 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Practical Consistency of Meta-Reinforcement Learning Algorithms
Dec 01, 2021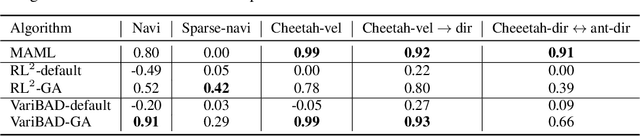
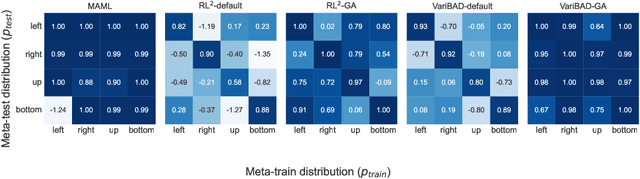
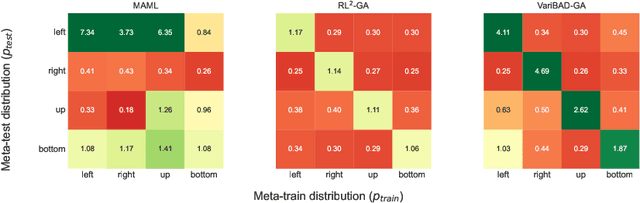

Consistency is the theoretical property of a meta learning algorithm that ensures that, under certain assumptions, it can adapt to any task at test time. An open question is whether and how theoretical consistency translates into practice, in comparison to inconsistent algorithms. In this paper, we empirically investigate this question on a set of representative meta-RL algorithms. We find that theoretically consistent algorithms can indeed usually adapt to out-of-distribution (OOD) tasks, while inconsistent ones cannot, although they can still fail in practice for reasons like poor exploration. We further find that theoretically inconsistent algorithms can be made consistent by continuing to update all agent components on the OOD tasks, and adapt as well or better than originally consistent ones. We conclude that theoretical consistency is indeed a desirable property, and inconsistent meta-RL algorithms can easily be made consistent to enjoy the same benefits.
Reinforcement Learning in Factored Action Spaces using Tensor Decompositions
Oct 27, 2021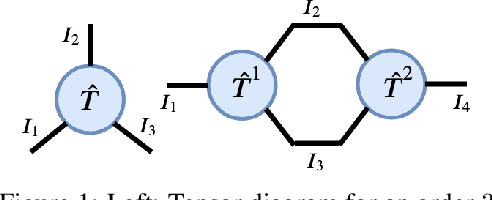
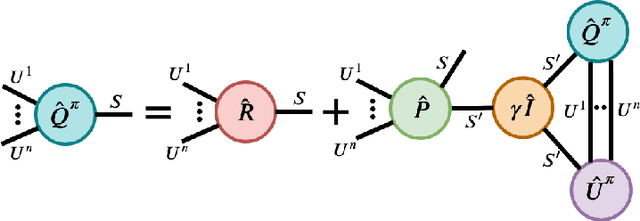
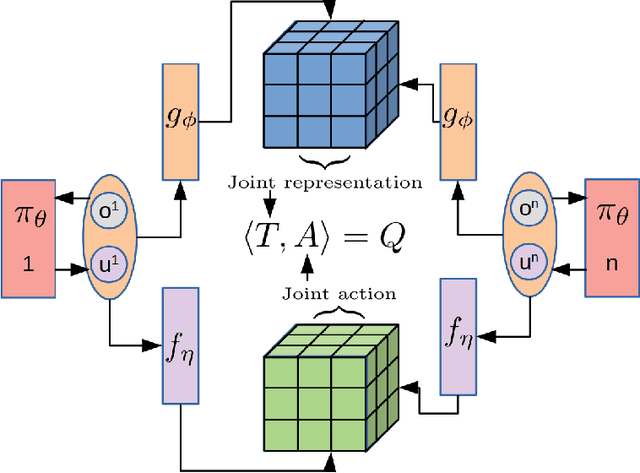
We present an extended abstract for the previously published work TESSERACT [Mahajan et al., 2021], which proposes a novel solution for Reinforcement Learning (RL) in large, factored action spaces using tensor decompositions. The goal of this abstract is twofold: (1) To garner greater interest amongst the tensor research community for creating methods and analysis for approximate RL, (2) To elucidate the generalised setting of factored action spaces where tensor decompositions can be used. We use cooperative multi-agent reinforcement learning scenario as the exemplary setting where the action space is naturally factored across agents and learning becomes intractable without resorting to approximation on the underlying hypothesis space for candidate solutions.
