 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Fano's Inequality in Ensemble Learning
May 25, 2022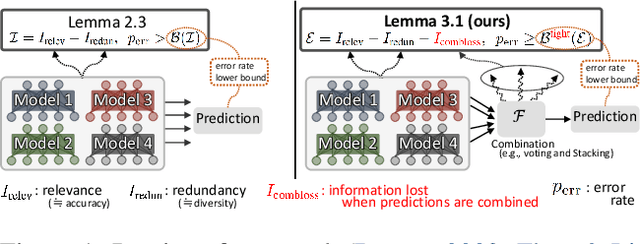
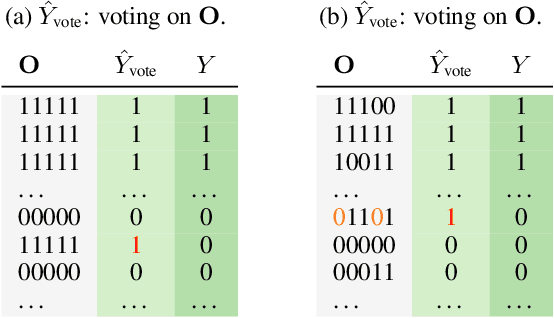

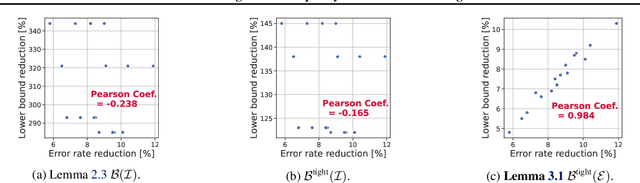
We propose a fundamental theory on ensemble learning that evaluates a given ensemble system by a well-grounded set of metrics. Previous studies used a variant of Fano's inequality of information theory and derived a lower bound of the classification error rate on the basis of the accuracy and diversity of models. We revisit the original Fano's inequality and argue that the studies did not take into account the information lost when multiple model predictions are combined into a final prediction. To address this issue, we generalize the previous theory to incorporate the information loss. Further, we empirically validate and demonstrate the proposed theory through extensive experiments on actual systems. The theory reveals the strengths and weaknesses of systems on each metric, which will push the theoretical understanding of ensemble learning and give us insights into designing systems.
Improving the Naturalness of Simulated Conversations for End-to-End Neural Diarization
Apr 24, 2022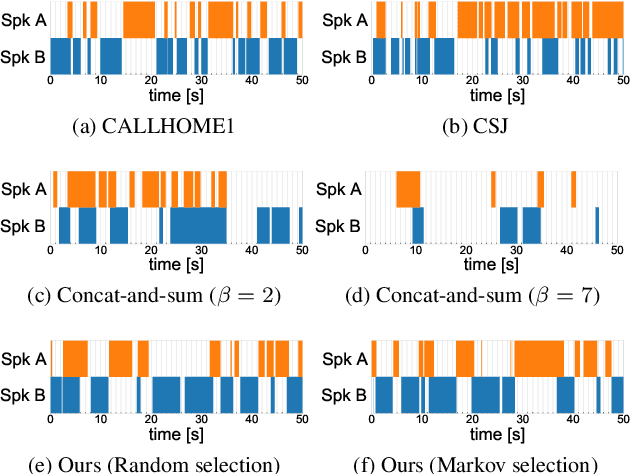
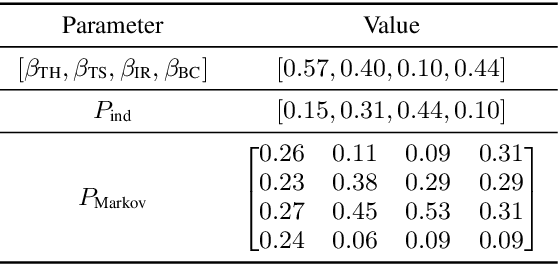
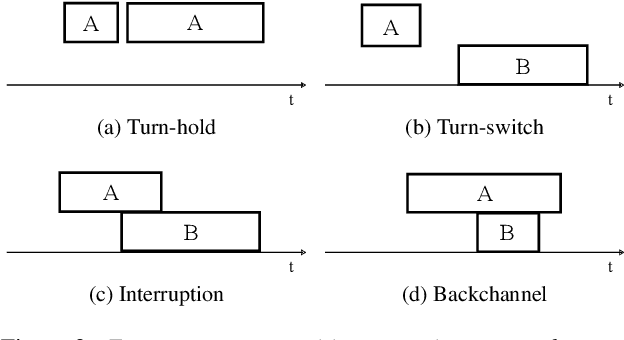
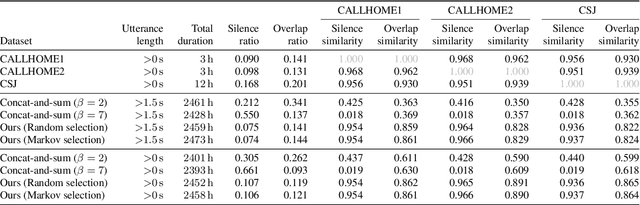
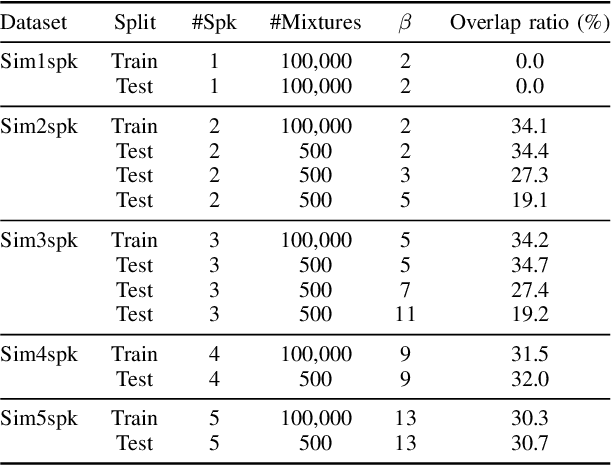
This paper investigates a method for simulating natural conversation in the model training of end-to-end neural diarization (EEND). Due to the lack of any annotated real conversational dataset, EEND is usually pretrained on a large-scale simulated conversational dataset first and