 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Max-Mahalanobis Classifiers for Image Classification, Generation and More
Jan 01, 2021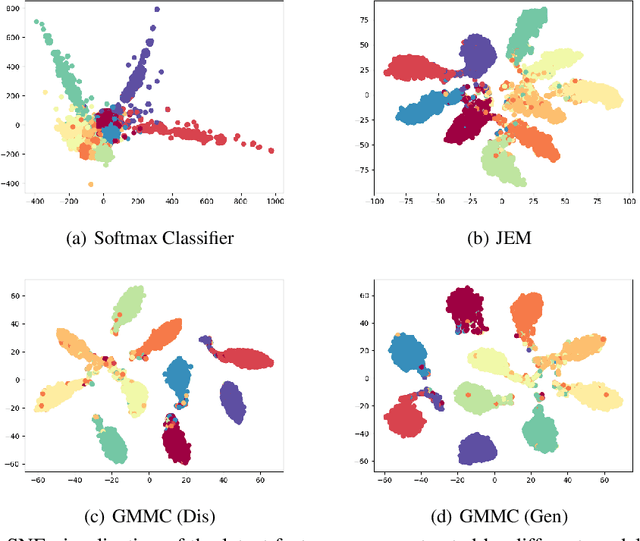
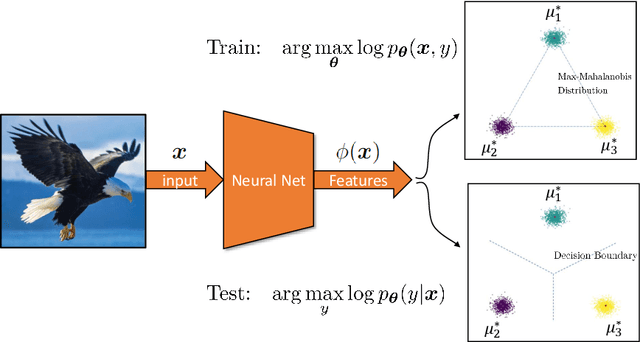

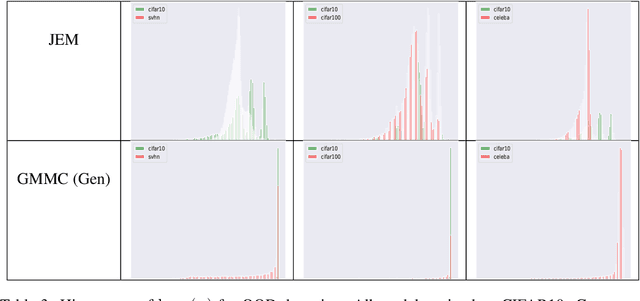
Joint Energy-based Model (JEM) of~\cite{jem} shows that a standard softmax classifier can be reinterpreted as an energy-based model (EBM) for the joint distribution $p(\boldsymbol{x}, y)$; the resulting model can be optimized with an energy-based training to improve calibration, robustness and out-of-distribution detection, while generating samples rivaling the quality of recent GAN-based approaches. However, the softmax classifier that JEM exploits is inherently discriminative and its latent feature space is not well formulated as probabilistic distributions, which may hinder its potential for image generation and incur training instability as observed in~\cite{jem}. We hypothesize that generative classifiers, such as Linear Discriminant Analysis (LDA), might be more suitable hybrid models for image generation since generative classifiers model the data generation process explicitly. This paper therefore investigates an LDA classifier for image classification and generation. In particular, the Max-Mahalanobis Classifier (MMC)~\cite{Pang2020Rethinking}, a special case of LDA, fits our goal very well since MMC formulates the latent feature space explicitly as the Max-Mahalanobis distribution~\cite{pang2018max}. We term our algorithm Generative MMC (GMMC), and show that it can be trained discriminatively, generatively or jointly for image classification and generation. Extensive experiments on multiple datasets (CIFAR10, CIFAR100 and SVHN) show that GMMC achieves state-of-the-art discriminative and generative performances, while outperforming JEM in calibration, adversarial robustness and out-of-distribution detection by a significant margin.
