 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Stein Training for Graph Energy Models
Aug 30, 2021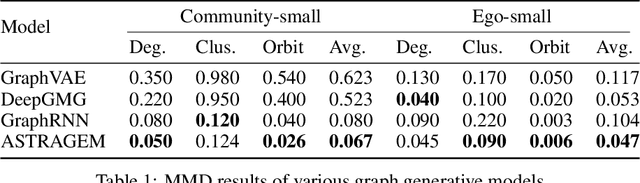

Learning distributions over graph-structured data is a challenging task with many applications in biology and chemistry. In this work we use an energy-based model (EBM) based on multi-channel graph neural networks (GNN) to learn permutation invariant unnormalized density functions on graphs. Unlike standard EBM training methods our approach is to learn the model via minimizing adversarial stein discrepancy. Samples from the model can be obtained via Langevin dynamics based MCMC. We find that this approach achieves competitive results on graph generation compared to benchmark models.
Sibling Regression for Generalized Linear Models
Jul 07, 2021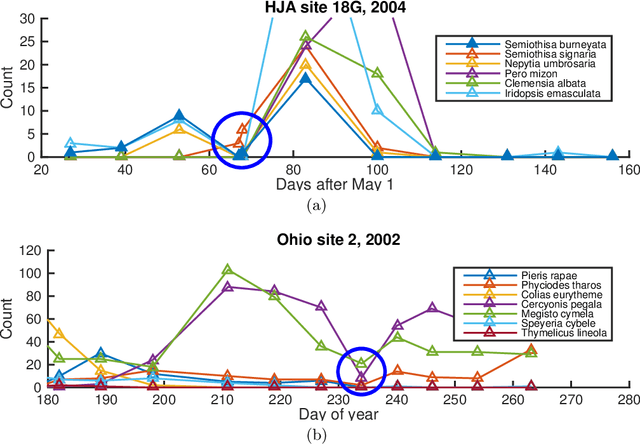
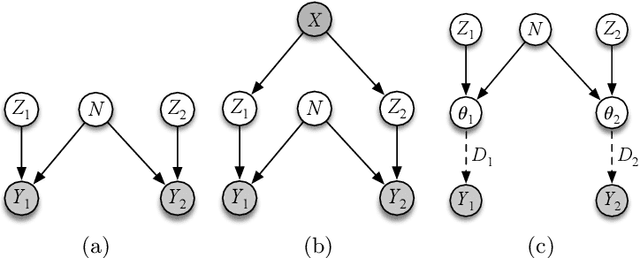
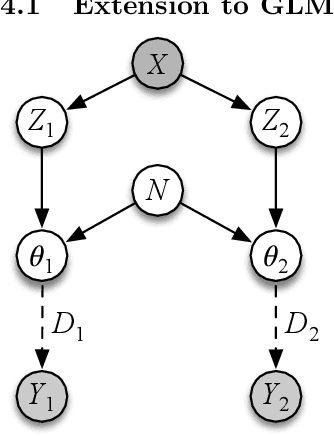
Field observations form the basis of many scientific studies, especially in ecological and social sciences. Despite efforts to conduct such surveys in a standardized way, observations can be prone to systematic measurement errors. The removal of systematic variability introduced by the observation process, if possible, can greatly increase the value of this data. Existing non-parametric techniques for correcting such errors assume linear additive noise models. This leads to biased estimates when applied to generalized linear models (GLM). We present an approach based on residual functions to address this limitation. We then demonstrate its effectiveness on synthetic data and show it reduces systematic detection variability in moth surveys.