then adapted to the target real dataset. Simulated datasets play an essential role in the training of EEND, but as yet there has been insufficient investigation into an optimal simulation method. We thus propose a method to simulate natural conversational speech. In contrast to conventional methods, which simply combine the speech of multiple speakers, our method takes turn-taking into account. We define four types of speaker transition and sequentially arrange them to simulate natural conversations. The dataset simulated using our method was found to be statistically similar to the real dataset in terms of the silence and overlap ratios. The experimental results on two-speaker diarization using the CALLHOME and CSJ datasets showed that the simulated dataset contributes to improving the performance of EEND.
Environmental Sound Extraction Using Onomatopoeia
Dec 02, 2021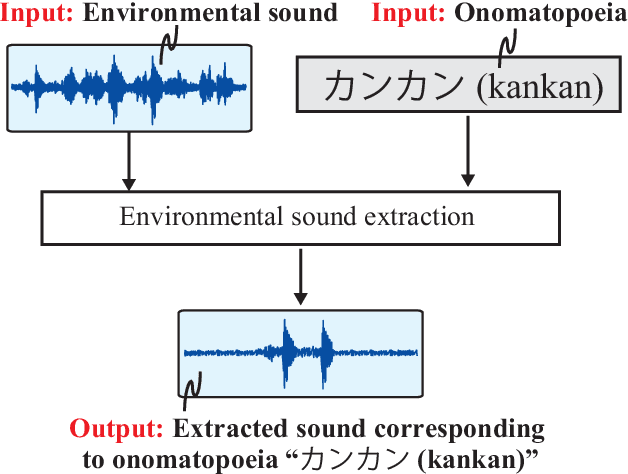
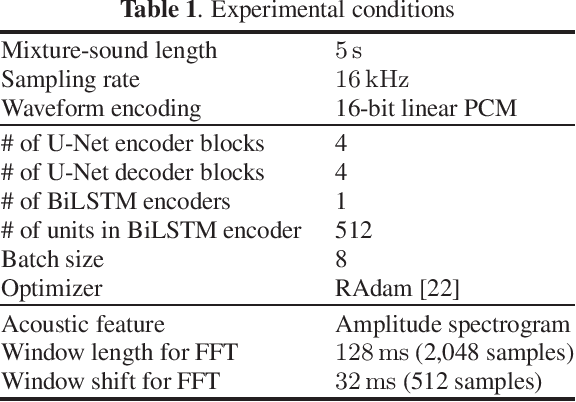
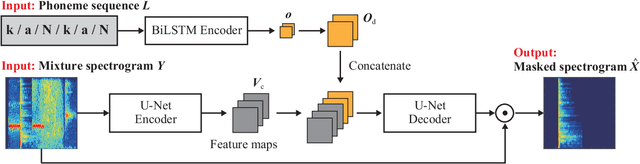
Onomatopoeia, which is a character sequence that phonetically imitates a sound, is effective in expressing characteristics of sound such as duration, pitch, and timbre. We propose an environmental-sound-extraction method using onomatopoeia to specify the target sound to be extracted. With this method, we estimate a time-frequency mask from an input mixture spectrogram and onomatopoeia by using U-Net architecture then extract the corresponding target sound by masking the spectrogram. Experimental results indicate that the proposed method can extract only the target sound corresponding to onomatopoeia and performs better than conventional methods that use sound-event classes to specify the target sound.
