 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerStep: Memory-Efficient Adaptive Optimization via $\ell_p$-Norm Steepest Descent
May 11, 2026Adaptive optimizers, most notably Adam, have become the default standard for training large-scale neural networks such as Transformers. These methods maintain running estimates of gradient first and second moments, incurring substantial memory overhead. We introduce PowerStep, a memory-efficient optimizer that achieves coordinate-wise adaptivity without storing second-moment statistics. Motivated by steepest descent under an $\ell_p$-norm geometry, we show that applying a nonlinear transform directly to a momentum buffer yields coordinate-wise adaptivity. We prove that PowerStep converges at the optimal $O(1/\sqrt{T})$ rate for non-convex stochastic optimization. Extensive experiments on Transformer models ranging from 124M to 235B parameters demonstrate that PowerStep matches Adam's convergence speed while halving optimizer memory. Furthermore, when combined with aggressive \texttt{int8} quantization, PowerStep remains numerically stable and reduces optimizer memory by $\sim\!8\times$ compared to full-precision Adam. PowerStep thus provides a principled, scalable and resource-efficient alternative for large-scale training. Code is available at https://github.com/yaolubrain/PowerStep.
FMore: An Incentive Scheme of Multi-dimensional Auction for Federated Learning in MEC
Feb 22, 2020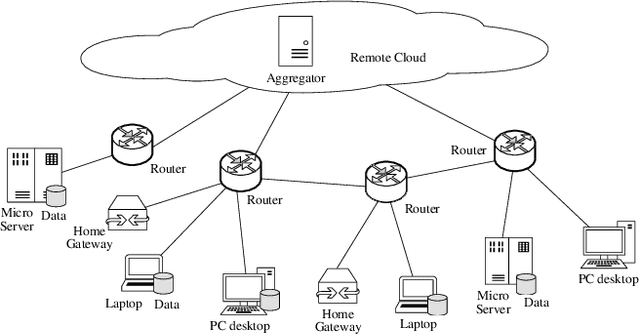
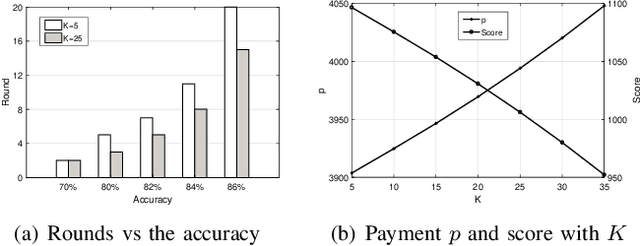
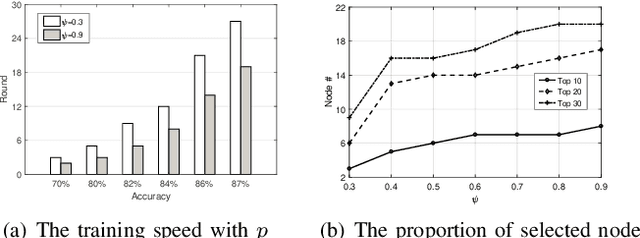
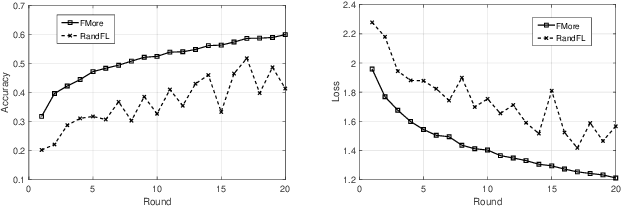
Promising federated learning coupled with Mobile Edge Computing (MEC) is considered as one of the most promising solutions to the AI-driven service provision. Plenty of studies focus on federated learning from the performance and security aspects, but they neglect the incentive mechanism. In MEC, edge nodes would not like to voluntarily participate in learning, and they differ in the provision of multi-dimensional resources, both of which might deteriorate the performance of federated learning. Also, lightweight schemes appeal to edge nodes in MEC. These features require the incentive mechanism to be well designed for MEC. In this paper, we present an incentive mechanism FMore with multi-dimensional procurement auction of K winners. Our proposal FMore not only is lightweight and incentive compatible, but also encourages more high-quality edge nodes with low cost to participate in learning and eventually improve the performance of federated learning. We also present theoretical results of Nash equilibrium strategy to edge nodes and employ the expected utility theory to provide guidance to the aggregator. Both extensive simulations and real-world experiments demonstrate that the proposed scheme can effectively reduce the training rounds and drastically improve the model accuracy for challenging AI tasks.