 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian-Manifold Steering: Geometry-Aware Generative Autoencoders for Label-Free Steering
May 24, 2026Steering a language model - intervening on its internal activations to change downstream behaviour - has recently expanded beyond linear interpolation to nonlinear methods such as angular and kernelized steering, which define intervention transformations without learning an explicit geometry over paths in activation space. Freshly introduced geometry-aware manifold methods do learn such a geometry, but require labelled class centroids together with prescribed cyclic or sequential structure. These assumptions restrict where manifold steering can be applied, since existing constructions require labelled centroids and compatible boundary conditions. We recast manifold steering more broadly as \textbf{Riemannian geodesic computation} on activation space, recovering linear and labelled-spline steering as geodesics under particular choices of metric. A principled metric within this framework is the output-space Hellinger distance pulled back to activations; we approximate this with a learned encoder trained on output distances over a small concept-token schema - no per-prompt labels, no topology prior, and no per-task curve fitting. Empirically, the method reliably drives the model onto the target class across all tasks in a standard four-task language-model arithmetic benchmark, while following more behaviourally natural trajectories than baselines on smaller output spaces. We thereby provide a unified Riemannian framework for manifold steering together with a schema-supervised, label-free instantiation that operates without labelled centroids or prescribed boundary conditions.
Intersectional Sycophancy: How Perceived User Demographics Shape False Validation in Large Language Models
Apr 13, 2026Large language models exhibit sycophantic tendencies--validating incorrect user beliefs to appear agreeable. We investigate whether this behavior varies systematically with perceived user demographics, testing whether combinations of race, age, gender, and expressed confidence level produce differential false validation rates. Inspired by the legal concept of intersectionality, we conduct 768 multi-turn adversarial conversations using Anthropic's Petri evaluation framework, probing GPT-5-nano and Claude Haiku 4.5 across 128 persona combinations in mathematics, philosophy, and conspiracy theory domains. GPT-5-nano is significantly more sycophantic than Claude Haiku 4.5 overall ($\bar{x}=2.96$ vs. $1.74$, $p < 10^{-32}$, Wilcoxon signed-rank). For GPT-5-nano, we find that philosophy elicits 41% more sycophancy than mathematics and that Hispanic personas receive the highest sycophancy across races. The worst-scoring persona, a confident, 23-year-old Hispanic woman, averages 5.33/10 on sycophancy. Claude Haiku 4.5 exhibits uniformly low sycophancy with no significant demographic variation. These results demonstrate that sycophancy is not uniformly distributed across users and that safety evaluations should incorporate identity-aware testing.
Curveball Steering: The Right Direction To Steer Isn't Always Linear
Mar 11, 2026Activation steering is a widely used approach for controlling large language model (LLM) behavior by intervening on internal representations. Existing methods largely rely on the Linear Representation Hypothesis, assuming behavioral attributes can be manipulated using global linear directions. In practice, however, such linear interventions often behave inconsistently. We question this assumption by analyzing the intrinsic geometry of LLM activation spaces. Measuring geometric distortion via the ratio of geodesic to Euclidean distances, we observe substantial and concept-dependent distortions, indicating that activation spaces are not well-approximated by a globally linear geometry. Motivated by this, we propose "Curveball steering", a nonlinear steering method based on polynomial kernel PCA that performs interventions in a feature space, better respecting the learned activation geometry. Curveball steering consistently outperforms linear PCA-based steering, particularly in regimes exhibiting strong geometric distortion, suggesting that geometry-aware, nonlinear steering provides a principled alternative to global, linear interventions.
Narrow fine-tuning erodes safety alignment in vision-language agents
Feb 18, 2026Lifelong multimodal agents must continuously adapt to new tasks through post-training, but this creates fundamental tension between acquiring capabilities and preserving safety alignment. We demonstrate that fine-tuning aligned vision-language models on narrow-domain harmful datasets induces severe emergent misalignment that generalizes broadly across unrelated tasks and modalities. Through experiments on Gemma3-4B, we show that misalignment scales monotonically with LoRA rank, and that multimodal evaluation reveals substantially higher misalignment ($70.71 \pm 1.22$ at $r=128$) than text-only evaluation ($41.19 \pm 2.51$), suggesting that unimodal safety benchmarks may underestimate alignment degradation in vision-language models. Critically, even 10\% harmful data in the training mixture induces substantial alignment degradation. Geometric analysis reveals that harmful behaviors occupy a remarkably low-dimensional subspace, with the majority of misalignment information captured in 10 principal components. To mitigate misalignment, we evaluate two strategies: benign narrow fine-tuning and activation-based steering. While both approaches substantially reduce misalignment, neither completely removes the learned harmful behaviors. Our findings highlight the need for robust continual learning frameworks, as current post-training paradigms may not sufficiently preserve alignment in post-deployment settings.