Multi-Channel End-to-End Neural Diarization with Distributed Microphones
Oct 10, 2021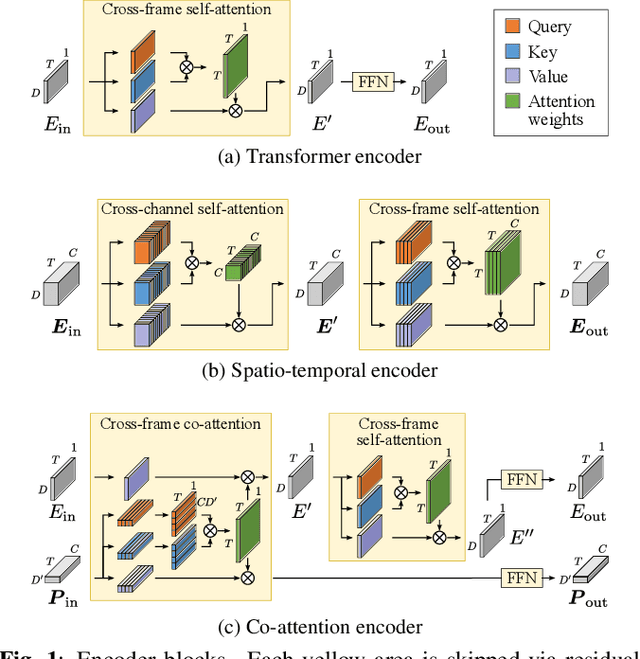
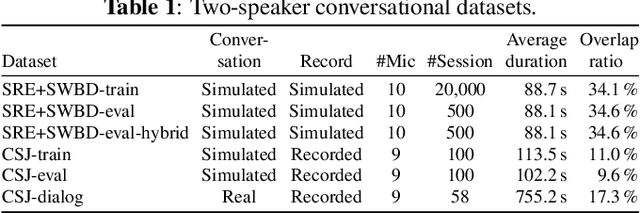
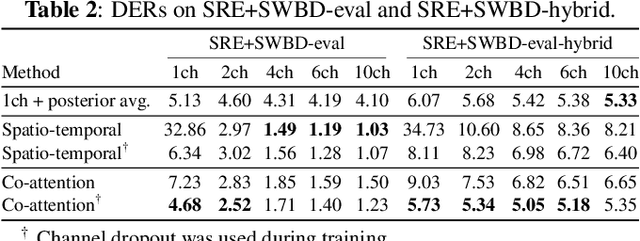
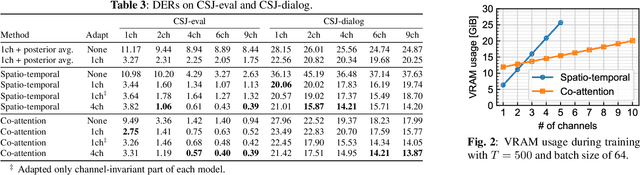
Recent progress on end-to-end neural diarization (EEND) has enabled overlap-aware speaker diarization with a single neural network. This paper proposes to enhance EEND by using multi-channel signals from distributed microphones. We replace Transformer encoders in EEND with two types of encoders that process a multi-channel input: spatio-temporal and co-attention encoders. Both are independent of the number and geometry of microphones and suitable for distributed microphone settings. We also propose a model adaptation method using only single-channel recordings. With simulated and real-recorded datasets, we demonstrated that the proposed method outperformed conventional EEND when a multi-channel input was given while maintaining comparable performance with a single-channel input. We also showed that the proposed method performed well even when spatial information is inoperative given multi-channel inputs, such as in hybrid meetings in which the utterances of multiple remote participants are played back from the same loudspeaker.
