 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Domain Emotion Recognition using Few Shot Knowledge Transfer
Oct 11, 2021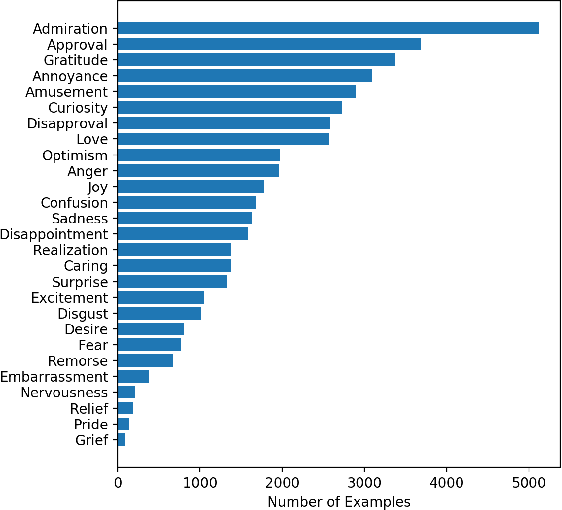
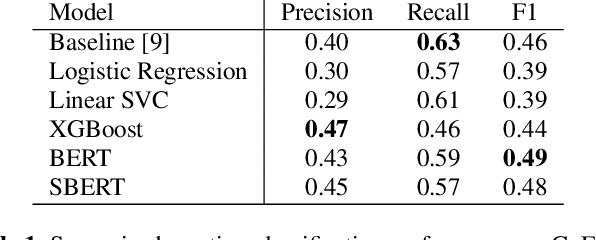
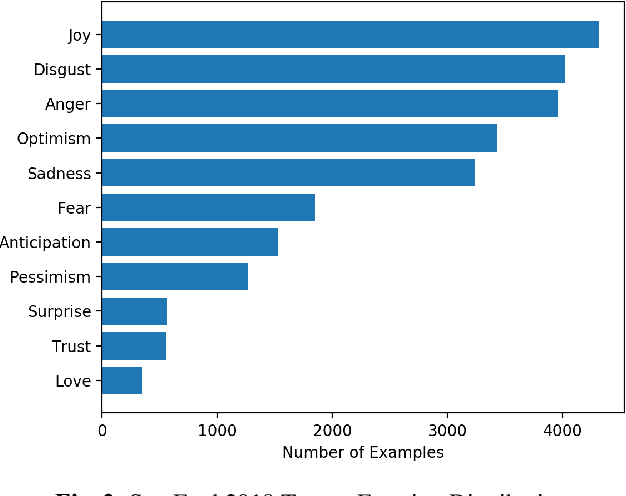
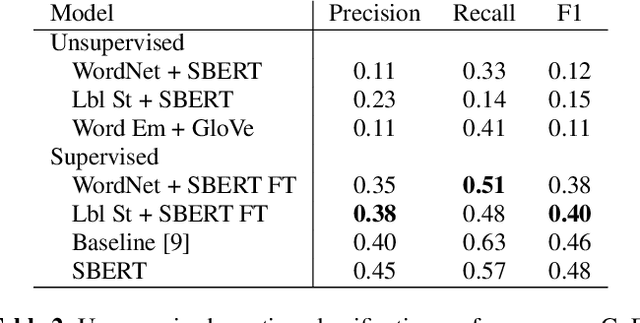
Emotion recognition from text is a challenging task due to diverse emotion taxonomies, lack of reliable labeled data in different domains, and highly subjective annotation standards. Few-shot and zero-shot techniques can generalize across unseen emotions by projecting the documents and emotion labels onto a shared embedding space. In this work, we explore the task of few-shot emotion recognition by transferring the knowledge gained from supervision on the GoEmotions Reddit dataset to the SemEval tweets corpus, using different emotion representation methods. The results show that knowledge transfer using external knowledge bases and fine-tuned encoders perform comparably as supervised baselines, requiring minimal supervision from the task dataset.