Spectral Superposition: A Theory of Feature Geometry
Feb 02, 2026Neural networks represent more features than they have dimensions via superposition, forcing features to share representational space. Current methods decompose activations into sparse linear features but discard geometric structure. We develop a theory for studying the geometric structre of features by analyzing the spectra (eigenvalues, eigenspaces, etc.) of weight derived matrices. In particular, we introduce the frame operator $F = WW^\top$, which gives us a spectral measure that describes how each feature allocates norm across eigenspaces. While previous tools could describe the pairwise interactions between features, spectral methods capture the global geometry (``how do all features interact?''). In toy models of superposition, we use this theory to prove that capacity saturation forces spectral localization: features collapse onto single eigenspaces, organize into tight frames, and admit discrete classification via association schemes, classifying all geometries from prior work (simplices, polygons, antiprisms). The spectral measure formalism applies to arbitrary weight matrices, enabling diagnosis of feature localization beyond toy settings. These results point toward a broader program: applying operator theory to interpretability.
Caught in the Act: a mechanistic approach to detecting deception
Aug 27, 2025Sophisticated instrumentation for AI systems might have indicators that signal misalignment from human values, not unlike a "check engine" light in cars. One such indicator of misalignment is deceptiveness in generated responses. Future AI instrumentation may have the ability to detect when an LLM generates deceptive responses while reasoning about seemingly plausible but incorrect answers to factual questions. In this work, we demonstrate that linear probes on LLMs internal activations can detect deception in their responses with extremely high accuracy. Our probes reach a maximum of greater than 90% accuracy in distinguishing between deceptive and non-deceptive arguments generated by llama and qwen models ranging from 1.5B to 14B parameters, including their DeepSeek-r1 finetuned variants. We observe that probes on smaller models (1.5B) achieve chance accuracy at detecting deception, while larger models (greater than 7B) reach 70-80%, with their reasoning counterparts exceeding 90%. The layer-wise probe accuracy follows a three-stage pattern across layers: near-random (50%) in early layers, peaking in middle layers, and slightly declining in later layers. Furthermore, using an iterative null space projection approach, we find multitudes of linear directions that encode deception, ranging from 20 in Qwen 3B to nearly 100 in DeepSeek 7B and Qwen 14B models.
Designing a Dashboard for Transparency and Control of Conversational AI
Jun 12, 2024



Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype-connecting interpretability techniques with user experience design-that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a "user model": examining the internal state of the system, we can extract data related to a user's age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system's behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at https://bit.ly/talktuner-project-page