Towards Neural Diarization for Unlimited Numbers of Speakers Using Global and Local Attractors
Jul 04, 2021
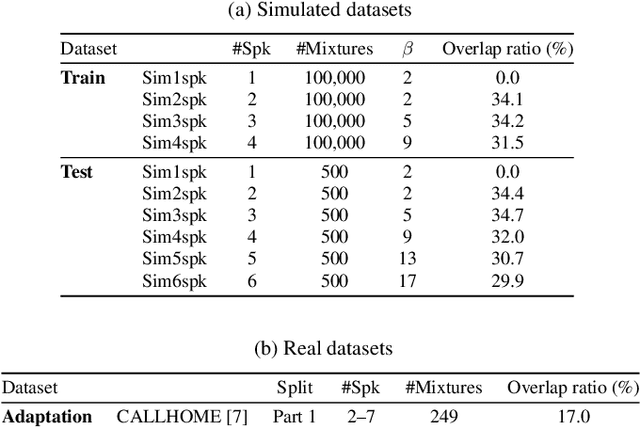
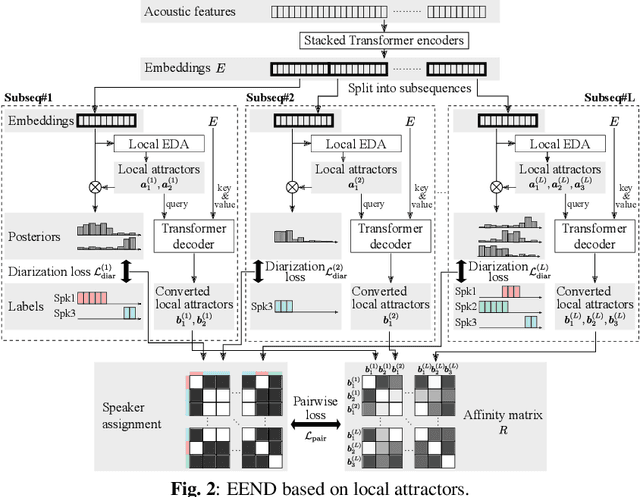
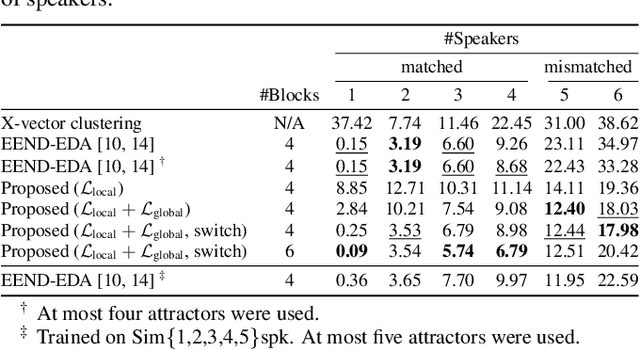
Attractor-based end-to-end diarization is achieving comparable accuracy to the carefully tuned conventional clustering-based methods on challenging datasets. However, the main drawback is that it cannot deal with the case where the number of speakers is larger than the one observed during training. This is because its speaker counting relies on supervised learning. In this work, we introduce an unsupervised clustering process embedded in the attractor-based end-to-end diarization. We first split a sequence of frame-wise embeddings into short subsequences and then perform attractor-based diarization for each subsequence. Given subsequence-wise diarization results, inter-subsequence speaker correspondence is obtained by unsupervised clustering of the vectors computed from the attractors from all the subsequences. This makes it possible to produce diarization results of a large number of speakers for the whole recording even if the number of output speakers for each subsequence is limited. Experimental results showed that our method could produce accurate diarization results of an unseen number of speakers. Our method achieved 11.84 %, 28.33 %, and 19.49 % on the CALLHOME, DIHARD II, and DIHARD III datasets, respectively, each of which is better than the conventional end-to-end diarization methods.