Model based Multi-agent Reinforcement Learning with Tensor Decompositions
Oct 27, 2021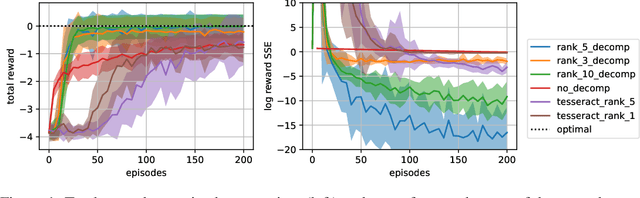
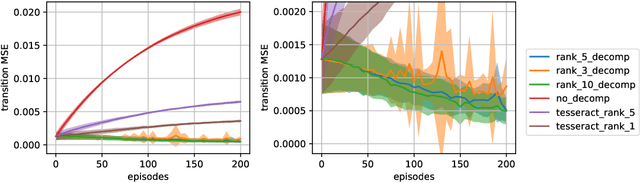
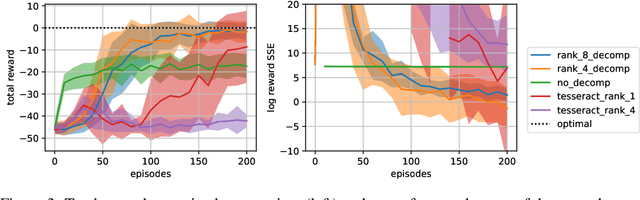
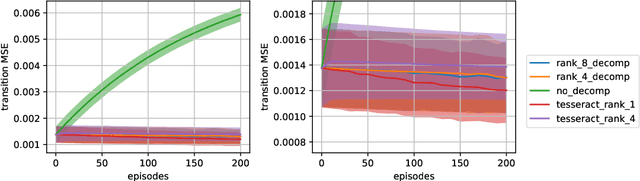
A challenge in multi-agent reinforcement learning is to be able to generalize over intractable state-action spaces. Inspired from Tesseract [Mahajan et al., 2021], this position paper investigates generalisation in state-action space over unexplored state-action pairs by modelling the transition and reward functions as tensors of low CP-rank. Initial experiments on synthetic MDPs show that using tensor decompositions in a model-based reinforcement learning algorithm can lead to much faster convergence if the true transition and reward functions are indeed of low rank.
Truncated Emphatic Temporal Difference Methods for Prediction and Control
Aug 11, 2021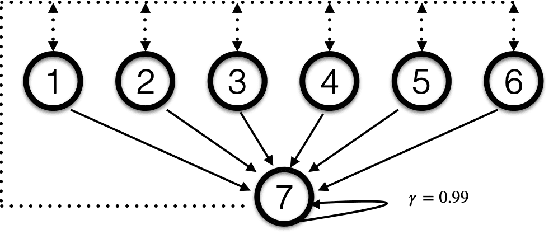

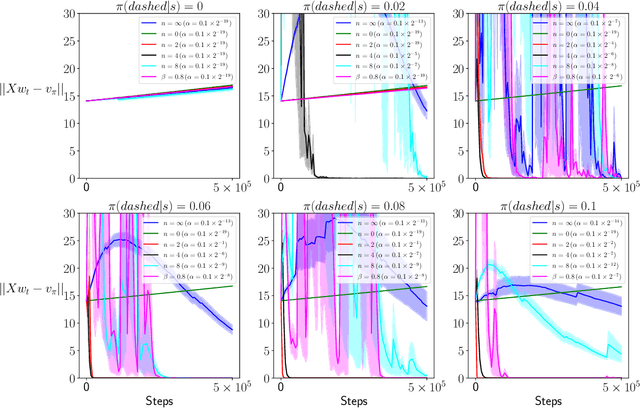
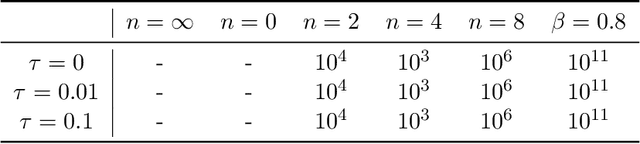
Emphatic Temporal Difference (TD) methods are a class of off-policy Reinforcement Learning (RL) methods involving the use of followon traces. Despite the theoretical success of emphatic TD methods in addressing the notorious deadly triad (Sutton and Barto, 2018) of off-policy RL, there are still three open problems. First, the motivation for emphatic TD methods proposed by Sutton et al. (2016) does not align with the convergence analysis of Yu (2015). Namely, a quantity used by Sutton et al. (2016) that is expected to be essential for the convergence of emphatic TD methods is not used in the actual convergence analysis of Yu (2015). Second, followon traces typically suffer from large variance, making them hard to use in practice. Third, despite the seminal work of Yu (2015) confirming the asymptotic