A Unified Plug-and-Play Framework for Effective Data Denoising and Robust Abstention
Sep 25, 2020
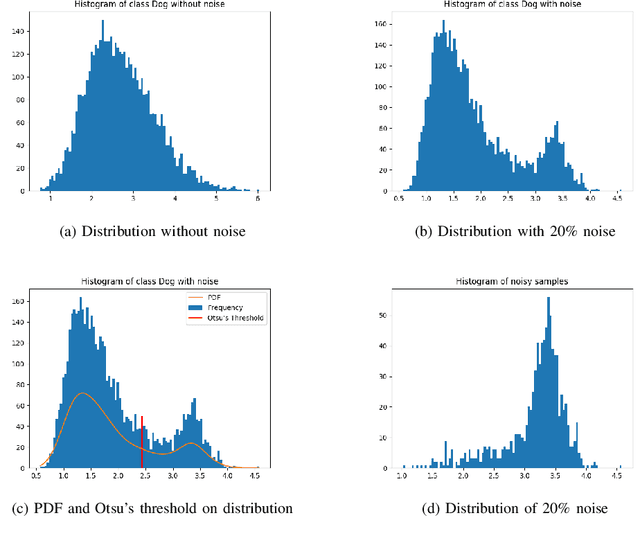
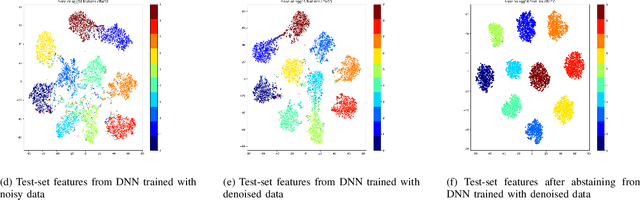

The success of Deep Neural Networks (DNNs) highly depends on data quality. Moreover, predictive uncertainty makes high performing DNNs risky for real-world deployment. In this paper, we aim to address these two issues by proposing a unified filtering framework leveraging underlying data density, that can effectively denoise training data as well as avoid predicting uncertain test data points. Our proposed framework leverages underlying data distribution to differentiate between noise and clean data samples without requiring any modification to existing DNN architectures or loss functions. Extensive experiments on multiple image classification datasets and multiple CNN architectures demonstrate that our simple yet effective framework can outperform the state-of-the-art techniques in denoising training data and abstaining uncertain test data.
Adversarial Privacy Preserving Graph Embedding against Inference Attack
Aug 30, 2020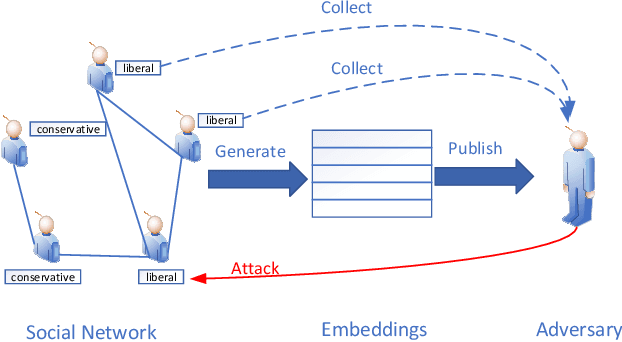
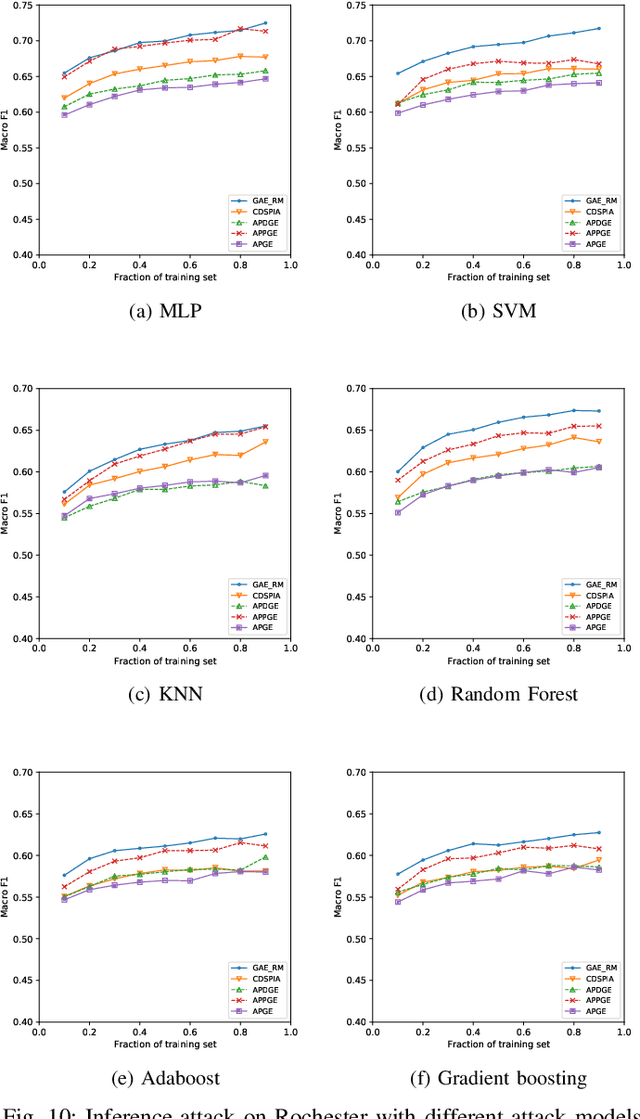
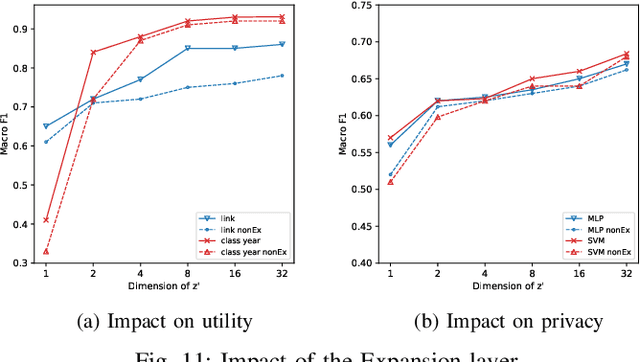
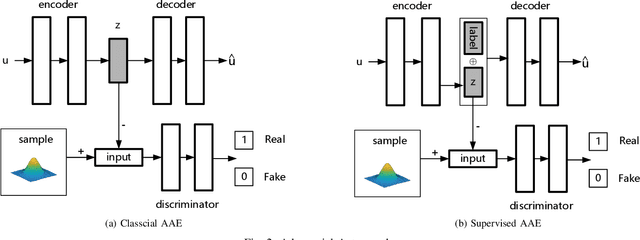
Recently, the surge in popularity of Internet of Things (IoT), mobile devices, social media, etc. has opened up a large source for graph data. Graph embedding has been proved extremely useful to learn low-dimensional feature representations from graph structured data. These feature representations can be used for a variety of prediction tasks from node classification to link prediction. However, existing graph embedding methods do not consider users' privacy to prevent inference attacks. That is, adversaries can infer users' sensitive information by analyzing node representations learned from graph embedding algorithms. In this paper, we propose Adversarial Privacy Graph Embedding (APGE), a graph adversarial training framework that integrates the disentangling and purging mechanisms to remove users' private information from learned node representations. The proposed method preserves the structural information and utility attributes of a graph while concealing users' private attributes from inference attacks. Extensive experiments on real-world graph datasets demonstrate the superior performance of APGE compared to the state-of-the-arts. Our source code can be found at https://github.com/uJ62JHD/Privacy-Preserving-Social-Network-Embedding.