Encoder-Decoder Based Attractor Calculation for End-to-End Neural Diarization
Jun 20, 2021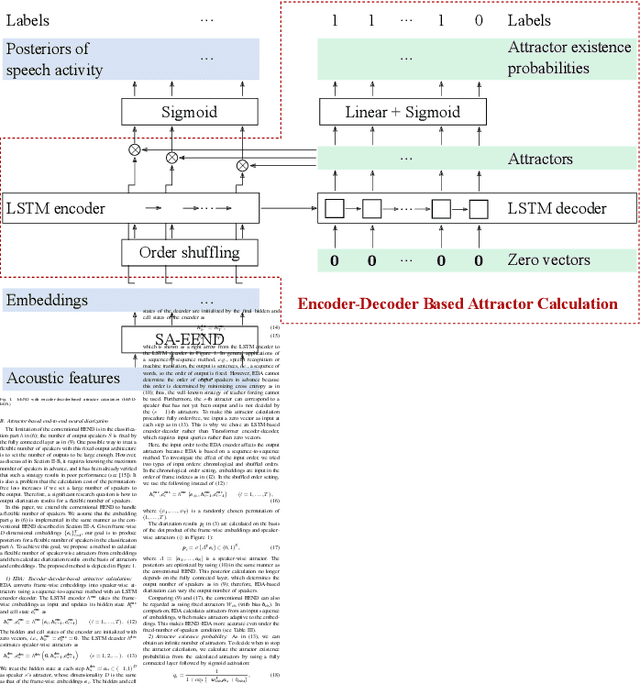
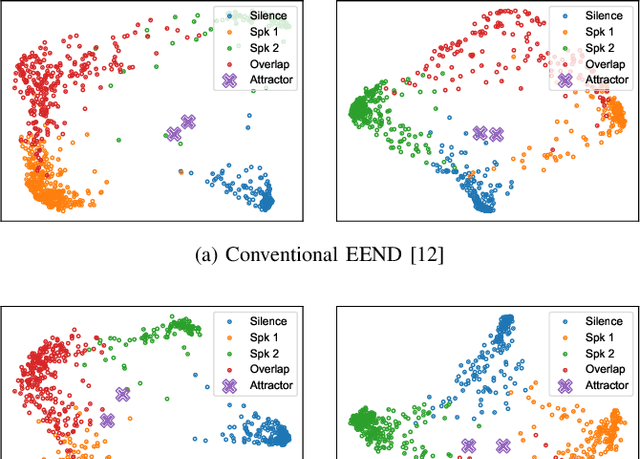
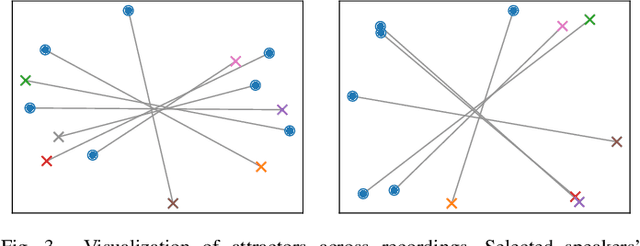
This paper investigates an end-to-end neural diarization (EEND) method for an unknown number of speakers. In contrast to the conventional pipeline approach to speaker diarization, EEND methods are better in terms of speaker overlap handling. However, EEND still has a disadvantage in that it cannot deal with a flexible number of speakers. To remedy this problem, we introduce encoder-decoder-based attractor calculation module (EDA) to EEND. Once frame-wise embeddings are obtained, EDA sequentially generates speaker-wise attractors on the basis of a sequence-to-sequence method using an LSTM encoder-decoder. The attractor generation continues until a stopping condition is satisfied; thus, the number of attractors can be flexible. Diarization results are then estimated as dot products of the attractors and embeddings. The embeddings from speaker overlaps result in larger dot product values with multiple attractors; thus, this method can deal with speaker overlaps. Because the maximum number of output speakers is still limited by the training set, we also propose an iterative inference method to remove this restriction. Further, we propose a method that aligns the estimated diarization results with the results of an external speech activity detector, which enables fair comparison against pipeline approaches. Extensive evaluations on simulated and real datasets show that EEND-EDA outperforms the conventional pipeline approach.
Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Jun 09, 2021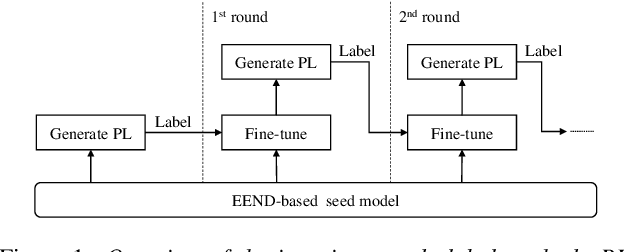
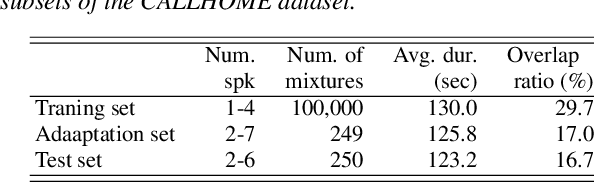
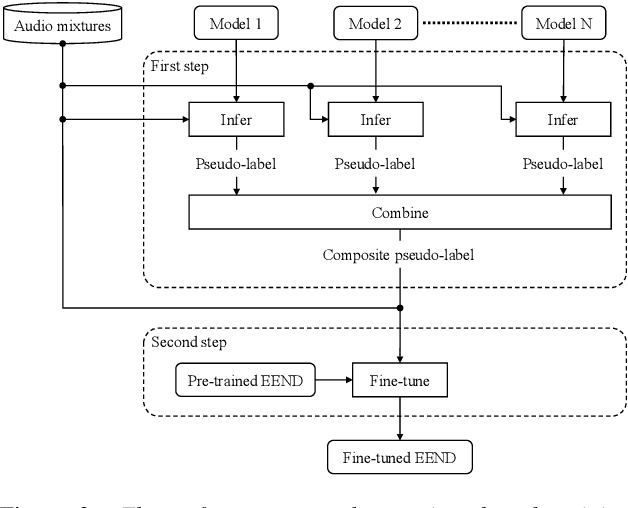
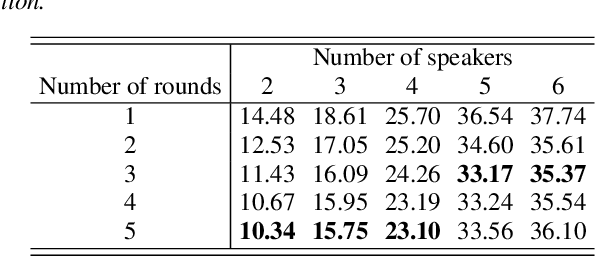
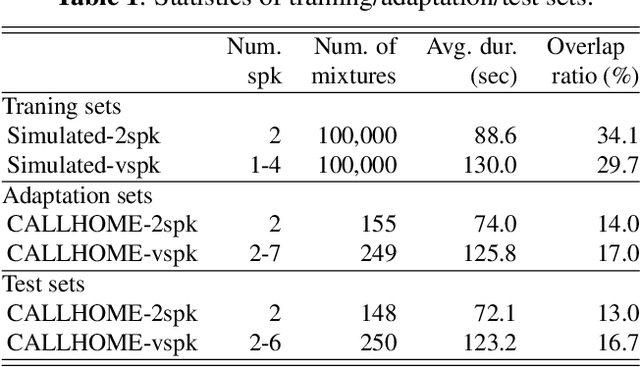
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.
End-to-End Speaker Diarization Conditioned on Speech Activity and Overlap Detection
Jun 08, 2021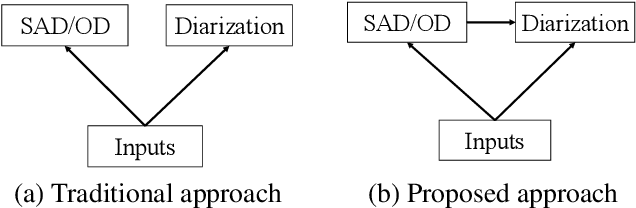
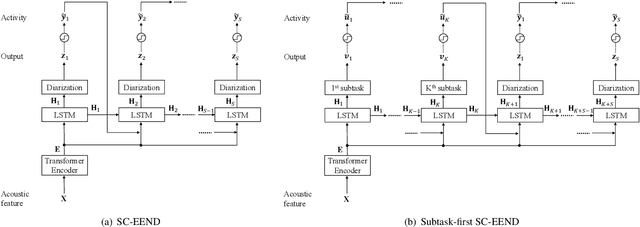
In this paper, we present a conditional multitask learning method for end-to-end neural speaker diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. In this paper, to further improve the performance of the EEND system, we propose a novel multitask learning framework that solves speaker diarization and a desired subtask while explicitly considering the task dependency. We optimize speaker diarization conditioned on speech activity and overlap detection that are subtasks of speaker diarization, based on the probabilistic chain rule. Experimental results show that our proposed method can leverage a subtask to effectively model speaker diarization, and outperforms conventional EEND systems in terms of diarization error rate.