convergence of some emphatic TD methods for prediction problems, there is still no finite sample analysis for any emphatic TD method for prediction, much less control. In this paper, we address those three open problems simultaneously via using truncated followon traces in emphatic TD methods. Unlike the original followon traces, which depend on all previous history, truncated followon traces depend on only finite history, reducing variance and enabling the finite sample analysis of our proposed emphatic TD methods for both prediction and control.
Implicit Communication as Minimum Entropy Coupling
Jul 17, 2021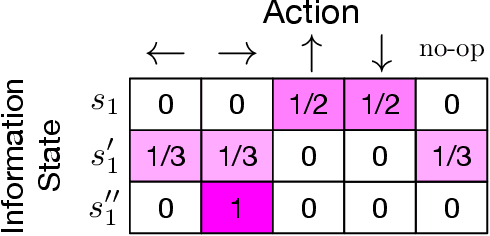
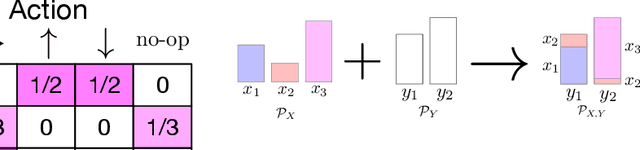

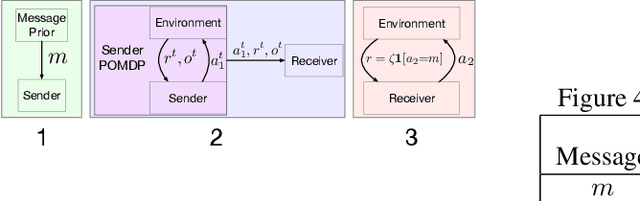
In many common-payoff games, achieving good performance requires players to develop protocols for communicating their private information implicitly -- i.e., using actions that have non-communicative effects on the environment. Multi-agent reinforcement learning practitioners typically approach this problem using independent learning methods in the hope that agents will learn implicit communication as a byproduct of expected return maximization. Unfortunately, independent learning methods are incapable of doing this in many settings. In this work, we isolate the implicit communication problem by identifying a class of partially observable common-payoff games, which we call implicit referential games, whose difficulty can be attributed to implicit communication. Next, we introduce a principled method based on minimum entropy coupling that leverages the structure of implicit referential games, yielding a new perspective on implicit communication. Lastly, we show that this method can discover performant implicit communication protocols in settings with very large spaces of messages.