Learning with Multiplicative Perturbations
Dec 04, 2019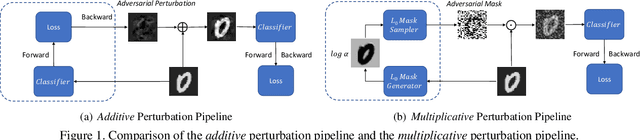
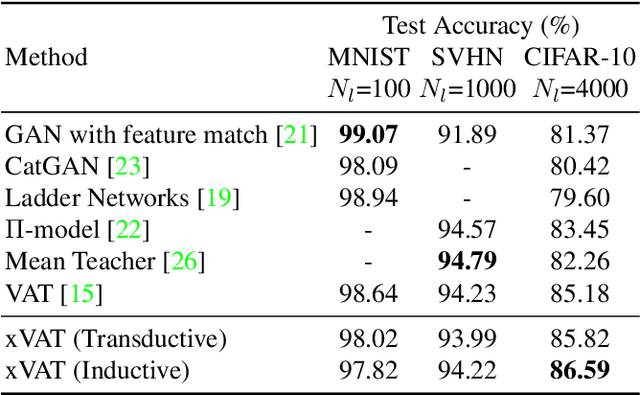
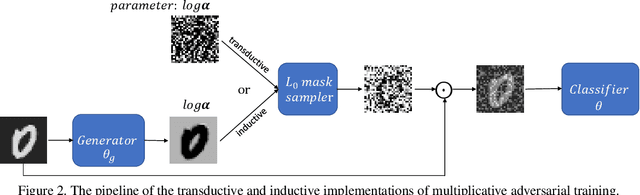
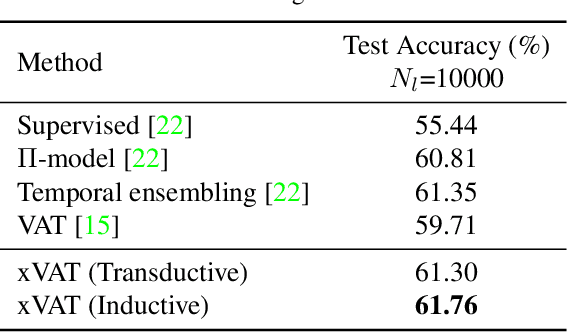
Adversarial Training (AT) and Virtual Adversarial Training (VAT) are the regularization techniques that train Deep Neural Networks (DNNs) with adversarial examples generated by adding small but worst-case perturbations to input examples. In this paper, we propose xAT and xVAT, new adversarial training algorithms, that generate \textbf{multiplicative} perturbations to input examples for robust training of DNNs. Such perturbations are much more perceptible and interpretable than their \textbf{additive} counterparts exploited by AT and VAT. Furthermore, the multiplicative perturbations can be generated transductively or inductively while the standard AT and VAT only support a transductive implementation. We conduct a series of experiments that analyze the behavior of the multiplicative perturbations and demonstrate that xAT and xVAT match or outperform state-of-the-art classification accuracies across multiple established benchmarks while being about 30\% faster than their additive counterparts. Furthermore, the resulting DNNs also demonstrate distinct weight distributions.
Sparse Graph Attention Networks
Dec 02, 2019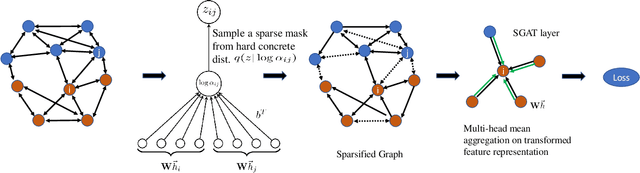
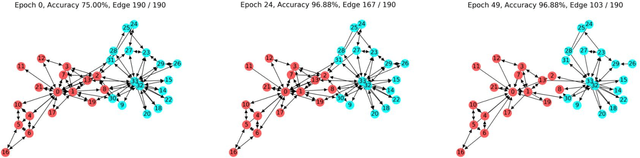
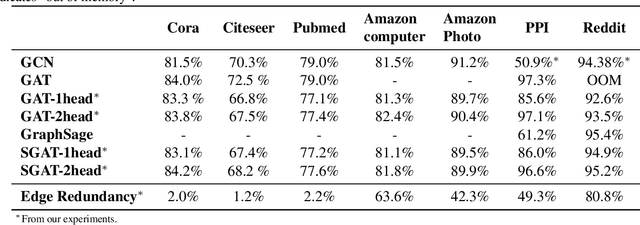
Graph Neural Networks (GNNs) have proved to be an effective representation learning framework for graph-structured data, and have achieved state-of-the-art performance on all sorts of practical tasks, such as node classification, link prediction and graph classification. Among the variants of GNNs, Graph Attention Networks (GATs) learn to assign dense attention coefficients over all neighbors of a node for feature aggregation, and improve the performance of many graph learning tasks. However, real-world graphs are often very large and noisy, and GATs are plagued to overfitting if not regularized properly. In this paper, we propose Sparse Graph Attention Networks (SGATs) that learn sparse attention coefficients under an $L_0$-norm regularization, and the learned sparse attentions are then used for all GNN layers, resulting in an edge-sparsified graph. By doing so, we can identify noisy / insignificant edges, and thus focus computation on more important portion of a graph. Extensive experiments on synthetic and real-world graph learning benchmarks demonstrate the superior performance of SGATs. In particular, SGATs can remove about 50\%-80\% edges from large graphs, such as PPI and Reddit, while retaining similar classification accuracies. Furthermore, the removed edges can be interpreted intuitively and quantitatively. To the best of our knowledge, this is the first graph learning algorithm that sparsifies graphs for the purpose of identifying important relationship between nodes and for robust training.