* Accepted for SLT 2021
The Hitachi-JHU DIHARD III System: Competitive End-to-End Neural Diarization and X-Vector Clustering Systems Combined by DOVER-Lap
Feb 02, 2021
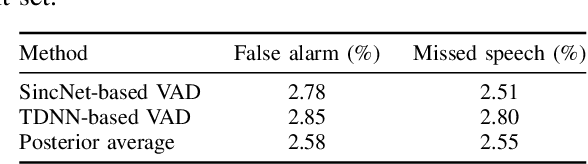

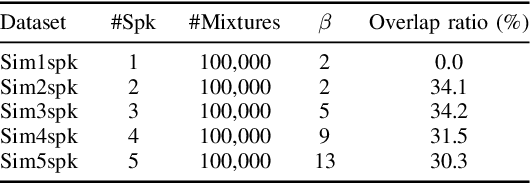
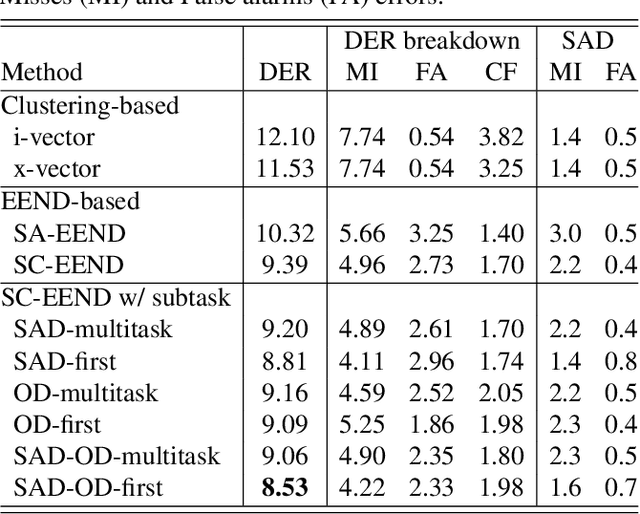
This paper provides a detailed description of the Hitachi-JHU system that was submitted to the Third DIHARD Speech Diarization Challenge. The system outputs the ensemble results of the five subsystems: two x-vector-based subsystems, two end-to-end neural diarization-based subsystems, and one hybrid subsystem. We refine each system and all five subsystems become competitive and complementary. After the DOVER-Lap based system combination, it achieved diarization error rates of 11.58 % and 14.09 % in Track 1 full and core, and 16.94 % and 20.01 % in Track 2 full and core, respectively. With their results, we won second place in all the tasks of the challenge.
Online End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers
Jan 21, 2021
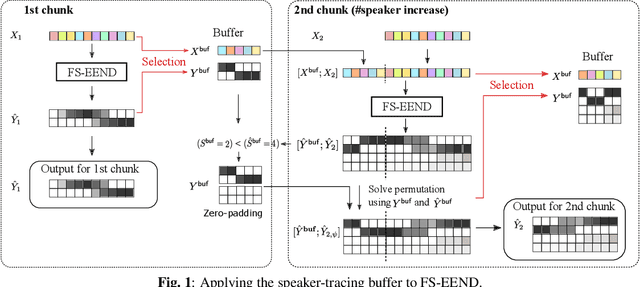


This paper proposes an online end-to-end diarization that can handle overlapping speech and flexible numbers of speakers. The end-to-end neural speaker diarization (EEND) model has already achieved significant improvement when compared with conventional clustering-based methods. However, the original EEND has two limitations: i) EEND does not perform well in online scenarios; ii) the number of speakers must be fixed in advance. This paper solves both problems by applying a modified extension of the speaker-tracing buffer method that deals with variable numbers of speakers. Experiments on CALLHOME and DIHARD II datasets show that the proposed online method achieves comparable performance to the offline EEND method. Compared with the state-of-the-art online method based on a fully supervised approach (UIS-RNN), the proposed method shows better performance on the DIHARD II dataset.