Bayesian Bellman Operators
Jun 15, 2021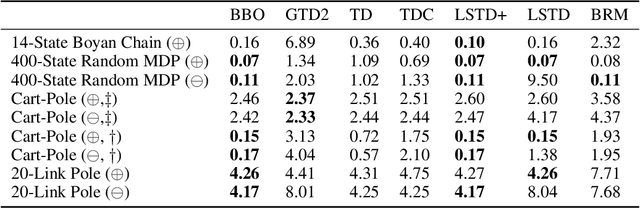
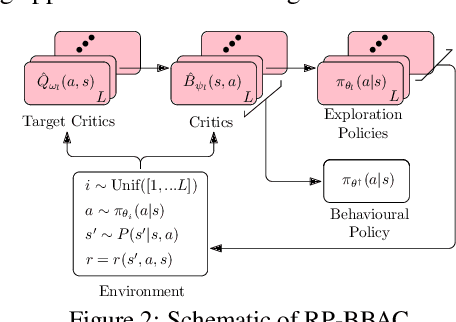
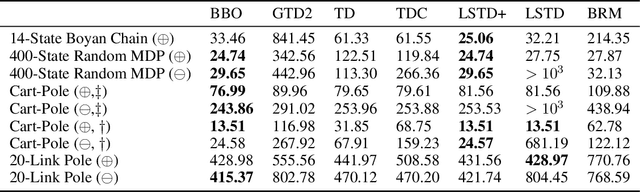
We introduce a novel perspective on Bayesian reinforcement learning (RL); whereas existing approaches infer a posterior over the transition distribution or Q-function, we characterise the uncertainty in the Bellman operator. Our Bayesian Bellman operator (BBO) framework is motivated by the insight that when bootstrapping is introduced, model-free approaches actually infer a posterior over Bellman operators, not value functions. In this paper, we use BBO to provide a rigorous theoretical analysis of model-free Bayesian RL to better understand its relationshipto established frequentist RL methodologies. We prove that Bayesian solutions are consistent with frequentist RL solutions, even when approximate inference isused, and derive conditions for which convergence properties hold. Empirically, we demonstrate that algorithms derived from the BBO framework have sophisticated deep exploration properties that enable them to solve continuous control tasks at which state-of-the-art regularised actor-critic algorithms fail catastrophically
SoftDICE for Imitation Learning: Rethinking Off-policy Distribution Matching
Jun 06, 2021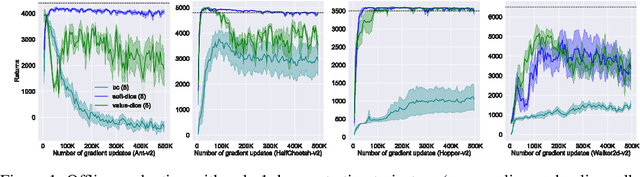
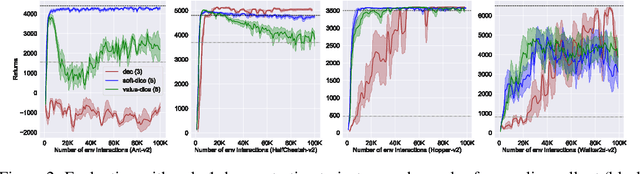
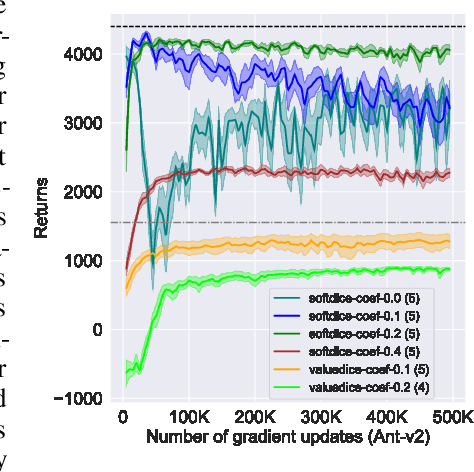
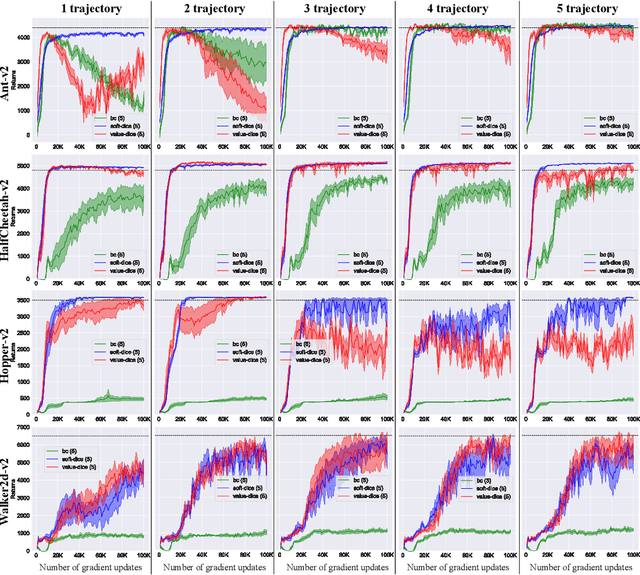
We present SoftDICE, which achieves state-of-the-art performance for imitation learning. SoftDICE fixes several key problems in ValueDICE, an off-policy distribution matching approach for sample-efficient imitation learning. Specifically, the objective of ValueDICE contains logarithms and exponentials of expectations, for which the mini-batch gradient estimate is always biased. Second, ValueDICE regularizes the objective with replay buffer samples when expert demonstrations are limited in number, which however changes the original distribution matching problem. Third, the re-parametrization trick used to derive the off-policy objective relies on an implicit assumption that rarely holds in