Toward Filament Segmentation Using Deep Neural Networks
Nov 20, 2019

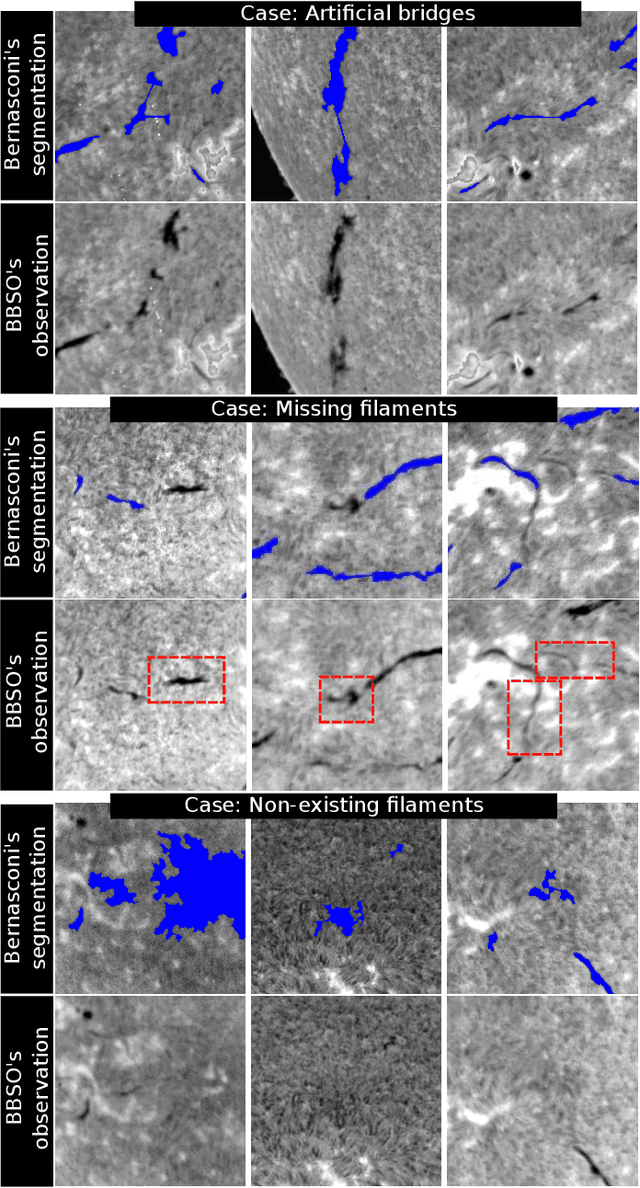
We use a well-known deep neural network framework, called Mask R-CNN, for identification of solar filaments in full-disk H-alpha images from Big Bear Solar Observatory (BBSO). The image data, collected from BBSO's archive, are integrated with the spatiotemporal metadata of filaments retrieved from the Heliophysics Events Knowledgebase (HEK) system. This integrated data is then treated as the ground-truth in the training process of the model. The available spatial metadata are the output of a currently running filament-detection module developed and maintained by the Feature Finding Team; an international consortium selected by NASA. Despite the known challenges in the identification and characterization of filaments by the existing module, which in turn are inherited into any other module that intends to learn from such outputs, Mask R-CNN shows promising results. Trained and validated on two years worth of BBSO data, this model is then tested on the three following years. Our case-by-case and overall analyses show that Mask R-CNN can clearly compete with the existing module and in some cases even perform better. Several cases of false positives and false negatives, that are correctly segmented by this model are also shown. The overall advantages of using the proposed model are two-fold: First, deep neural networks' performance generally improves as more annotated data, or better annotations are provided. Second, such a model can be scaled up to detect other solar events, as well as a single multi-purpose module. The results presented in this study introduce a proof of concept in benefits of employing deep neural networks for detection of solar events, and in particular, filaments.
