 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Video Segmentation
Jun 17, 2026While video segmentation has advanced rapidly on short clips and closed-set benchmarks, open-world video segmentation remains largely unexplored. The challenge is twofold: (1) existing methods are not designed to support object discovery and identity maintenance in long videos of dynamic ego-motion, and (2) existing evaluation protocols rely on a rigid 1:1 matching that unfairly penalizes semantically valid predictions with mismatched granularity. To address both gaps, we introduce Savvy, a practical and strong system for zero-shot open-world long-horizon video segmentation. Savvy combines hierarchical mask discovery, deferred admission, and track consolidation to support persistent object discovery, safe track promotion, and stable long-range identity maintenance. We further propose OGA, a granularity-aware evaluation suite for open-world video segmentation. Built on a Granularity-Agnostic (GA) matching protocol, OGA relaxes conventional 1:1 matching to an n:1 mapping, but still enforces temporal rigor by detecting support discontinuities through sever points and scoring each reference object through its dominant coherent fragment. This prevents fragmented or flickering support from being over-rewarded while enabling GA-adapted metrics and structural diagnostics: identity persistence (IP), and identity concentration (IC). On VIPSeg, we show that standard 1:1 evaluation substantially underestimates open-world methods, whereas GA evaluation recovers much of their suppressed performance. On the more realistic long-horizon benchmarks: ScanNet and HM3D, Savvy consistently outperforms strong baselines across both classical and proposed metrics, including STQ, VPQ$_\infty$, IP and IC. Together, these results establish a practical benchmark and a strong baseline for open-world long-horizon video segmentation.
Bayesian Model Merging
May 13, 2026Model merging aims to combine multiple task-specific expert models into a single model without joint retraining, offering a practical alternative to multi-task learning when data access or computational budget is limited. Existing methods, however, face two key limitations: (1) they overlook the valuable inductive bias of strong anchor models and estimate the merged weights from scratch, and (2) they rely on a shared hyperparameter setting across different modules of the network, lacking a global optimization strategy. This paper introduces Bayesian Model Merging (BMM), a plug-and-play bi-level optimization framework, where the inner level formulates the model merging as an activation-based Bayesian regression under a strong prior induced by an anchor model, yielding an efficient closed-form solution; and the outer level leverages a Bayesian optimization procedure to search module-specific hyperparameters globally based on a small validation set. Furthermore, we reveal a key alignment between activation statistics and task vectors, enabling us to derive a data-free variant of BMM that estimates the Gram matrix for regression without any auxiliary data. Across extensive benchmarks, including up to 20-task merging in vision and 5-task merging in language, BMM consistently outperforms all plug-and-play anchor baselines (e.g., TA, WUDI-Merging, and TSV). In particular, on the ViT-L/14 benchmark for 8-task merging, a single merged model reaches 95.1, closely matching the average performance of eight task-specific experts (95.8).
PRBench: End-to-end Paper Reproduction in Physics Research
Mar 29, 2026AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
Approximate Subgraph Matching with Neural Graph Representations and Reinforcement Learning
Mar 18, 2026Approximate subgraph matching (ASM) is a task that determines the approximate presence of a given query graph in a large target graph. Being an NP-hard problem, ASM is critical in graph analysis with a myriad of applications ranging from database systems and network science to biochemistry and privacy. Existing techniques often employ heuristic search strategies, which cannot fully utilize the graph information, leading to sub-optimal solutions. This paper proposes a Reinforcement Learning based Approximate Subgraph Matching (RL-ASM) algorithm that exploits graph transformers to effectively extract graph representations and RL-based policies for ASM. Our model is built upon the branch-and-bound algorithm that selects one pair of nodes from the two input graphs at a time for potential matches. Instead of using heuristics, we exploit a Graph Transformer architecture to extract feature representations that encode the full graph information. To enhance the training of the RL policy, we use supervised signals to guide our agent in an imitation learning stage. Subsequently, the policy is fine-tuned with the Proximal Policy Optimization (PPO) that optimizes the accumulative long-term rewards over episodes. Extensive experiments on both synthetic and real-world datasets demonstrate that our RL-ASM outperforms existing methods in terms of effectiveness and efficiency. Our source code is available at https://github.com/KaiyangLi1992/RL-ASM.