SupCL-Seq: Supervised Contrastive Learning for Downstream Optimized Sequence Representations
Sep 15, 2021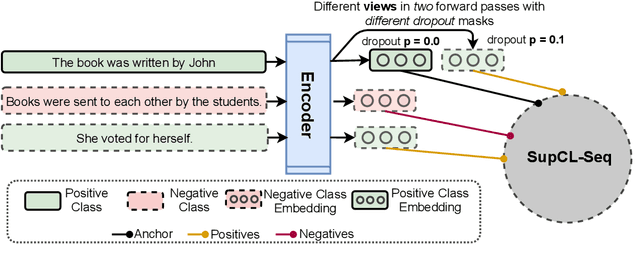
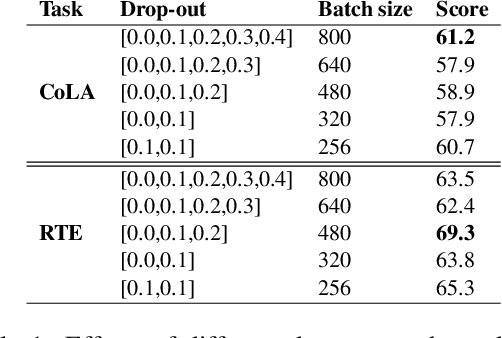


While contrastive learning is proven to be an effective training strategy in computer vision, Natural Language Processing (NLP) is only recently adopting it as a self-supervised alternative to Masked Language Modeling (MLM) for improving sequence representations. This paper introduces SupCL-Seq, which extends the supervised contrastive learning from computer vision to the optimization of sequence representations in NLP. By altering the dropout mask probability in standard Transformer architectures, for every representation (anchor), we generate augmented altered views. A supervised contrastive loss is then utilized to maximize the system's capability of pulling together similar samples (e.g., anchors and their altered views) and pushing apart the samples belonging to the other classes. Despite its simplicity, SupCLSeq leads to large gains in many sequence classification tasks on the GLUE benchmark compared to a standard BERTbase, including 6% absolute improvement on CoLA, 5.4% on MRPC, 4.7% on RTE and 2.6% on STSB. We also show consistent gains over self supervised contrastively learned representations, especially in non-semantic tasks. Finally we show that these gains are not solely due to augmentation, but rather to a downstream optimized sequence representation. Code: https://github.com/hooman650/SupCL-Seq
Exploring a Unified Sequence-To-Sequence Transformer for Medical Product Safety Monitoring in Social Media
Sep 13, 2021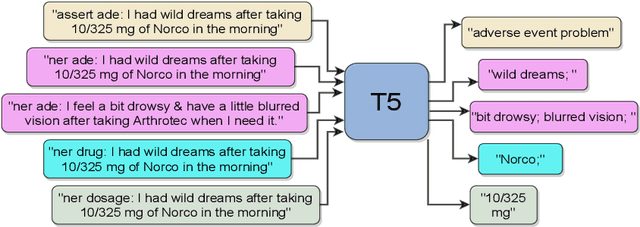

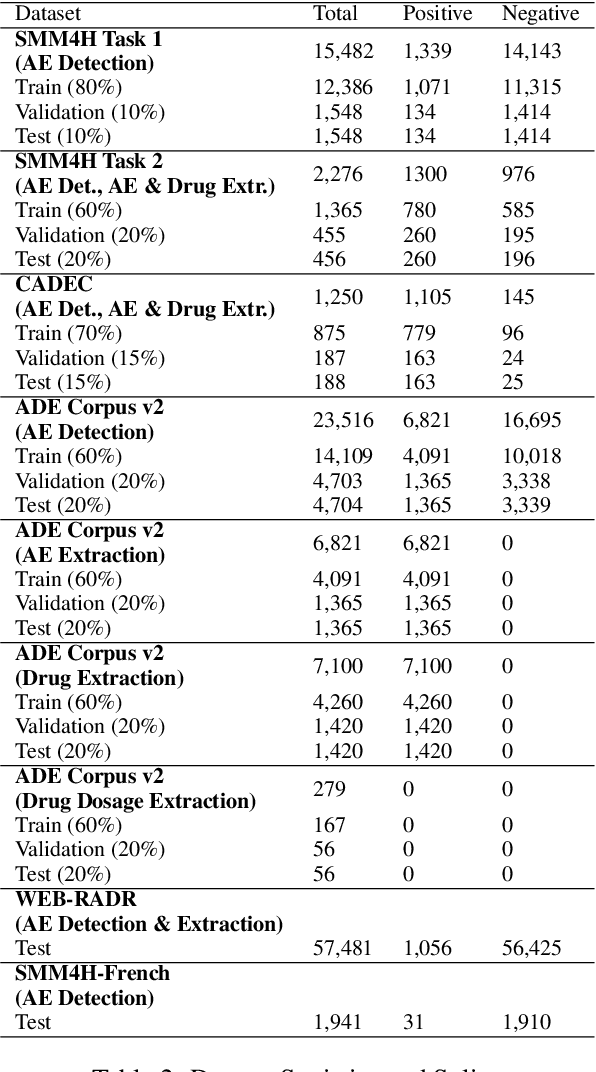
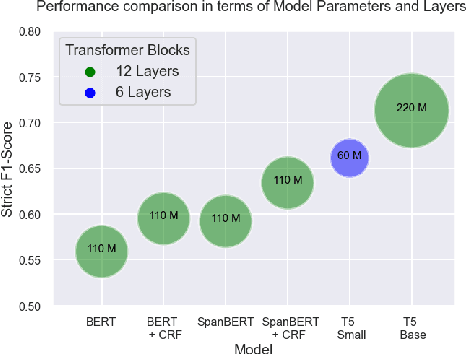
Adverse Events (AE) are harmful events resulting from the use of medical products. Although social media may be crucial for early AE detection, the sheer scale of this data makes it logistically intractable to analyze using human agents, with NLP representing the only low-cost and scalable alternative. In this paper, we frame AE Detection and Extraction as a sequence-to-sequence problem using the T5 model architecture and achieve strong performance improvements over competitive baselines on several English benchmarks (F1 = 0.71, 12.7% relative improvement for AE Detection; Strict F1 = 0.713, 12.4% relative improvement for AE Extraction). Motivated by the strong commonalities between AE-related tasks, the class imbalance in AE benchmarks and the linguistic and structural variety typical of social media posts, we propose a new strategy for multi-task training that accounts, at the same time, for task and dataset characteristics. Our multi-task approach increases model robustness, leading to further performance gains. Finally, our framework shows some language transfer capabilities, obtaining higher performance than Multilingual BERT in zero-shot learning on French data.