Neural Plasticity Networks
Aug 13, 2019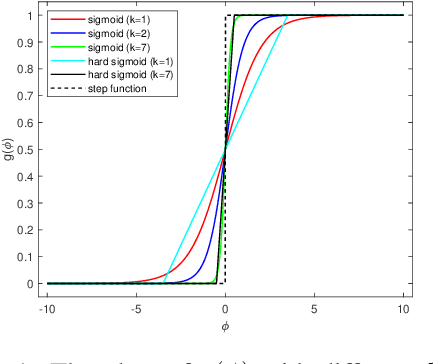
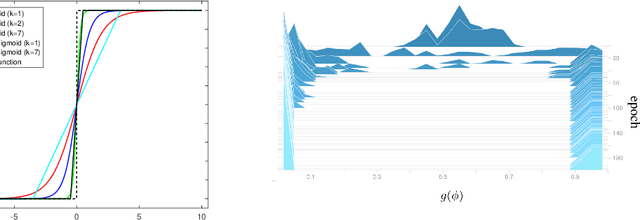
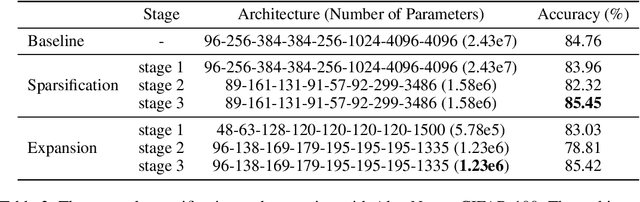
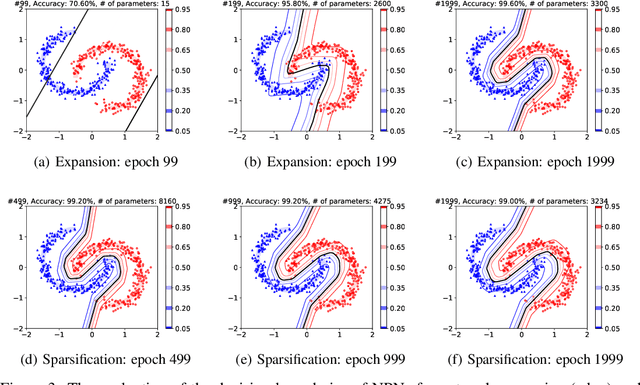
Neural plasticity is an important functionality of human brain, in which number of neurons and synapses can shrink or expand in response to stimuli throughout the span of life. We model this dynamic learning process as an $L_0$-norm regularized binary optimization problem, in which each unit of a neural network (e.g., weight, neuron or channel, etc.) is attached with a stochastic binary gate, whose parameters determine the level of activity of a unit in the network. At the beginning, only a small portion of binary gates (therefore the corresponding neurons) are activated, while the remaining neurons are in a hibernation mode. As the learning proceeds, some neurons might be activated or deactivated if doing so can be justified by the cost-benefit tradeoff measured by the $L_0$-norm regularized objective. As the training gets mature, the probability of transition between activation and deactivation will diminish until a final hardening stage. We demonstrate that all of these learning dynamics can be modulated by a single parameter $k$ seamlessly. Our neural plasticity network (NPN) can prune or expand a network depending on the initial capacity of network provided by the user; it also unifies dropout (when $k=0$), traditional training of DNNs (when $k=\infty$) and interpolates between these two. To the best of our knowledge, this is the first learning framework that unifies network sparsification and network expansion in an end-to-end training pipeline. Extensive experiments on synthetic dataset and multiple image classification benchmarks demonstrate the superior performance of NPN. We show that both network sparsification and network expansion can yield compact models of similar architectures and of similar predictive accuracies that are close to or sometimes even higher than baseline networks. We plan to release our code to facilitate the research in this area.