High-Confidence Off-Policy (or Counterfactual) Variance Estimation
Jan 25, 2021
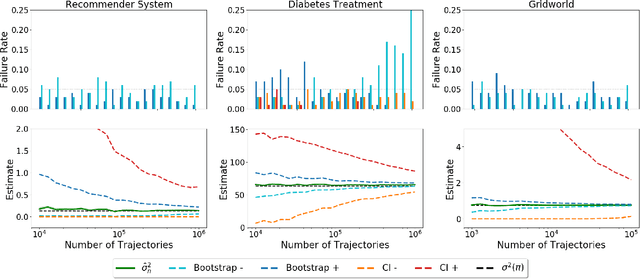
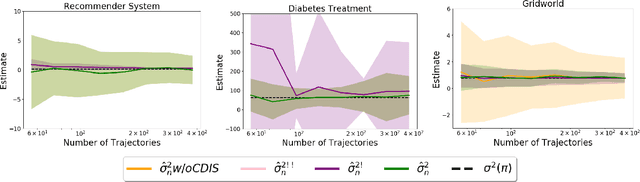
Many sequential decision-making systems leverage data collected using prior policies to propose a new policy. For critical applications, it is important that high-confidence guarantees on the new policy's behavior are provided before deployment, to ensure that the policy will behave as desired. Prior works have studied high-confidence off-policy estimation of the expected return, however, high-confidence off-policy estimation of the variance of returns can be equally critical for high-risk applications. In this paper, we tackle the previously open problem of estimating and bounding, with high confidence, the variance of returns from off-policy data
Bosonic Random Walk Networks for Graph Learning
Dec 31, 2020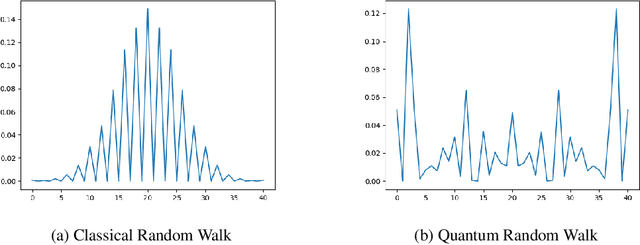
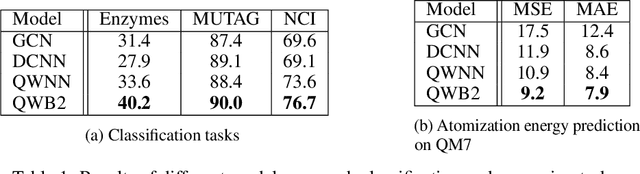
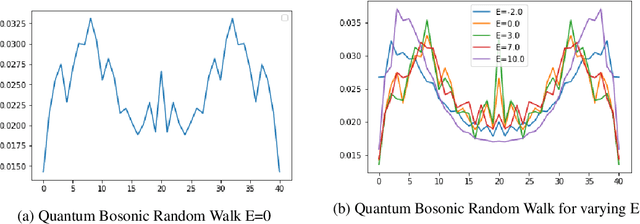
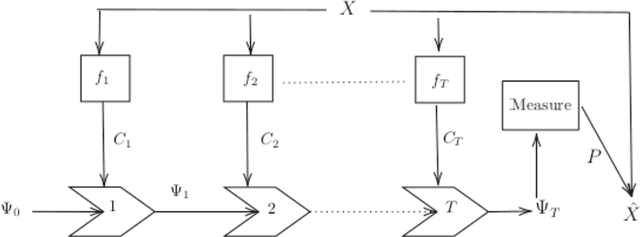
The development of Graph Neural Networks (GNNs) has led to great progress in machine learning on graph-structured data. These networks operate via diffusing information across the graph nodes while capturing the structure of the graph. Recently there has also seen tremendous progress in quantum computing techniques. In this work, we explore applications of multi-particle quantum walks on diffusing information across graphs. Our model is based on learning the operators that govern the dynamics of quantum random walkers on graphs. We demonstrate the effectiveness of our method on classification and regression tasks.