Phone Duration Modeling for Speaker Age Estimation in Children
Sep 03, 2021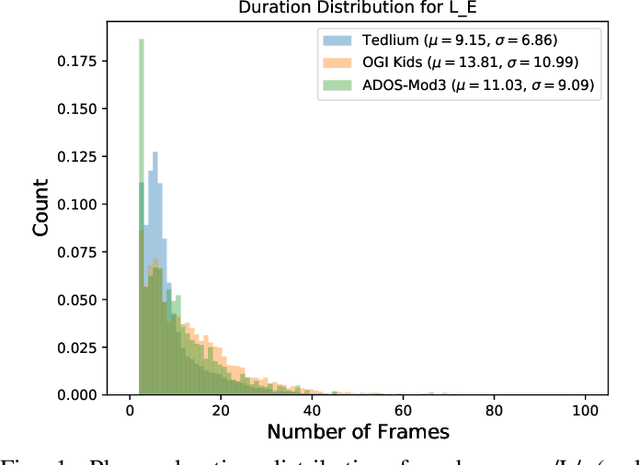
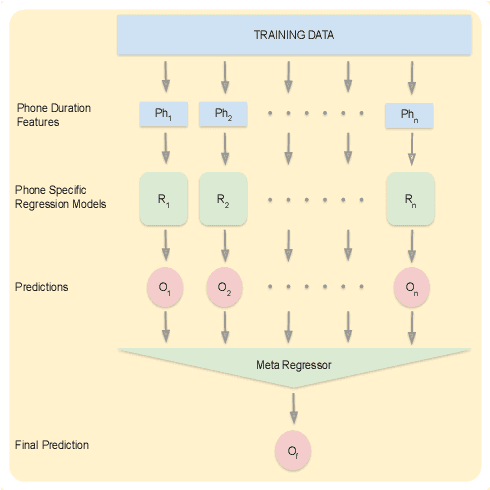
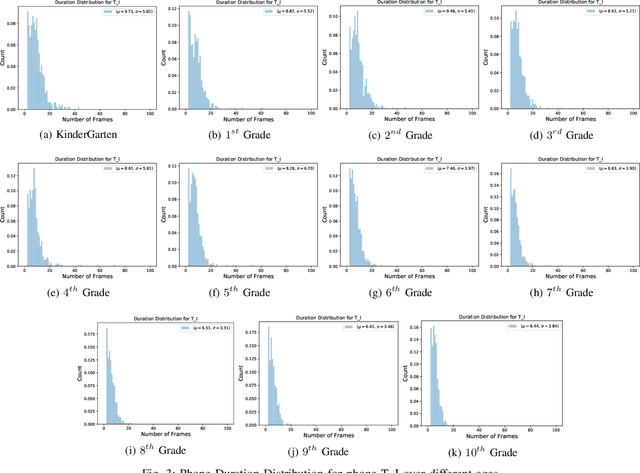
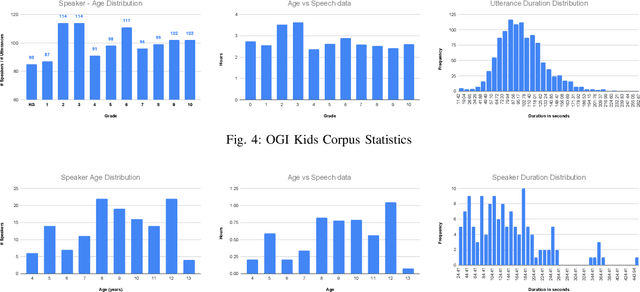
Automatic inference of important paralinguistic information such as age from speech is an important area of research with numerous spoken language technology based applications. Speaker age estimation has applications in enabling personalization and age-appropriate curation of information and content. However, research in speaker age estimation in children is especially challenging due to paucity of relevant speech data representing the developmental spectrum, and the high signal variability especially intra age variability that complicates modeling. Most approaches in children speaker age estimation adopt methods directly from research on adult speech processing. In this paper, we propose features specific to children and focus on speaker's phone duration as an important biomarker of children's age. We propose phone duration modeling for predicting age from child's speech. To enable that, children speech is first forced aligned with the corresponding transcription to derive phone duration distributions. Statistical functionals are computed from phone duration distributions for each phoneme which are in turn used to train regression models to predict speaker age. Two children speech datasets are employed to demonstrate the robustness of phone duration features. We perform age regression experiments on age categories ranging from children studying in kindergarten to grade 10. Experimental results suggest phone durations contain important development-related information of children. Phonemes contributing most to estimation of children speaker age are analyzed and presented.