Neural Image Compression and Explanation
Aug 09, 2019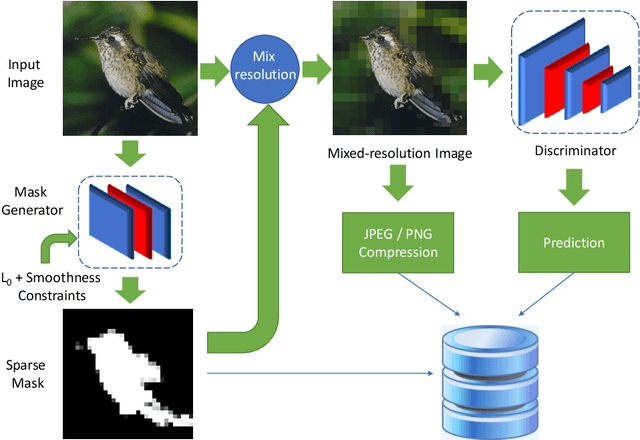


Explaining the prediction of deep neural networks (DNNs) and semantic image compression are two active research areas of deep learning with a numerous of applications in decision-critical systems, such as surveillance cameras, drones and self-driving cars, where interpretable decision is critical and storage/network bandwidth is limited. In this paper, we propose a novel end-to-end Neural Image Compression and Explanation (NICE) framework that learns to (1) explain the prediction of convolutional neural networks (CNNs), and (2) subsequently compress the input images for efficient storage or transmission. Specifically, NICE generates a sparse mask over an input image by attaching a stochastic binary gate to each pixel of the image, whose parameters are learned through the interaction with the CNN classifier to be explained. The generated mask is able to capture the saliency of each pixel measured by its influence to the final prediction of CNN; it can also be used to produce a mixed-resolution image, where important pixels maintain their original high resolution and insignificant background pixels are subsampled to a low resolution. The produced images achieve a high compression rate (e.g., about 0.6x of original image file size), while retaining a similar classification accuracy. Extensive experiments across multiple image classification benchmarks demonstrate the superior performance of NICE compared to the state-of-the-art methods in terms of explanation quality and image compression rate.
$L_0$-ARM: Network Sparsification via Stochastic Binary Optimization
Apr 09, 2019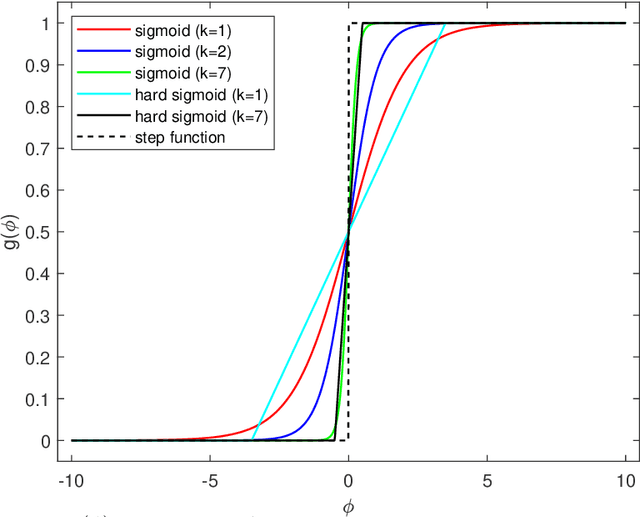

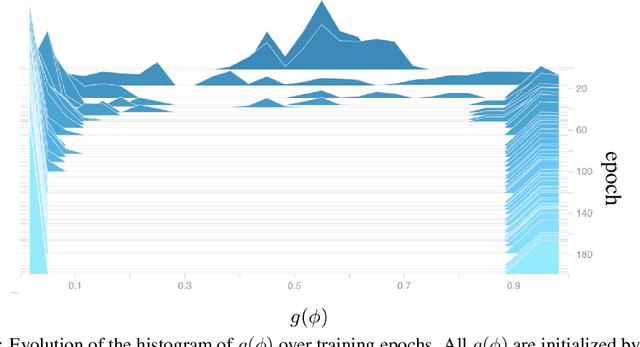
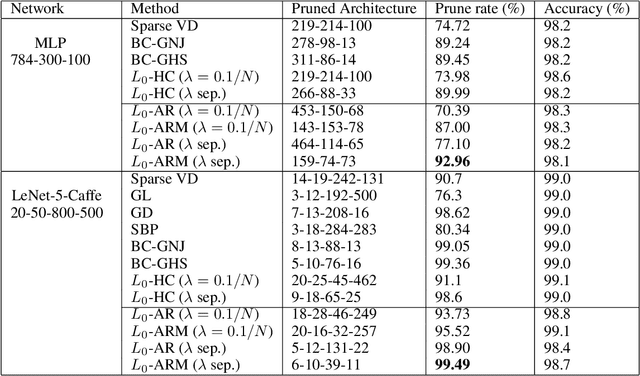
We consider network sparsification as an $L_0$-norm regularized binary optimization problem, where each unit of a neural network (e.g., weight, neuron, or channel, etc.) is attached with a stochastic binary gate, whose parameters are jointly optimized with original network parameters. The Augment-Reinforce-Merge (ARM), a recently proposed unbiased gradient estimator, is investigated for this binary optimization problem. Compared to the hard concrete gradient estimator from Louizos et al., ARM demonstrates superior performance of pruning network architectures while retaining almost the same accuracies of baseline methods. Similar to the hard concrete estimator, ARM also enables conditional computation during model training but with improved effectiveness due to the exact binary stochasticity. Thanks to the flexibility of ARM, many smooth or non-smooth parametric functions, such as scaled sigmoid or hard sigmoid, can be used to parameterize this binary optimization problem and the unbiasness of the ARM estimator is retained, while the hard concrete estimator has to rely on the hard sigmoid function to achieve conditional computation and thus accelerated training. Extensive experiments on multiple public datasets demonstrate state-of-the-art pruning rates with almost the same accuracies of baseline methods. The resulting algorithm $L_0$-ARM sparsifies the Wide-ResNet models on CIFAR-10 and CIFAR-100 while the hard concrete estimator cannot. We plan to release our code to facilitate the research in this area.