training. We leverage a novel formulation of distribution matching and consider an entropy-regularized off-policy objective, which yields a completely offline algorithm called SoftDICE. Our empirical results show that SoftDICE recovers the expert policy with only one demonstration trajectory and no further on-policy/off-policy samples. SoftDICE also stably outperforms ValueDICE and other baselines in terms of sample efficiency on Mujoco benchmark tasks.
Tesseract: Tensorised Actors for Multi-Agent Reinforcement Learning
May 31, 2021
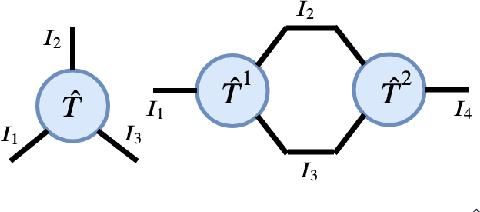
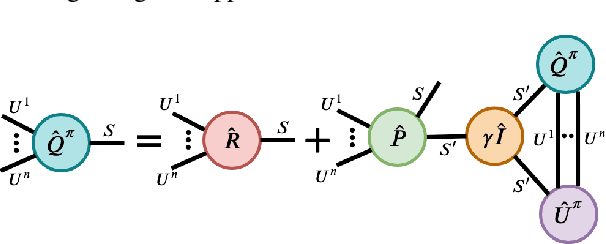
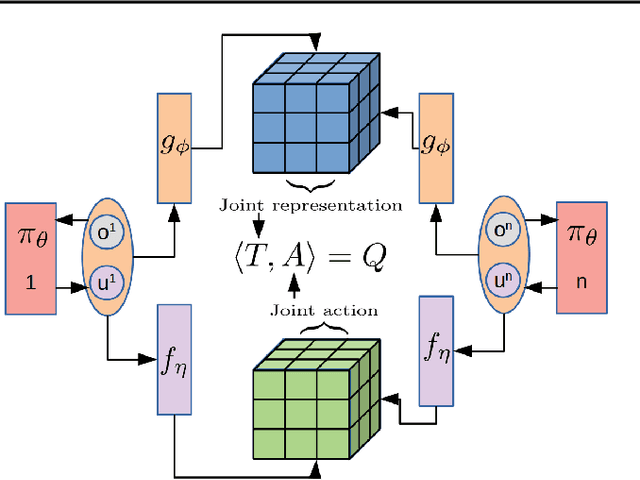
Reinforcement Learning in large action spaces is a challenging problem. Cooperative multi-agent reinforcement learning (MARL) exacerbates matters by imposing various constraints on communication and observability. In this work, we consider the fundamental hurdle affecting both value-based and policy-gradient approaches: an exponential blowup of the action space with the number of agents. For value-based methods, it poses challenges in accurately representing the optimal value function. For policy gradient methods, it makes training the critic difficult and exacerbates the problem of the lagging critic. We show that from a learning theory perspective, both problems can be addressed by accurately representing the associated action-value function with a low-complexity hypothesis class. This requires accurately modelling the agent interactions in a sample efficient way. To this end, we propose a novel tensorised formulation of the Bellman equation. This gives rise to our method Tesseract, which views the Q-function as a tensor whose modes correspond to the action spaces of different agents. Algorithms derived from Tesseract decompose the Q-tensor across agents and utilise low-rank tensor approximations to model agent interactions relevant to the task. We provide PAC analysis for Tesseract-based algorithms and highlight their relevance to the class of rich observation MDPs. Empirical results in different domains confirm Tesseract's gains in sample efficiency predicted by the theory.