Perceptual-based deep-learning denoiser as a defense against adversarial attacks on ASR systems
Jul 12, 2021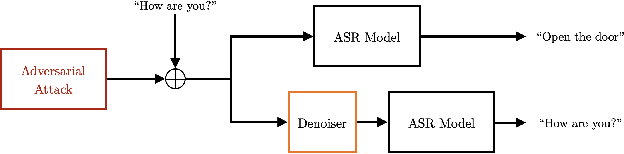
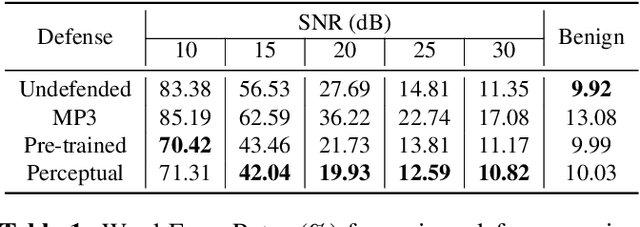
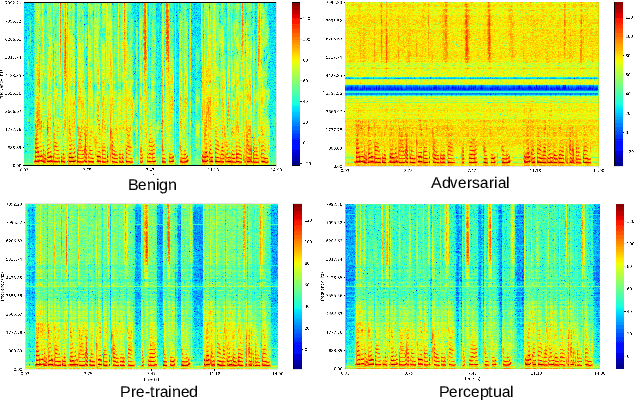
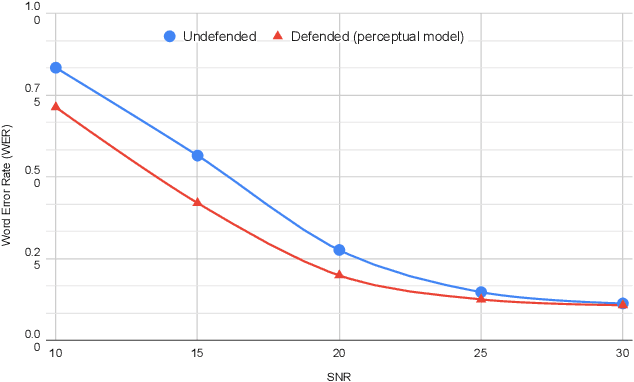
In this paper we investigate speech denoising as a defense against adversarial attacks on automatic speech recognition (ASR) systems. Adversarial attacks attempt to force misclassification by adding small perturbations to the original speech signal. We propose to counteract this by employing a neural-network based denoiser as a pre-processor in the ASR pipeline. The denoiser is independent of the downstream ASR model, and thus can be rapidly deployed in existing systems. We found that training the denoisier using a perceptually motivated loss function resulted in increased adversarial robustness without compromising ASR performance on benign samples. Our defense was evaluated (as a part of the DARPA GARD program) on the 'Kenansville' attack strategy across a range of attack strengths and speech samples. An average improvement in Word Error Rate (WER) of about 7.7% was observed over the undefended model at 20 dB signal-to-noise-ratio (SNR) attack strength.
An Automated Quality Evaluation Framework of Psychotherapy Conversations with Local Quality Estimates
Jun 15, 2021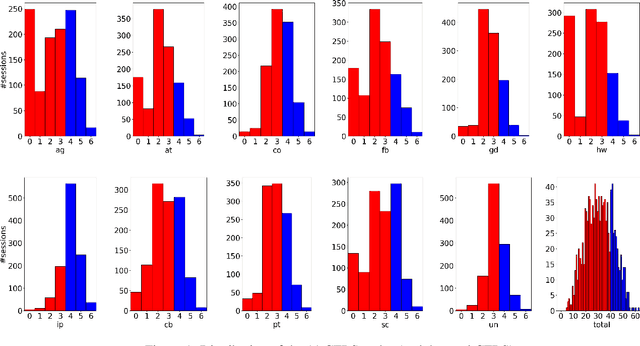
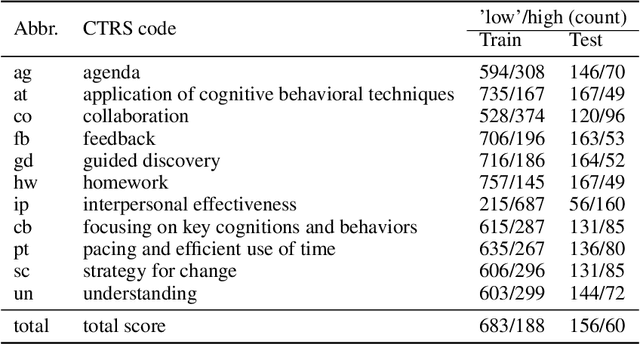

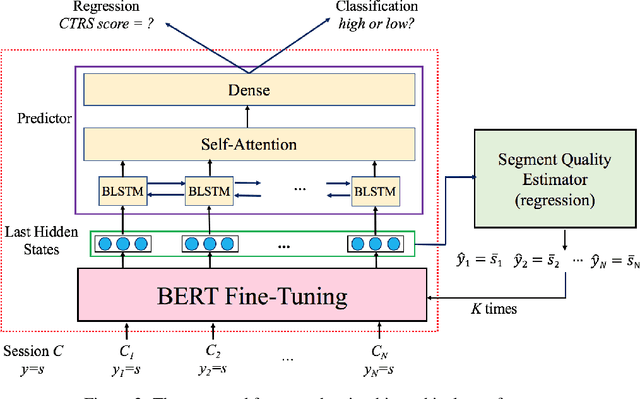
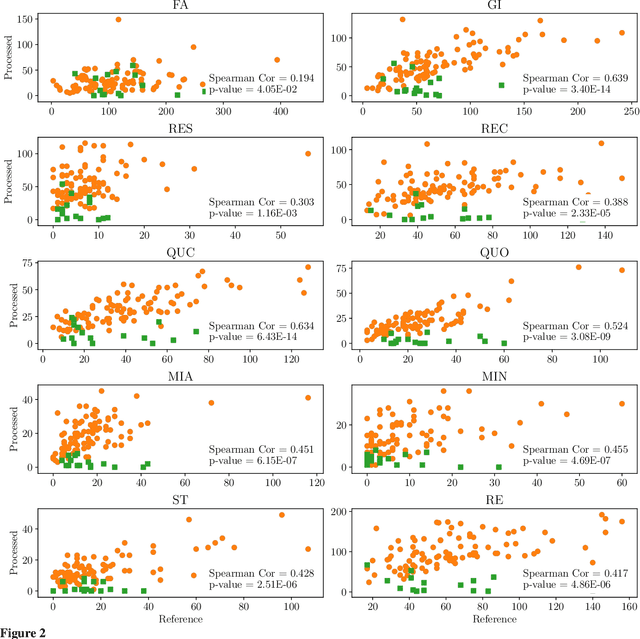
Computational approaches for assessing the quality of conversation-based psychotherapy, such as Cognitive Behavioral Therapy (CBT) and Motivational Interviewing (MI), have been developed recently to support quality assurance and clinical training. However, due to the long session lengths and limited modeling resources, computational methods largely rely on frequency-based lexical features or distribution of dialogue acts. In this work, we propose a hierarchical framework to automatically evaluate the quality of a CBT interaction. We divide each psychotherapy session into conversation segments and input those into a BERT-based model to produce segment embeddings. We first fine-tune BERT for predicting segment-level (local) quality scores and then use segment embeddings as lower-level input to a Bidirectional LSTM-based neural network to predict session-level (global) quality estimates. In particular, the segment-level quality scores are initialized with the session-level scores and we model the global quality as a function of the local quality scores to achieve the accurate segment-level quality estimates. These estimated segment-level scores benefit theBERT fine-tuning and in learning better segment embeddings. We evaluate the proposed framework on data drawn from real-world CBT clinical session recordings to predict multiple session-level behavior codes. The results indicate that our approach leads to improved evaluation accuracy for most codes in both regression and classification tasks.