Adversarial Privacy Preserving Graph Embedding against Inference Attack
Aug 30, 2020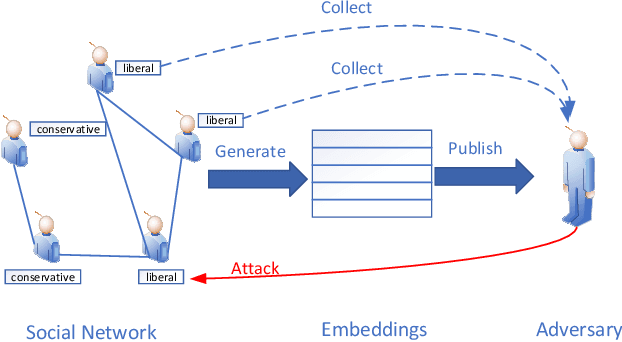
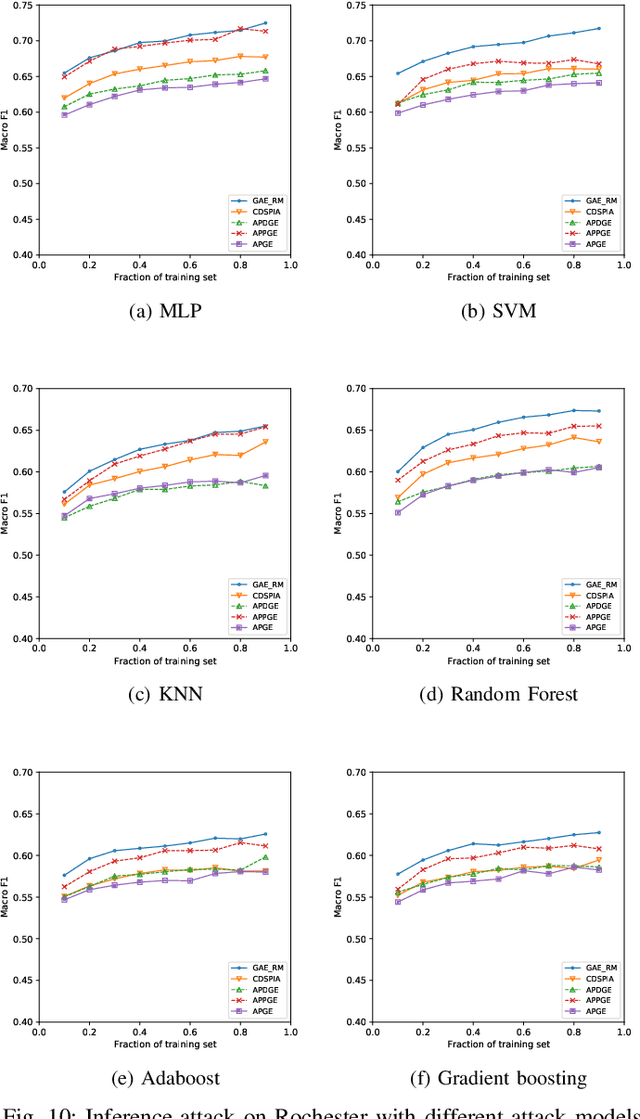
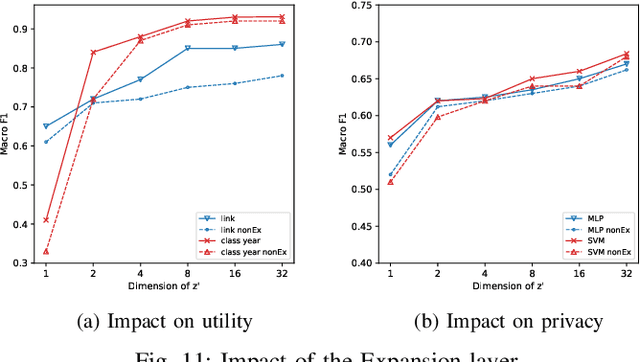
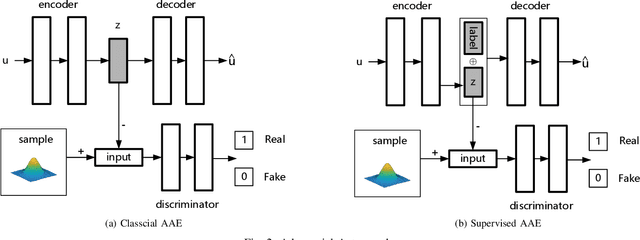
Recently, the surge in popularity of Internet of Things (IoT), mobile devices, social media, etc. has opened up a large source for graph data. Graph embedding has been proved extremely useful to learn low-dimensional feature representations from graph structured data. These feature representations can be used for a variety of prediction tasks from node classification to link prediction. However, existing graph embedding methods do not consider users' privacy to prevent inference attacks. That is, adversaries can infer users' sensitive information by analyzing node representations learned from graph embedding algorithms. In this paper, we propose Adversarial Privacy Graph Embedding (APGE), a graph adversarial training framework that integrates the disentangling and purging mechanisms to remove users' private information from learned node representations. The proposed method preserves the structural information and utility attributes of a graph while concealing users' private attributes from inference attacks. Extensive experiments on real-world graph datasets demonstrate the superior performance of APGE compared to the state-of-the-arts. Our source code can be found at https://github.com/uJ62JHD/Privacy-Preserving-Social-Network-Embedding.