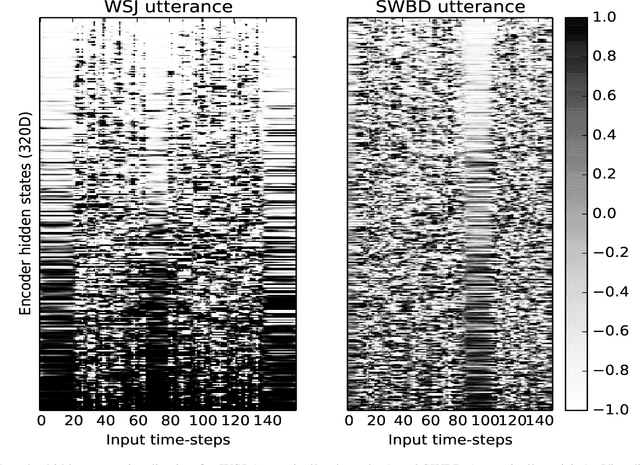
Acoustic-to-Word recognition provides a straightforward solution to end-to-end speech recognition without needing external decoding, language model re-scoring or lexicon. While character-based models offer a natural solution to the out-of-vocabulary problem, word models can be simpler to decode and may also be able to directly recognize semantically meaningful units. We present effective methods to train Sequence-to-Sequence models for direct word-level recognition (and character-level recognition) and show an absolute improvement of 4.4-5.0\% in Word Error Rate on the Switchboard corpus compared to prior work. In addition to these promising results, word-based models are more interpretable than character models, which have to be composed into words using a separate decoding step. We analyze the encoder hidden states and the attention behavior, and show that location-aware attention naturally represents words as a single speech-word-vector, despite spanning multiple frames in the input. We finally show that the Acoustic-to-Word model also learns to segment speech into words with a mean standard deviation of 3 frames as compared with human annotated forced-alignments for the Switchboard corpus.
End-to-End Multimodal Speech Recognition
Apr 25, 2018
Transcription or sub-titling of open-domain videos is still a challenging domain for Automatic Speech Recognition (ASR) due to the data's challenging acoustics, variable signal processing and the essentially unrestricted domain of the data. In previous work, we have shown that the visual channel -- specifically object and scene features -- can help to adapt the acoustic model (AM) and language model (LM) of a recognizer, and we are now expanding this work to end-to-end approaches. In the case of a Connectionist Temporal Classification (CTC)-based approach, we retain the separation of AM and LM, while for a sequence-to-sequence (S2S) approach, both information sources are adapted together, in a single model. This paper also analyzes the behavior of CTC and S2S models on noisy video data (How-To corpus), and compares it to results on the clean Wall Street Journal (WSJ) corpus, providing insight into the robustness of both approaches.
Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the "Speaking Rosetta" JSALT 2017 Workshop
Feb 14, 2018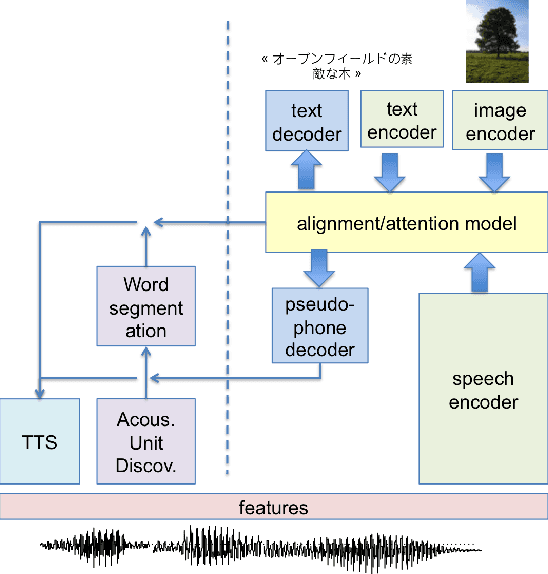

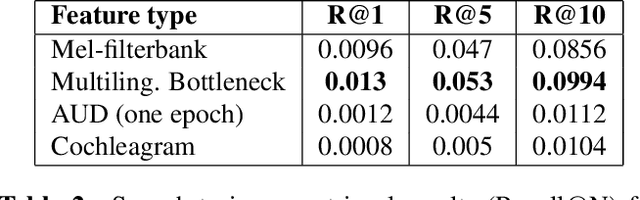
We summarize the accomplishments of a multi-disciplinary workshop exploring the computational and scientific issues surrounding the discovery of linguistic units (subwords and words) in a language without orthography. We study the replacement of orthographic transcriptions by images and/or translated text in a well-resourced language to help unsupervised discovery from raw speech.
Combining LSTM and Latent Topic Modeling for Mortality Prediction
Sep 08, 2017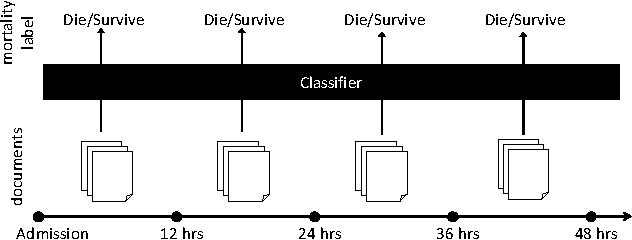

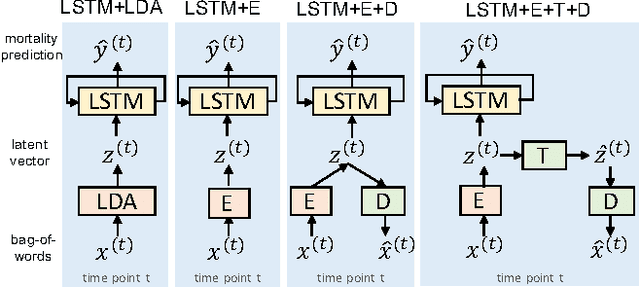

There is a great need for technologies that can predict the mortality of patients in intensive care units with both high accuracy and accountability. We present joint end-to-end neural network architectures that combine long short-term memory (LSTM) and a latent topic model to simultaneously train a classifier for mortality prediction and learn latent topics indicative of mortality from textual clinical notes. For topic interpretability, the topic modeling layer has been carefully designed as a single-layer network with constraints inspired by LDA. Experiments on the MIMIC-III dataset show that our models significantly outperform prior models that are based on LDA topics in mortality prediction. However, we achieve limited success with our method for interpreting topics from the trained models by looking at the neural network weights.