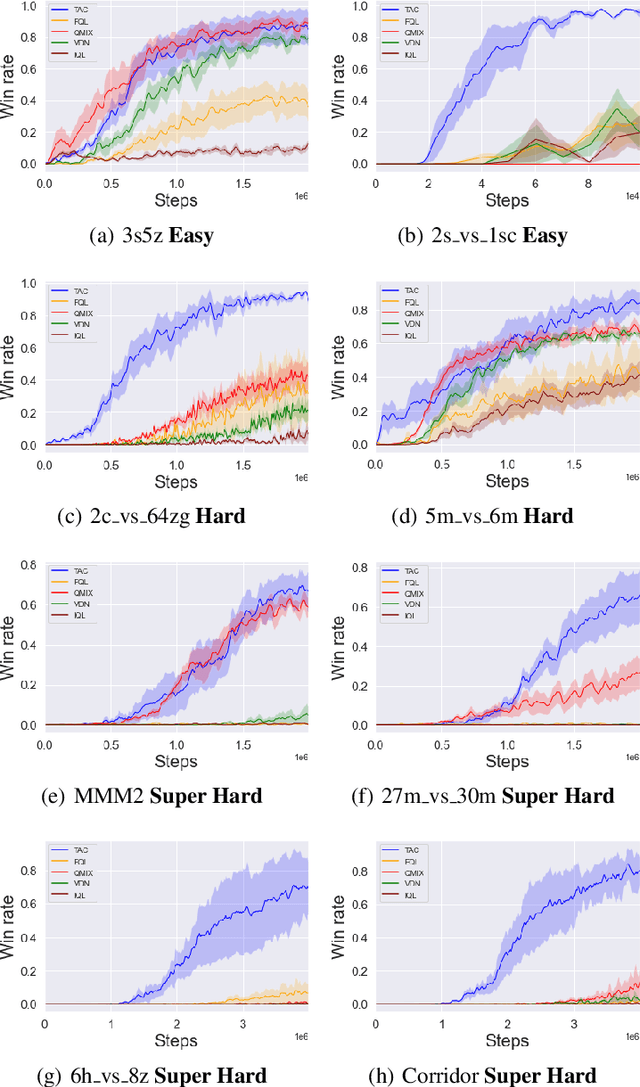
Semi-On-Policy Training for Sample Efficient Multi-Agent Policy Gradients
May 06, 2021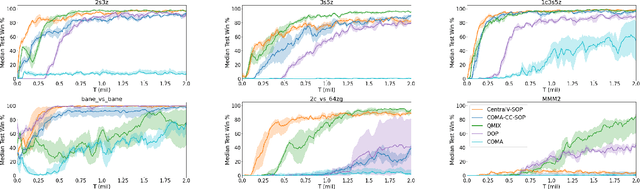
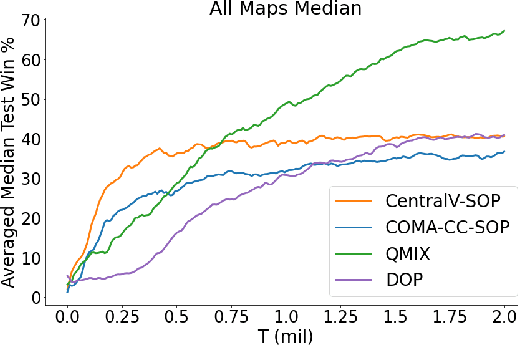
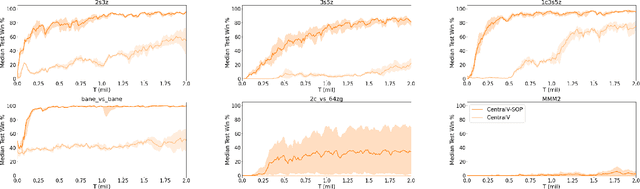
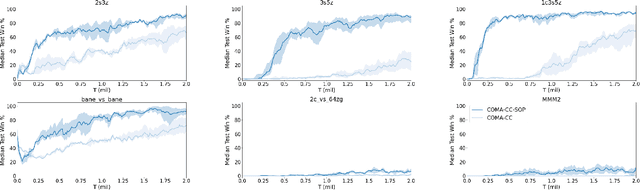
Policy gradient methods are an attractive approach to multi-agent reinforcement learning problems due to their convergence properties and robustness in partially observable scenarios. However, there is a significant performance gap between state-of-the-art policy gradient and value-based methods on the popular StarCraft Multi-Agent Challenge (SMAC) benchmark. In this paper, we introduce semi-on-policy (SOP) training as an effective and computationally efficient way to address the sample inefficiency of on-policy policy gradient methods. We enhance two state-of-the-art policy gradient algorithms with SOP training, demonstrating significant performance improvements. Furthermore, we show that our methods perform as well or better than state-of-the-art value-based methods on a variety of SMAC tasks.