Acted vs. Improvised: Domain Adaptation for Elicitation Approaches in Audio-Visual Emotion Recognition
Apr 05, 2021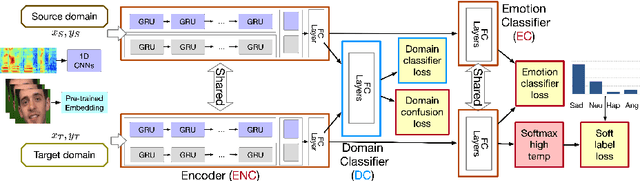
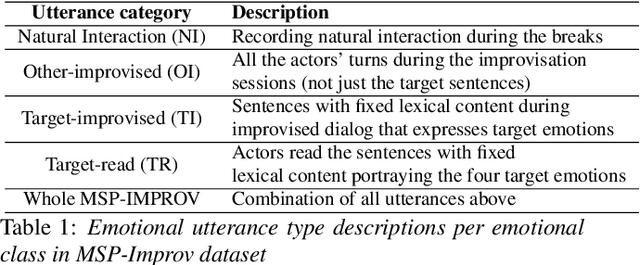
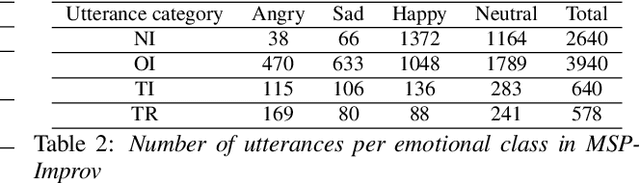
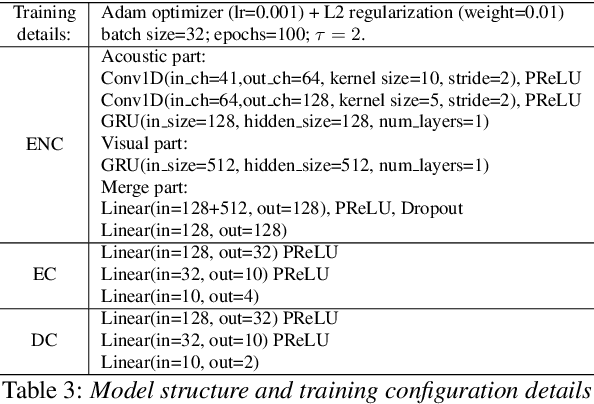
Key challenges in developing generalized automatic emotion recognition systems include scarcity of labeled data and lack of gold-standard references. Even for the cues that are labeled as the same emotion category, the variability of associated expressions can be high depending on the elicitation context e.g., emotion elicited during improvised conversations vs. acted sessions with predefined scripts. In this work, we regard the emotion elicitation approach as domain knowledge, and explore domain transfer learning techniques on emotional utterances collected under different emotion elicitation approaches, particularly with limited labeled target samples. Our emotion recognition model combines the gradient reversal technique with an entropy loss function as well as the softlabel loss, and the experiment results show that domain transfer learning methods can be employed to alleviate the domain mismatch between different elicitation approaches. Our work provides new insights into emotion data collection, particularly the impact of its elicitation strategies, and the importance of domain adaptation in emotion recognition aiming for generalized systems.
Unsupervised Speech Representation Learning for Behavior Modeling using Triplet Enhanced Contextualized Networks
Apr 01, 2021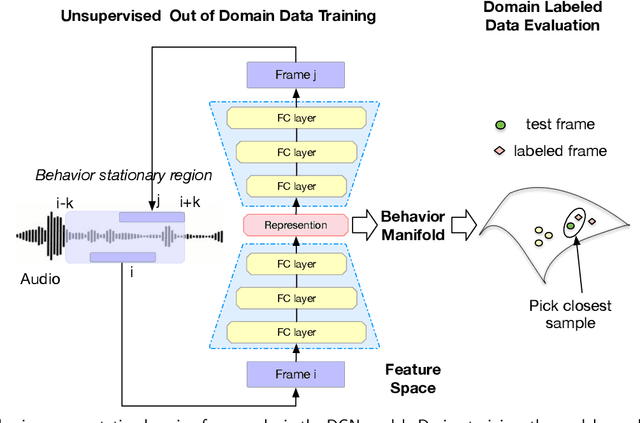

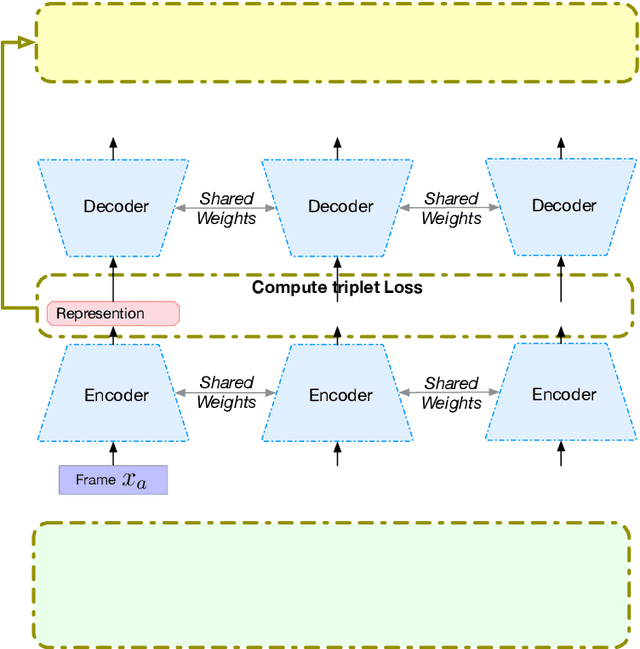
Speech encodes a wealth of information related to human behavior and has been used in a variety of automated behavior recognition tasks. However, extracting behavioral information from speech remains challenging including due to inadequate training data resources stemming from the often low occurrence frequencies of specific behavioral patterns. Moreover, supervised behavioral modeling typically relies on domain-specific construct definitions and corresponding manually-annotated data, rendering generalizing across domains challenging. In this paper, we exploit the stationary properties of human behavior within an interaction and present a representation