Three-quarter Sibling Regression for Denoising Observational Data
Dec 31, 2020
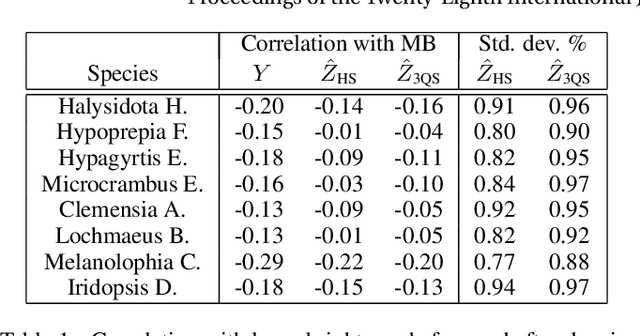
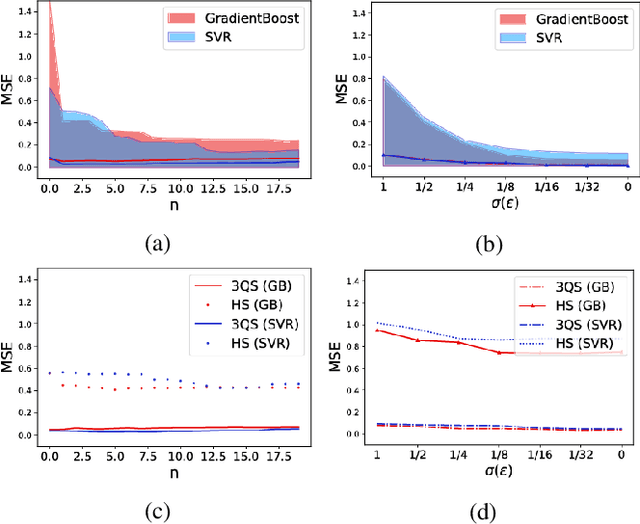
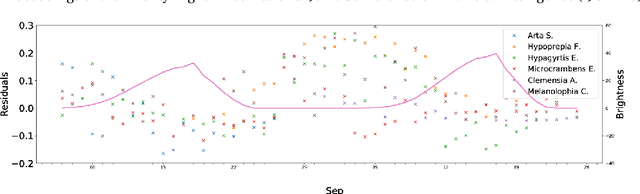
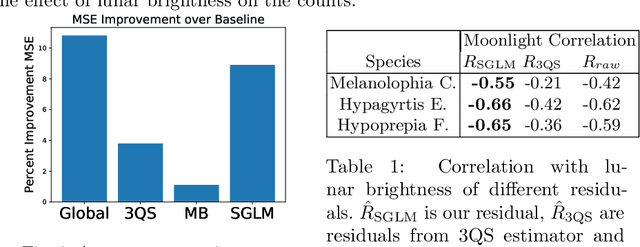
Many ecological studies and conservation policies are based on field observations of species, which can be affected by systematic variability introduced by the observation process. A recently introduced causal modeling technique called 'half-sibling regression' can detect and correct for systematic errors in measurements of multiple independent random variables. However, it will remove intrinsic variability if the variables are dependent, and therefore does not apply to many situations, including modeling of species counts that are controlled by common causes. We present a technique called 'three-quarter sibling regression' to partially overcome this limitation. It can filter the effect of systematic noise when the latent variables have observed common causes. We provide theoretical justification of this approach, demonstrate its effectiveness on synthetic data, and show that it reduces systematic detection variability due to moon brightness in moth surveys.
Untapped Potential of Data Augmentation: A Domain Generalization Viewpoint
Jul 09, 2020
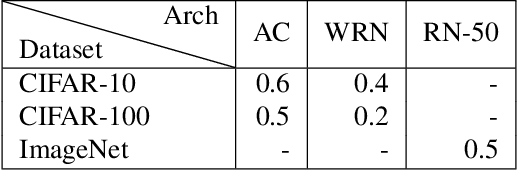
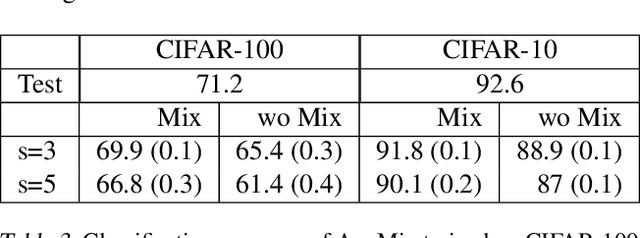
Data augmentation is a popular pre-processing trick to improve generalization accuracy. It is believed that by processing augmented inputs in tandem with the original ones, the model learns a more robust set of features which are shared between the original and augmented counterparts. However, we show that is not the case even for the best augmentation technique. In this work, we take a Domain Generalization viewpoint of augmentation based methods. This new perspective allowed for probing overfitting and delineating avenues for improvement. Our exploration with the state-of-art augmentation method provides evidence that the learned representations are not as robust even towards distortions used during training. This suggests evidence for the untapped potential of augmented examples.