Defense-VAE: A Fast and Accurate Defense against Adversarial Attacks
Dec 17, 2018
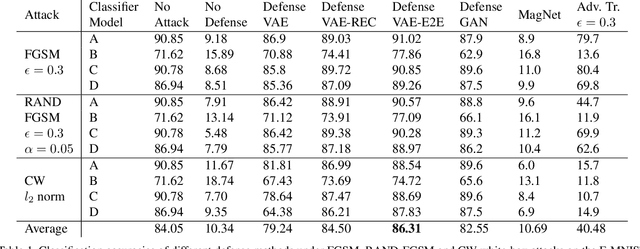
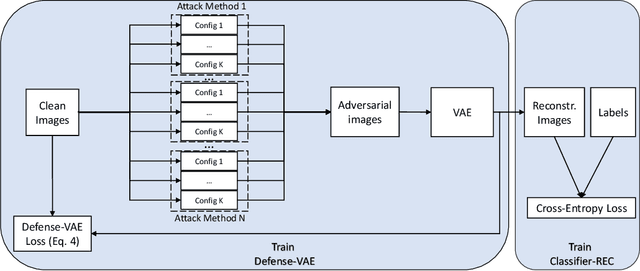
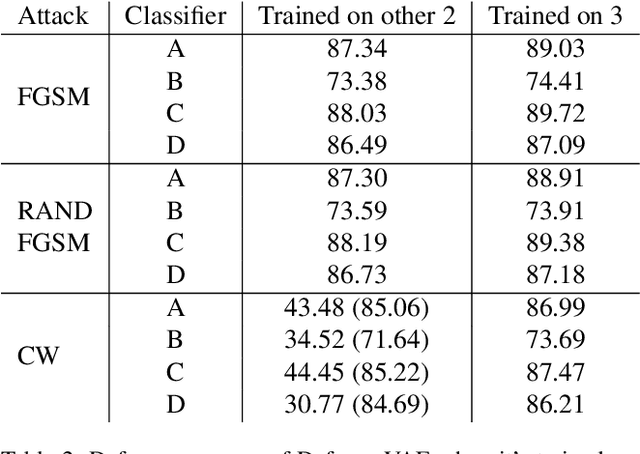
Deep neural networks (DNNs) have been enormously successful across a variety of prediction tasks. However, recent research shows that DNNs are particularly vulnerable to adversarial attacks, which poses a serous threat to their applications in security-sensitive systems. In this paper, we propose a simple yet effective defense algorithm Defense-VAE that uses variational autoencoder (VAE) to purge adversarial perturbations from contaminated images. The proposed method is generic and can defend white-box and black-box attacks without the need of retraining the original CNN classifiers, and can further strengthen the defense by retraining CNN or end-to-end finetuning the whole pipeline. In addition, the proposed method is very efficient compared to the optimization-based alternatives, such as Defense-GAN, since no iterative optimization is needed for online prediction. Extensive experiments on MNIST, Fashion-MNIST, CelebA and CIFAR-10 demonstrate the superior defense accuracy of Defense-VAE compared to Defense-GAN, while being 50x faster than the latter. This makes Defense-VAE widely deployable in real-time security-sensitive systems. We plan to open source our implementation to facilitate the research in this area.