learning method to capture behavioral information from speech in an unsupervised way. We hypothesize that nearby segments of speech share the same behavioral context and hence map onto similar underlying behavioral representations. We present an encoder-decoder based Deep Contextualized Network (DCN) as well as a Triplet-Enhanced DCN (TE-DCN) framework to capture the behavioral context and derive a manifold representation, where speech frames with similar behaviors are closer while frames of different behaviors maintain larger distances. The models are trained on movie audio data and validated on diverse domains including on a couples therapy corpus and other publicly collected data (e.g., stand-up comedy). With encouraging results, our proposed framework shows the feasibility of unsupervised learning within cross-domain behavioral modeling.
Front-end Diarization for Percussion Separation in Taniavartanam of Carnatic Music Concerts
Mar 04, 2021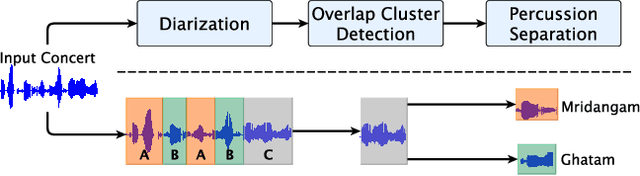
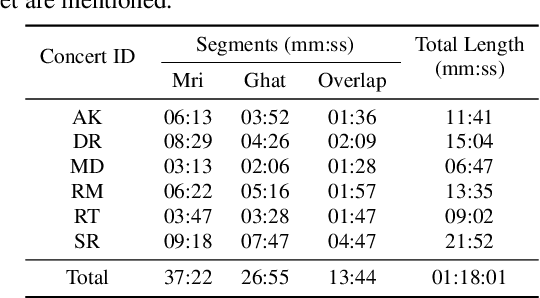
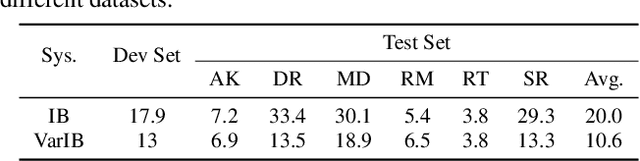
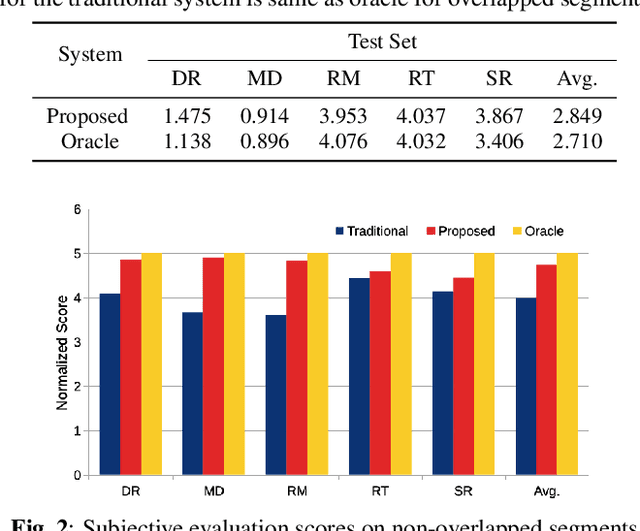
Instrument separation in an ensemble is a challenging task. In this work, we address the problem of separating the percussive voices in the taniavartanam segments of Carnatic music. In taniavartanam, a number of percussive instruments play together or in tandem. Separation of instruments in regions where only one percussion is present leads to interference and artifacts at the output, as source separation algorithms assume the presence of multiple percussive voices throughout the audio segment. We prevent this by first subjecting the taniavartanam to diarization. This process results in homogeneous clusters consisting of segments of either a single voice or multiple voices. A cluster of segments with multiple voices is identified using the Gaussian mixture model (GMM), which is then subjected to source separation. A deep recurrent neural network (DRNN) based approach is used to separate the multiple instrument segments. The effectiveness of the proposed system is evaluated on a standard Carnatic music dataset. The proposed approach provides close-to-oracle performance for non-overlapping segments and a significant improvement over traditional separation schemes.