Softmax with Regularization: Better Value Estimation in Multi-Agent Reinforcement Learning
Mar 22, 2021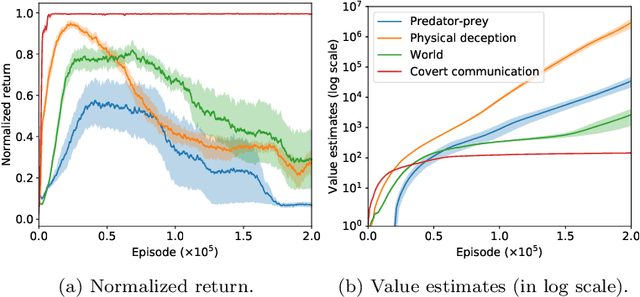
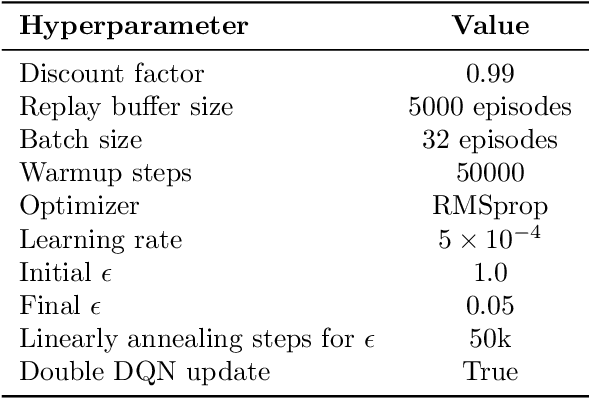
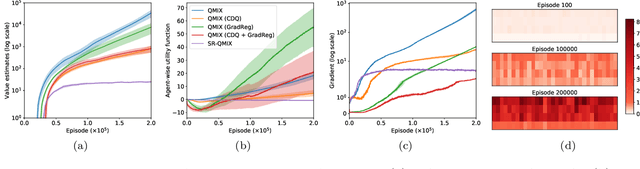

Overestimation in $Q$-learning is an important problem that has been extensively studied in single-agent reinforcement learning, but has received comparatively little attention in the multi-agent setting. In this work, we empirically demonstrate that QMIX, a popular $Q$-learning algorithm for cooperative multi-agent reinforcement learning (MARL), suffers from a particularly severe overestimation problem which is not mitigated by existing approaches. We rectify this by designing a novel regularization-based update scheme that penalizes large joint action-values deviating from a baseline and demonstrate its effectiveness in stabilizing learning. We additionally propose to employ a softmax operator, which we efficiently approximate in the multi-agent setting, to further reduce the potential overestimation bias. We demonstrate that our Softmax with Regularization (SR) method, when applied to QMIX, accomplishes its goal of avoiding severe overestimation and significantly improves performance in a variety of cooperative multi-agent tasks. To demonstrate the versatility of our method, we apply it to other $Q$-learning based MARL algorithms and achieve similar performance gains. Finally, we show that our method provides a consistent performance improvement on a set of challenging StarCraft II micromanagement tasks.