Optimizing for the Future in Non-Stationary MDPs
Jun 02, 2020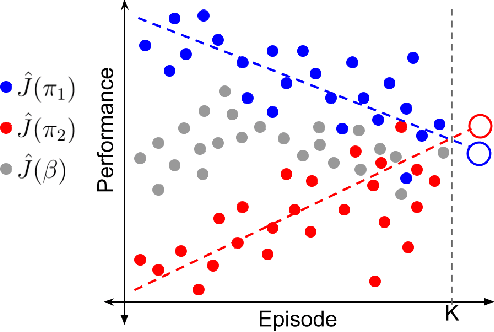
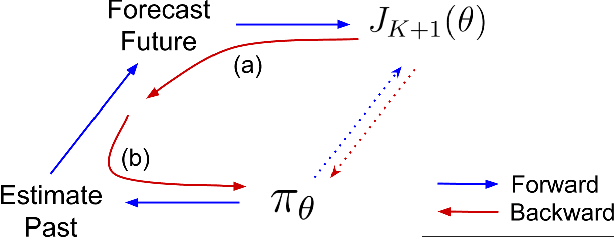
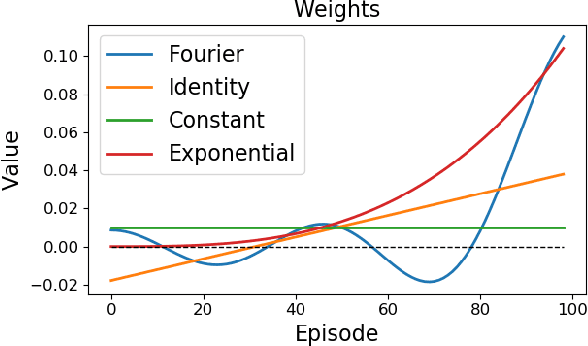
Most reinforcement learning methods are based upon the key assumption that the transition dynamics and reward functions are fixed, that is, the underlying Markov decision process (MDP) is stationary. However, in many practical real-world applications, this assumption is often violated. We discuss how current methods can have inherent limitations for non-stationary MDPs, and therefore searching for a policy that is good for the future, unknown MDP, requires rethinking the optimization paradigm. To address this problem, we develop a method that builds upon ideas from both counter-factual reasoning and curve-fitting to proactively search for a good future policy, without ever modeling the underlying non-stationarity. Interestingly, we observe that minimizing performance over some of the data from past episodes might be beneficial when searching for a policy that maximizes future performance. The effectiveness of the proposed method is demonstrated on problems motivated by real-world applications.
Differential Equation Units: Learning Functional Forms of Activation Functions from Data
Sep 06, 2019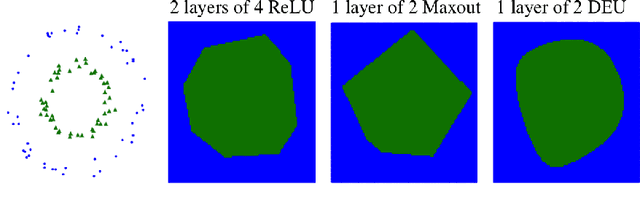

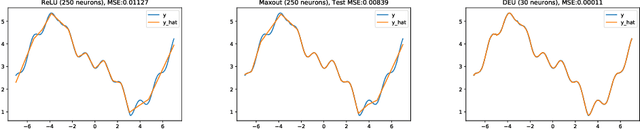
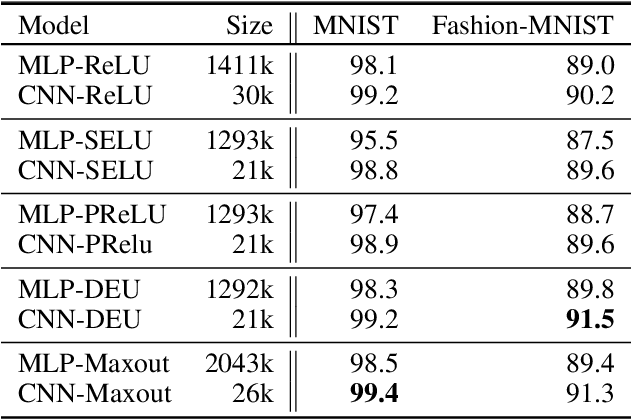
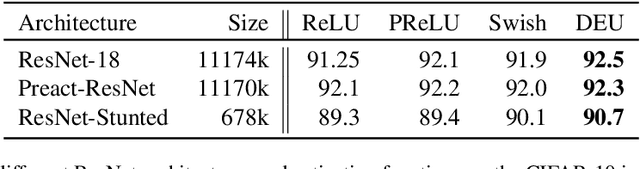
Most deep neural networks use simple, fixed activation functions, such as sigmoids or rectified linear units, regardless of domain or network structure. We introduce differential equation units (DEUs), an improvement to modern neural networks, which enables each neuron to learn a particular nonlinear activation function from a family of solutions to an ordinary differential equation. Specifically, each neuron may change its functional form during training based on the behavior of the other parts of the network. We show that using neurons with DEU activation functions results in a more compact network capable of achieving comparable, if not superior, performance when is compared to much larger networks.