Automated Quality Assessment of Cognitive Behavioral Therapy Sessions Through Highly Contextualized Language Representations
Feb 23, 2021

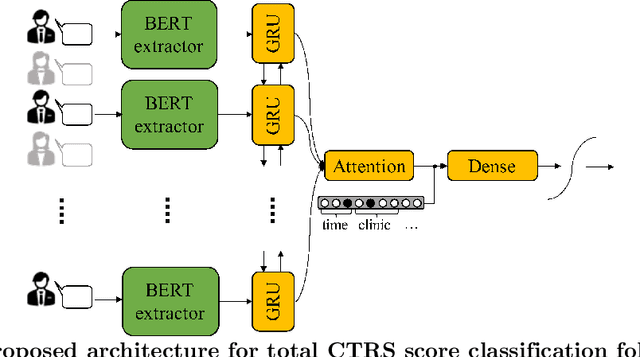
During a psychotherapy session, the counselor typically adopts techniques which are codified along specific dimensions (e.g., 'displays warmth and confidence', or 'attempts to set up collaboration') to facilitate the evaluation of the session. Those constructs, traditionally scored by trained human raters, reflect the complex nature of psychotherapy and highly depend on the context of the interaction. Recent advances in deep contextualized language models offer an avenue for accurate in-domain linguistic representations which can lead to robust recognition and scoring of such psychotherapy-relevant behavioral constructs, and support quality assurance and supervision. In this work, a BERT-based model is proposed for automatic behavioral scoring of a specific type of psychotherapy, called Cognitive Behavioral Therapy (CBT), where prior work is limited to frequency-based language features and/or short text excerpts which do not capture the unique elements involved in a spontaneous long conversational interaction. The model is trained in a multi-task manner in order to achieve higher interpretability. BERT-based representations are further augmented with available therapy metadata, providing relevant non-linguistic context and leading to consistent performance improvements.
"Am I A Good Therapist?" Automated Evaluation Of Psychotherapy Skills Using Speech And Language Technologies
Feb 22, 2021
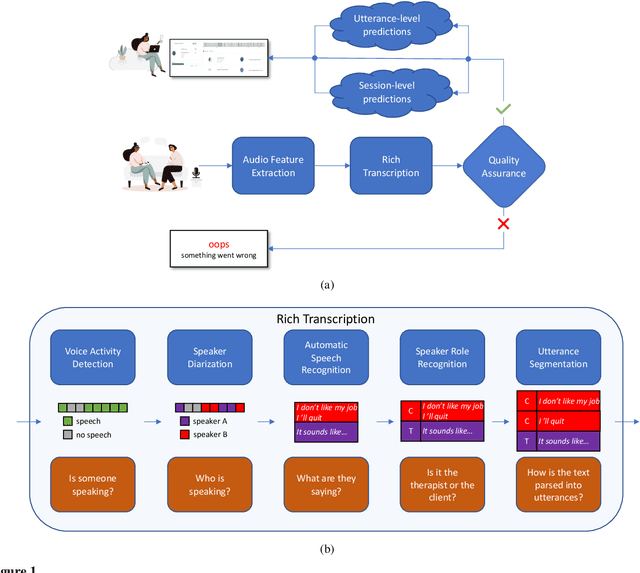
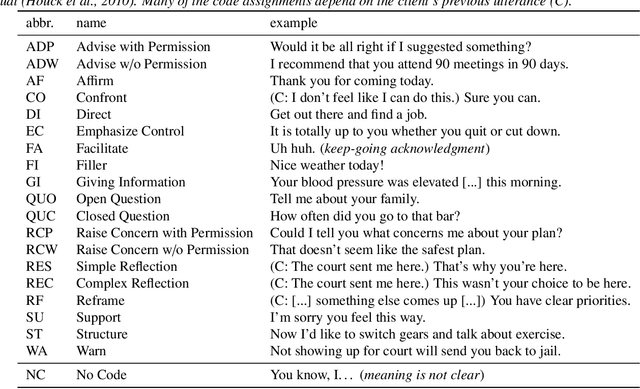
With the growing prevalence of psychological interventions, it is vital to have measures which rate the effectiveness of psychological care, in order to assist in training, supervision, and quality assurance of services. Traditionally, quality assessment is addressed by human raters who evaluate recorded sessions along specific dimensions, often codified through constructs relevant to the approach and domain. This is however a cost-prohibitive and time-consuming method which leads to poor feasibility and limited use in real-world settings. To facilitate this process, we have developed an automated competency rating tool able to process the raw recorded audio of a session, analyzing who spoke when, what they said, and how the health professional used language to provide therapy. Focusing on a use case of a specific type of psychotherapy called Motivational Interviewing, our system gives comprehensive feedback to the therapist, including information about the dynamics of the session (e.g., therapist's vs. client's talking time), low-level psychological language descriptors (e.g., type of questions asked), as well as other high-level behavioral constructs (e.g., the extent to which the therapist understands the clients' perspective). We describe our platform and its performance, using a dataset of more than 5,000 recordings drawn from its deployment in a real-world clinical setting used to assist training of new therapists. We are confident that a widespread use of automated psychotherapy rating tools in the near future will augment experts' capabilities by providing an avenue for more effective training and skill improvement and will eventually lead to more positive clinical outcomes.
Confusion2vec 2.0: Enriching Ambiguous Spoken Language Representations with Subwords
Feb 19, 2021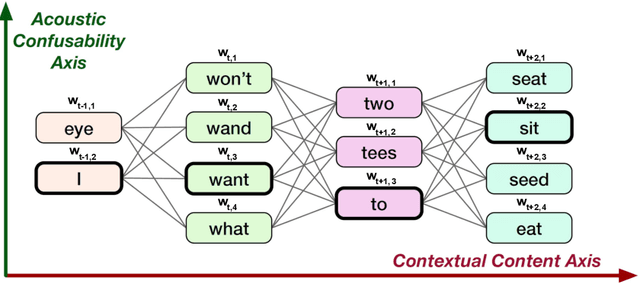
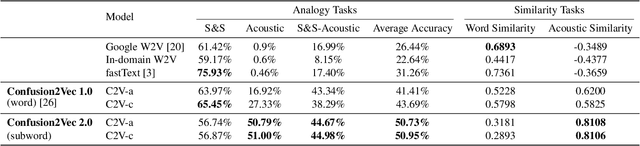
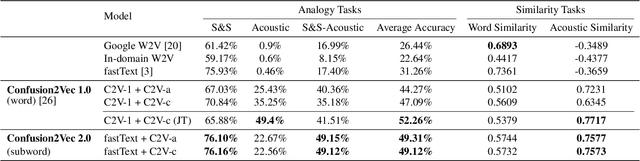
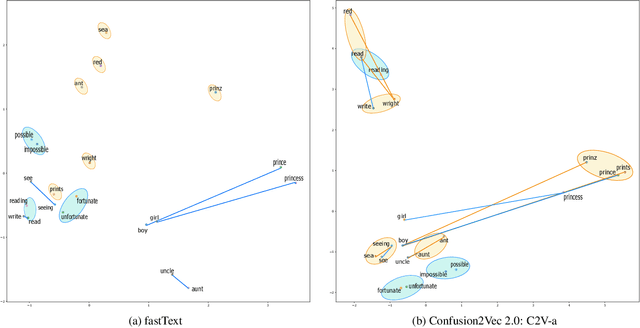
Word vector representations enable machines to encode human language for spoken language understanding and processing. Confusion2vec, motivated from human speech production and perception, is a word vector representation which encodes ambiguities present in human spoken language in addition to semantics and syntactic information. Confusion2vec provides a robust spoken language representation by considering inherent human language ambiguities. In this paper, we propose a novel word vector space estimation by unsupervised learning on lattices output by an automatic speech recognition (ASR) system. We encode each word in confusion2vec vector space by its constituent subword character n-grams. We show the subword encoding helps better represent the acoustic perceptual ambiguities in human spoken language via information modeled on lattice structured ASR output. The usefulness of the proposed Confusion2vec representation is evaluated using semantic, syntactic and acoustic analogy and word similarity tasks. We also show the benefits of subword modeling for acoustic ambiguity representation on the task of spoken language intent detection. The results significantly outperform existing word vector representations when evaluated on erroneous ASR outputs. We demonstrate that Confusion2vec subword modeling eliminates the need for retraining/adapting the natural language understanding models on ASR transcripts.