Learning Compact Neural Networks Using Ordinary Differential Equations as Activation Functions
May 19, 2019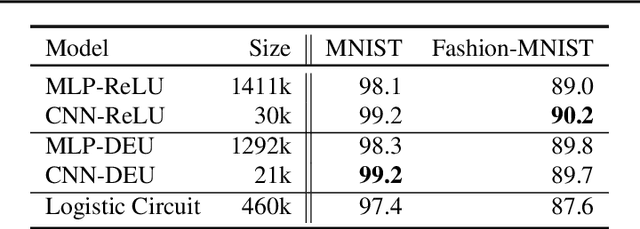
Most deep neural networks use simple, fixed activation functions, such as sigmoids or rectified linear units, regardless of domain or network structure. We introduce differential equation units (DEUs), an improvement to modern neural networks, which enables each neuron to learn a particular nonlinear activation function from a family of solutions to an ordinary differential equation. Specifically, each neuron may change its functional form during training based on the behavior of the other parts of the network. We show that using neurons with DEU activation functions results in a more compact network capable of achieving comparable, if not superior, performance when is compared to much larger networks.
Generalizing Across Domains via Cross-Gradient Training
May 01, 2018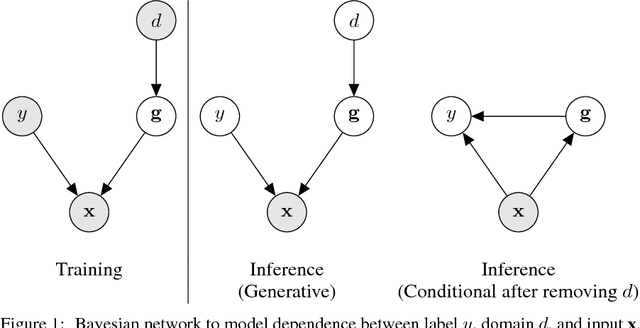
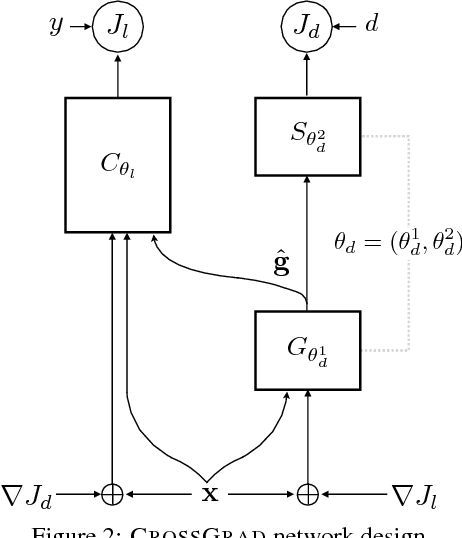

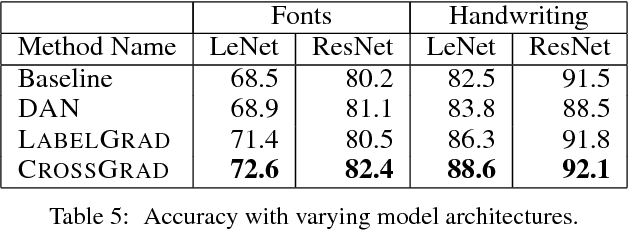
We present CROSSGRAD, a method to use multi-domain training data to learn a classifier that generalizes to new domains. CROSSGRAD does not need an adaptation phase via labeled or unlabeled data, or domain features in the new domain. Most existing domain adaptation methods attempt to erase domain signals using techniques like domain adversarial training. In contrast, CROSSGRAD is free to use domain signals for predicting labels, if it can prevent overfitting on training domains. We conceptualize the task in a Bayesian setting, in which a sampling step is implemented as data augmentation, based on domain-guided perturbations of input instances. CROSSGRAD parallelly trains a label and a domain classifier on examples perturbed by loss gradients of each other's objectives. This enables us to directly perturb inputs, without separating and re-mixing domain signals while making various distributional assumptions. Empirical evaluation on three different applications where this setting is natural establishes that (1) domain-guided perturbation provides consistently better generalization to unseen domains, compared to generic instance perturbation methods, and that (2) data augmentation is a more stable and accurate method than domain adversarial training.